Commons talk:Structured data/Archive 2019
 | This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
Notability discussion on Wikidata
People following the structured data project may be interested in this discussion that has kicked off on Wikidata:
A bot job started by User:Mike Peel has been stopped, that was creating Wikidata items for people with Commons categories that cannot be matched to Wikidata, on the grounds that such people may not necessarily be notable.
SDC of course would require such items to exist, for it to be possible to make statements about them. Items for every person or thing that currently has a Commons category would seem a bare minimum -- some visions for SDC envisage going much further, for example creating an individual Wikidata item for every single separate museum object that we currently have an image of.
Whatever the outcome, this is something we desperately need more clarity on, looking forwards; not least to plan around, in the event that such items on Wikidata would not exist. Do any of the SDC team have any thoughts, eg @SandraF (WMF): ? Jheald (talk) 12:49, 7 January 2019 (UTC)
- Jheald thanks for the link. --Jarekt (talk) 15:04, 7 January 2019 (UTC)
- The decisionmaking around this topic is fully up to the community... As a staff member, I want to make a point of not wanting to impose an opinion on this at all. With my volunteer hat on, I have no strong opinions either. If we create Wikidata items for everything, we must be able to properly maintain that huge mass of items too... I think less notable heritage objects can be modeled purely based on more generic statements (represents vase, with features blue paint / flowers/fishes... / designed by x / with inventory number nnn / in collection y) on Commons, and we can also decide to model less notable people in a similar, more generic way there. But I will happily follow the broader community's wishes if there is consensus about creating Wikidata items for everything. SandraF (WMF) (talk) 17:37, 7 January 2019 (UTC)
- @SandraF (WMF): I think less notable heritage objects can be modeled purely based on more generic statements [i.e. without their own items], and we can also decide to model less notable people in a similar, more generic way
- If you do believe this, I would like to see a fully worked-up example, to establish (i) how information about the underlying object, and its nature, creator, copyright status, licensing, history etc, would be kept distinct from information about its depiction/photograph; (ii) how this is possible when it is not possible to have qualifiers on qualifiers -- something the current Commons:Structured_data/Properties_table shows up as a major unresolved difficulty; (iii) how this would play alongside images where description in terms of wikidata items would be possible -- how great would the difficulties be that we would get into, if we would be trying to operate two quite different data models at the same time?
- Rather than just you saying that you think this can be done, if having to go down this road is even slightly conceivable as an outcome, I would like to see some hard modelling to show how it definitely can be done; and what the consequences would be. Because to date I'm not sure that the data designs so far presented would cut it. Jheald (talk) 18:23, 7 January 2019 (UTC)
- Yup. Whether one or the other solution is satisfactory is up to the community to reach consensus about! Deployment is around the corner, so the community can try this quite soon. Seeing the technology in front of one's eyes will certainly clarify things and cause more people to have strong opinions about this. SandraF (WMF) (talk) 09:03, 8 January 2019 (UTC)
Accounts on Beta Commons
- This section was archived on a request by: Keegan (WMF) (talk) 23:12, 26 February 2019 (UTC)
Trying to create an account on Beta Commons: is it possible that the error message "The passwords you entered do not match" arises when the actual problem is something else? I really doubt that four times in a row I couldn't match my password correctly, but four times in a row I got this same error. - Jmabel ! talk 09:59, 9 January 2019 (UTC)
- @Jmabel: It's most likely that you're trying to use your SUL account. The Beta Cluster does not operate at the high levels of security that we have for production, hence the message above the login form:
- This site (Beta Commons) allows WMF staff and community volunteers to test MediaWiki in a production like environment.
- Do NOT use your normal password, or any password you use anywhere else online.
- Did you already have a Beta Cluster account? If not, did you create one?
- Jdforrester (WMF) (talk) 15:38, 9 January 2019 (UTC)
- Again, as I wrote above, I was trying to create an account. It asks me to enter an account name, an email address, and enter a password twice. I got this error message after doing so, four times.
- Is it a problem that I used the same name as my account here? It shouldn't know whether the accounts have the same name. - Jmabel ! talk 18:24, 9 January 2019 (UTC)
- @Jmabel: Oh, sorry. No, it's not going to know about you having an account on this (other) system. I just created a test account there and it worked fine. Jdforrester (WMF) (talk) 18:43, 9 January 2019 (UTC)
- Jmabel, it used to be the case that MediaWiki on some non-production servers (like wikitechwiki) was not able to deal with passwords containing certain Unicode characters. Have you tried using an ASCII password, as silly as this might sound? Nemo 19:15, 10 January 2019 (UTC)
- Well, at this point the feature is live, so there's no point to my looking at the Beta. - Jmabel ! talk 00:43, 11 January 2019 (UTC)
- Jmabel, it used to be the case that MediaWiki on some non-production servers (like wikitechwiki) was not able to deal with passwords containing certain Unicode characters. Have you tried using an ASCII password, as silly as this might sound? Nemo 19:15, 10 January 2019 (UTC)
- @Jmabel: Oh, sorry. No, it's not going to know about you having an account on this (other) system. I just created a test account there and it worked fine. Jdforrester (WMF) (talk) 18:43, 9 January 2019 (UTC)
Accessing the captions via lua and pywikibot
@Keegan (WMF): (and others): are there ways to access the captions using Lua and pywikibot, or are they human-accessible only at the moment? Thanks. Mike Peel (talk) 16:45, 11 January 2019 (UTC)
- Humans-only for now, or read-only via API. This will change, I do not know when at the moment. Keegan (WMF) (talk) 18:43, 11 January 2019 (UTC)
- OK, thank you. If you can let me know when it is available then I can see if it can be integrated into the wikidata infobox to supplement the captions from Wikidata (and/or sync those over to here). Thanks. Mike Peel (talk) 19:54, 11 January 2019 (UTC)
To add a category just after a caption
This morning each time I tried to add a category after to have added (and after saving) a caption I got this message : File:Screenshot Editing File Ophiozonella nivea (YPM IZ 007648 EC) jpg - Wikimedia Commons.png. Christian Ferrer (talk) 07:49, 12 January 2019 (UTC)
- Hi, Yes, I already reported that: phab:T213462. Regards, Yann (talk) 08:49, 12 January 2019 (UTC)
Look and appearance of captions
Hi, it will be great the the file pages can keep a visual coherence.
- 1/ The title "Structured data" in a file page should be at the same sizes, and not bigger, than the other headers such as "Summary", Licensing", ect...
- 2/The size of the caption box on my screen (1920*1200) is a very little smaller than the {{Information}} and than the license template. It would be great that all boxes and templates be at the same size.
Regards, Christian Ferrer (talk) 12:59, 12 January 2019 (UTC)
- @Christian Ferrer: Hey there,
- The reason the MediaInfo section is under an H1 is because it's its own page component, at the same "level" as the wikitext block, which also has an H1 (the page's title). Right now the design is in flux, and I agree that it's a little confusing. In the future the design is going to change; the most recent design feedback session about this would mean that the H1 wouldn't appear, but instead the parts of the page would be split with tabs. That discussion is now closed, but I'd be interested to hear from you if that proposal would work for you.
- You are right, the text in the Information template is 5% smaller than in the rest of the page – it's set to 95% (=13.3pt) of the general page content size (=14pt) in the template by using the class
toccolours. I don't know why this was done, but it's been this was for a very long time, so I imagine a community discussion would be needed before changing the template. - Jdforrester (WMF) (talk) 21:26, 12 January 2019 (UTC)
- @Jdforrester (WMF): Thanks for the answer
- I've no special strong opinion about potential tabs, but I have not really though to that for now. I just think that if headers there are, in a file page (or in a specific tab), then all main headers should be at the same level.
- The size of the text was not my concern, I talked about the size (width) of the caption box compared to the width of {{Information}}, the width of caption box seems a little smaller
- After a night's sleep I woke up with the certainty that you should limit the display at one langage at one time. Me I have 3 lines, and this is really boring (and some users have more...) although one line is fully accepteble. Furthermore I don't plan to write any caption in Spain langage + I don' want to hide this caption box, and now the result is that it comes to mind to remove es-2 from my babel just to avoid those 3 boring lines....When I looked to a file page when I was not connected, I found the 1 line box much much better...
- Now that we have Commons:File captions, and in order to give infos to the visitors and editors, maybe that a link to that page should be given in the caption box, if not in the default display so then in the editing mode.
Christian Ferrer (talk) 05:26, 13 January 2019 (UTC)
Multilingual file captions coming this week
Hi all, following up on last month's announcement...
Multilingual file captions will be released this week, on either Wednesday, 9 January or Thursday, 10 January 2019. Captions are a feature to add short, translatable descriptions to files. Here's some links you might want to look follow before the release, if you haven't already:
- Read over the help page for using captions - I wrote the page on mediawiki.org because captions are available for any MediaWiki user, feel free to host/modify a copy of the page here on Commons.
- Test out using captions on Beta Commons.
- Leave feedback about the test on the captions test talk page, if you have anything you'd like to say prior to release.
Additionally, there will be an IRC office hour on Thursday, 10 January with the Structured Data team to talk about file captions, as well as anything else the community may be interested in. Date/time conversion, as well as a link to join, are on Meta.
Thanks for your time, I look forward to seeing those who can make it to the IRC office hour on Thursday. I'll add a reminder to this post once I confirm exactly what day captions will be turned on for Commons. Keegan (WMF) (talk) 01:06, 8 January 2019 (UTC)
- Apart from the (cumbersome and totally useless) language selection drop-down, which seems to have been already in use elsewhere, I cannot see anything new. So, descriptions can and should be added to Commons files — how’s that any different than previous practice? -- Tuválkin ✉ ✇ 14:54, 8 January 2019 (UTC)
- Could you please explain more on how you find using the translation feature cumbersome and useless? Do you find it easier or more difficult to add a language to a description template? You are certainly welcome to not use captions if you do not find the feature useful for your work, but if there's a way that it can be improved we'd like to hear about it. Additionally, if you could provide a link to this tool that seems to already exist elsewhere here, I'd appreciate it because I haven't seen it and I'd like to take a look. Keegan (WMF) (talk) 18:16, 8 January 2019 (UTC)
- @Keegan (WMF): To be clear,
- what I said is cumbersome and totally useless is the language selection drop-down, which seems to be the same exact element that shows up as a generic language-selection tool when one uses an WMF project while not logged in. I think it is cumbersome because it is made up mostly of empty space and the way languages are sorted (geographically, and ignoring the browser’s options on prefered languages?) makes it hard to find a language, not to mention the unintuitive way with scrolls and gains selection focus. I guess that you coopted this pre-existing element (which is of course good practice), but it is an essential part of the whole caprions feature. For me, the ideal language selector is a single, easily scrollable list of languages, properly sorted (the collation of which would be interesting to discuss, in terms of internationalized user expectations), whence to pick one out (one or several — Ctrl-click does work on some devices). That much for cumbersome. It is also useless because when a user is logged in there’s no need to present a complete list of languages. Even the most formidable polyglot will have to pick from a dozen or two; only in the unlikely situation one would be contributing in a language one’s not versed on such a general selection too wouled be needed — and for that a "more languages" button seem better than what we have now.
- I certainly do find it simplest to click to edit the file page’s wikicode and add
{{ab|Something here.}}(or{{ab|1= Something here.}}, if I’m feeling chatty) next to where it says|Description = }}— way simpler than going through UI hoops, but I understand that’s not what you’re after, especially since what I find simplest is already tried and tested and working for many years. But even if wikitext needs to be not offered, there’s Visual Editor apparently working in many projects; adding captions to be injected in a page seems to be the most basic of its functions.
- What I asked is what this new feature amounts to. We’ll have a pencil icon that brings up an already existing language-selection tool and thence we procede to a rich text entering box/screen whose working are new either? Is it the pencil icon that is new?, to be shown in file pages and interspesed in the upload wizzard? -- Tuválkin ✉ ✇ 22:36, 8 January 2019 (UTC)
- From a technical standpoint, captions are like labels on Wikidata. They will be searchable through the API, making it easy to find/filter/pull captions from files as metadata. There are a lot of possibilities of what this can be used for, from filling in infoboxes, building lists for translation of important files needing a caption localized for a project or campaign, searching for and finding captions, etc. So in comparison to description templates, while they potentially contain similar data to a caption, their function and reuse purposes are very different. Keegan (WMF) (talk) 19:57, 9 January 2019 (UTC)
- @Keegan (WMF): Understood, thanks. Maybe this field can/could be populated with the contents of the
|Description =field of {{Information}}, {{Artwork}}, and other such templates. -- Tuválkin ✉ ✇ 01:43, 10 January 2019 (UTC)
-
- If I understood it correctly, Tuvalkin meant an automatic action. The ideas behind structured data, semantic web and LOD are great, changes are good, but when I think of few thousands of my files on commons I would really love some bot. Especially, that descriptions are well structures in templates and mostly in size of captions. Nova (talk) 20:57, 10 January 2019 (UTC)
- I think a real bot would create to much trash, but a Tool like VisualFileChange would be great. --GPSLeo (talk) 21:03, 10 January 2019 (UTC)
- @Keegan (WMF): Understood, thanks. Maybe this field can/could be populated with the contents of the
- From a technical standpoint, captions are like labels on Wikidata. They will be searchable through the API, making it easy to find/filter/pull captions from files as metadata. There are a lot of possibilities of what this can be used for, from filling in infoboxes, building lists for translation of important files needing a caption localized for a project or campaign, searching for and finding captions, etc. So in comparison to description templates, while they potentially contain similar data to a caption, their function and reuse purposes are very different. Keegan (WMF) (talk) 19:57, 9 January 2019 (UTC)
Captions are live
Captions can now be added to files on Commons. There's a bug with abusefilter sending errors to new accounts adding captions, the bug is being investigated and fixed right now. IRC office hours will be in a little over one hour from now, I look forward to seeing you there if you can attend. Keegan (WMF) (talk) 16:50, 10 January 2019 (UTC)
- Is there a way to disable the box, or make it much less invasive? It's very annoying that it pushes the actual captions some half page down. Nemo 18:13, 10 January 2019 (UTC)
- @Nemo bis: Make this edit to your user css and it'll disable the captions. If @Keegan (WMF): or someone could add an ID to the css surround for it then we could attach some extra css tags to it to show/hide it, which would be better. Thanks. Mike Peel (talk) 19:36, 10 January 2019 (UTC)
- @Mike Peel: I'll make a Phabricator ticket later today to look into that. Keegan (WMF) (talk) 20:00, 10 January 2019 (UTC)
- Thanks for the css tip, looking forward the show/hide option. Nova (talk) 19:56, 10 January 2019 (UTC)
- Update: try this to also disable the "structured data" header. Thanks. Mike Peel (talk) 20:28, 10 January 2019 (UTC)
- Works better now, thanks. Nova (talk) 20:41, 10 January 2019 (UTC)
- Update: try this to also disable the "structured data" header. Thanks. Mike Peel (talk) 20:28, 10 January 2019 (UTC)
- It's easy indeed to hide the entire thing, but I'd just like it to still be there somewhere and not take one third of my screen or so. I suspect someone assumed that people don't care about existing descriptions being pushed out of the screen, or that nobody speaks more than 2 languages. Nemo 16:07, 11 January 2019 (UTC)
- @Nemo bis: Make this edit to your user css and it'll disable the captions. If @Keegan (WMF): or someone could add an ID to the css surround for it then we could attach some extra css tags to it to show/hide it, which would be better. Thanks. Mike Peel (talk) 19:36, 10 January 2019 (UTC)
- Hi, @Keegan (WMF): I see that a file ID, called "entity" is added as the first time a caption is created.
 Question is the IDs created only when we add a "structured data" for the first time, or will IDs will be created automatically for each existing files? Christian Ferrer (talk) 18:44, 10 January 2019 (UTC)
Question is the IDs created only when we add a "structured data" for the first time, or will IDs will be created automatically for each existing files? Christian Ferrer (talk) 18:44, 10 January 2019 (UTC)
- @Christian Ferrer: Hey, good spot. This is something we fixed in development yesterday, and will not be displayed from next week (the other issue is that it says "label" rather than "caption", which will also be fixed in the same change). Jdforrester (WMF) (talk) 18:49, 10 January 2019 (UTC)
- There is also some other things that I noticed.
There is not anymore rollback, but if I remember well we already talked about thatheu.. no, the rollback works well.... The second thing is : if you create a caption, then a ID is created, ok. If you revert then the ID is also removed. It's confirmed by the exact same number of bytes added and removed to the file. - Now if you delete all the captions without having reverted, then the captions are indeed removed, but the ID stay. It's also confirmed by the number of bytes. This is not really a question, just a thing that I noticed. Regards, Christian Ferrer (talk) 19:05, 10 January 2019 (UTC)
- @Christian Ferrer: Yeah, it's technically the marker for the entity ID. It's not relevant to users (they can't use it and they can't change it; it's just the reference for the database), so we won't be showing it (if you really need to know it, it appears on the
action=infopage). The "byte size" change is also not very helpful or accurate as that's a measure for the database which depends on the JSON serialisation of the entity model, but removing that from history pages would probably be disruptive for power users so we don't plan to do that right now. Jdforrester (WMF) (talk) 19:18, 10 January 2019 (UTC)
- @Christian Ferrer: Yeah, it's technically the marker for the entity ID. It's not relevant to users (they can't use it and they can't change it; it's just the reference for the database), so we won't be showing it (if you really need to know it, it appears on the
- There is also some other things that I noticed.
- @Christian Ferrer: Hey, good spot. This is something we fixed in development yesterday, and will not be displayed from next week (the other issue is that it says "label" rather than "caption", which will also be fixed in the same change). Jdforrester (WMF) (talk) 18:49, 10 January 2019 (UTC)
- Nice feature. It would probably be useful to write local file caption guidelines within Commons, in order to tell people which style is expected in the caption. mw:Help:File captions is a rather technical manual (no markup, how to undo, and so on), but things like capitalization, punctuation, preferable caption length and so on should probably also be advised to users… —MisterSynergy (talk) 19:44, 10 January 2019 (UTC)
- @Jdforrester (WMF): Note that the "Captions" features are available in the file redirect pages. What will be the impact if captions are added there? Christian Ferrer (talk) 21:04, 10 January 2019 (UTC)
- @Christian Ferrer: Another good spot. Captions on redirect pages aren't useful, and we will disable them, but it won't break anything. We've filed a Phabricator task to do this. Jdforrester (WMF) (talk) 21:07, 10 January 2019 (UTC)
- A lot of hits for abuse filter 58 (Removing information template) since activating the captions. I saw this filter hit live while my wife explained the UploadWizard to a new user. Raymond 21:58, 10 January 2019 (UTC)
- @Raymond: Yup, I'm fixing this right now. phab:T213453 for those that care. Jdforrester (WMF) (talk) 22:05, 10 January 2019 (UTC)
- @Raymond: Now fixed! Jdforrester (WMF) (talk) 01:12, 11 January 2019 (UTC)
- @Raymond: Yup, I'm fixing this right now. phab:T213453 for those that care. Jdforrester (WMF) (talk) 22:05, 10 January 2019 (UTC)
- Just whoa. You guys let this thing go live like this? With a layout that will immediately antagonize the exact kind of contributers who would be the most enthusiastic and productive about captions? A layout that hoggs whitespace (does it even look tighter in monobook, respecting its default margins and paddings?), a layout that puts this thing above all else on the page (above "Summary", srslsy?), under an H1 heading (whiskey tango foxtrot, aren’t you guys all about structure?!), with some wierd horizontally divided box which will mistify both oldschool HTML 1.0 veterans and swipe-swipe whipperspnappers (click on the pencil to edit the caption text under it across a line?; why not clicking the caption itself?, or put a proper button next to it!)…? After you’ve been working on this captions things since May last year, at least? Good grief, you’re supposed to be the code gods that are going to dig a ditch between yourselves and the computer illiterate masses, burying all the power users in it. Turns out part of that dire prediction isn’t true after all, but sadly that’s the part about code gods — for this gizmo seems utterly ungodly. And therefore I’m gonna sprinkle some CSS holy water on my ”skin” and forget I ever saw this thing live in production looking like this. -- Tuválkin ✉ ✇ 02:09, 11 January 2019 (UTC)
- And nobody thought of turning it off for file redirects oscar mike golf. -- Tuválkin ✉ ✇ 02:12, 11 January 2019 (UTC)
- This is really bad. Please turn it live only when at least Template:Artwork is correctly handled, either by using the wikidata element or the description field with language template. The feeling now is that all the hard work that was done to describe files is going to be lost. Léna (talk) 13:08, 11 January 2019 (UTC)
- Agree with some of the comments above. I thought the team had accepted and undertaken that structured data needed to be on a different tab to the regular file information, after this was flagged by multiple respondents in the Statements consultation (September-October 2018)
- As a result, in the "What's new" section of the "Statements 2" consultation (November 2018), User:Keegan (WMF) wrote:
- The tabs for Wikitext content and metadata (respectively called 'File information' and 'Structured data' for the purposes of this discussion) are now true tabs instead of anchor links, which should reduce/eliminate the occurrence of super long pages.
- Such tabbing is necessary, and should be implemented ASAP. The Structured Data is (or, we hope, will be) very important for machines. But it is important it should not get in the way of the templated information for humans. Jheald (talk) 14:27, 11 January 2019 (UTC)
- Jheald's last argument hits home. Nova (talk) 16:51, 11 January 2019 (UTC)
- In the statements consultation I was referring to the decision to put statements behind tabs. Captions were never planned to be hidden from users, but most of the rest of SDC will be behind a tab. I think the planned new box that gathers "use this file" and attribution generation is probably going in the whitespace that already exists and is unused to the right of files (as seen in the statements mockups), but as far as I know for now that's the only other visible thing. Keegan (WMF) (talk) 18:06, 11 January 2019 (UTC)
- I do see the problem in how the mockups are presented, though, by not showing the "File information" tab first. A side-by-side comparison that would have shown captions on the "main" file page, instead of them simply being absent from the statements mockup. I'll make sure to not repeat that mistake in the next feature design consultations. Keegan (WMF) (talk) 18:25, 11 January 2019 (UTC)
 Comment If you want to hide or collapse it, you can now do so using gadgets − see Commons:File_captions#How_can_I_mask_the_captions? for the instructions. Jean-Fred (talk) 21:18, 12 January 2019 (UTC)
Comment If you want to hide or collapse it, you can now do so using gadgets − see Commons:File_captions#How_can_I_mask_the_captions? for the instructions. Jean-Fred (talk) 21:18, 12 January 2019 (UTC)
- Thanks for that. Nova (talk) 10:44, 13 January 2019 (UTC)
Information template problem
- This section was archived on a request by: Keegan (WMF) (talk) 23:13, 26 February 2019 (UTC)
Hi, some of my yesterday uploads to which I've added caption in Polish (via the UploadWizard form) seem to have broken Information template appearance, as you can see in this file page. Deleting the captions didn't help. Nova (talk) 10:57, 13 January 2019 (UTC)
- Sorry, my mistake, noticed and fixed by Multichill [1], thanks. Nova (talk) 14:14, 13 January 2019 (UTC)
UploadWizard and captions
- This section was archived on a request by: Keegan (WMF) (talk) 23:14, 26 February 2019 (UTC)
Hi, I just wanted to follow the new idea and do my best with the new uploads - there are few issues from this exercise:
- current explanation in the form for the Caption is not enough - how it is different from Description? What IS most important and for whom? I seek for a link to a page with a good set of examples;
- the section Caption is translated into Polish as "Podpis", which is a bit confusing, as suggests more a "Signature";
- repetitiveness - first - Title, than - Caption, than - Description. All of them containing the same subset of information. In my case, with Description containing mostly one or two sentences (close to 255 characters), Caption could be the same (but two separate fields suggest that shouldn't?). Now I have to fill in 5 fields, if, as usual, two languages included; Some kind of auto-generated-pre-filled-suggestion-from-Description would be of much help;
- Caption is marked as Optional, but put above the required Description;
- There is no info that wiki markup should not be used in Captions and, as far as I've checked, it is not validated if it has been used, so published with the markup, than uninterpreted on the file page.
It rather stops from providing the Captions with upload at the current state. Nova (talk) 12:35, 13 January 2019 (UTC)
- Captions should probably be with the "other information" if anything. Nemo 15:23, 13 January 2019 (UTC)
- Thank you for the feedback, it's very helpful as the team looks at design changes. Keegan (WMF) (talk) 17:53, 14 January 2019 (UTC)
Captions updates to come
- This section was archived on a request by: Keegan (WMF) (talk) 23:14, 26 February 2019 (UTC)
The development team is putting together the plan for changes needed for captions, there are a few bugs and some design issues that showed up when captions went live on Commons (and thank you to all who have pointed them out onwiki and/or participated on Phabricator). I'll have a list to post later this week, along with information about how soon we can expect to see the changes. I'll be making the post here, with a note on the Village Pump. Keegan (WMF) (talk) 17:51, 14 January 2019 (UTC)
How to search SD?
When and how will WP search support the search in SD? My naive approach using incaption:value was not successful. I noticed that the search takes the captions into account and finds them [2], but there should be a way to search specifically for captions.
BTW, searching for the help text "Add a one-line explanation of what this file represents" should not find any matches: [3] --Herzi Pinki (talk) 17:17, 12 January 2019 (UTC)
- @Herzi Pinki: That's because you're using the wrong search engine; it's in this one. Jdforrester (WMF) (talk) 21:14, 12 January 2019 (UTC)
-
- filed a bug report for the BTW. --Herzi Pinki (talk) 21:53, 12 January 2019 (UTC)
You did not get me. I did not want to search the code. MediaWiki Search should support searching captions like titles. best --Herzi Pinki (talk) 22:02, 12 January 2019 (UTC)
- Search will be supported, it's not turned on yet. Keegan (WMF) (talk) 19:38, 14 January 2019 (UTC)
Can better sitelinks help with structuring data?
I've opened a proposal at Wikidata at "Wikidata:Wikidata:Requests for comment/Proposal to create a separate section for "Commonswiki" links" in relation to linking to galleries and categories on Wikimedia Commons, I also left a field there open for other ways how Wikidata could help Wikimedia Commons with its structure, will the structured data for Wikimedia Commons project be able to utilise such links or does this project exclusively work with the files and not the existing community-made infrastructure? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 15:59, 15 January 2019 (UTC)
Hashtags (#)
- This section was archived on a request by: Keegan (WMF) (talk) 23:14, 26 February 2019 (UTC)
A lot of image-sharing websites use hashtags (#) to clarify what is depicted in an image, is the concept of "depicts" going to be like this? Because I think that adding hashtags could very easily be a good search 🔎 tool, let's say you want to find an image with both "#Cats" and "#Birds" then a specific search could look for images where both of these hashtags are used. Sure vandals could wrongfully tag images with "#Hot sex" and "#Nude female human" and actual images that depict hot sex and nudes could be just as well be vandalised with "#Children". But from what I can tell "depicts" will be vulnerable to the same levels of vandalism. Hashtags could be listed below the categories on the bottom of an image, and being placed in a category could automatically add certain hashtags to an image, these "automatic hashtags" are then non-editable in the same way maintenance categories associated with certain license templates are. Is this idea viable or close to how "depicts" will work?
Because this is already how a lot of successful media-sharing websites do it. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:26, 15 January 2019 (UTC)
- Hashtags are not being implemented. Here's the last round of designs of what depicts will look like; it's very much about structuring data. Can someone add incorrect or malicious entries into structured data? Yes, but in no different way than the rest of the wiki functions. Structured data is fully integrated with recent changes and the revision deletion extension that controls page deletion, revision deletion, and suppression (aka oversight), as well as abuse filter. The development team plans on having depicts statements up for testing in a new test environment by the end of the month, so you'll be able to see it in action. Keegan (WMF) (talk) 22:17, 15 January 2019 (UTC)
Captions updates
Here's the list of work being done this development cycle to work on captions.
Done
These tasks have been complete and are either live on Commons now, or scheduled for deployment next week.
- Clicking 'Add a caption in another language' removes the input box for the previous caption
- Wikibase hijacks search autocomplete frontend entirely; we should configure it off
- AbuseFilter MCR diff is comparing old value of one slot with the new value from another, not the old whole page with the new whole page
- Edit summary for adding a caption uses “[1]” instead of language code
- Deleting a caption field that has text that exceeds the limit does not re-enable the "publish" button
- Don't allow structured data captions/statements on "File" pages which are just redirects
- 'Structured data' header does not appear before the captions if there are no captions for an image
- When pressing enter/return, file caption input text boxes should not add a newline
- Caption language selector shows interface language version of the language name on selection, but otherwise the native one
- Caption language name is displayed in page language, rather than as autonym, for filled-in captions
- Create a custom Wikibase diff view for WBMI so that we can suppress the "entity" line, and use a different description for "caption" instead of "label"
- File captions css issue in Commons using Modern skin
- Placeholder text prompt for a caption shouldn't be inserted into the search index
- Captions freezes when user injects illegal language codes that MediaWiki doesn't support
Doing
Works in progress, the fix being live on Commons is yet to be determined.
- Content isn't clear:both'ed on Files with no captions yet, because it's still wrapped in a mw:mediainfoView tags
- I see German captions on some but not all files with German captions
- Let file captions be edited on Mobile Frontend
- CSS classes should be prefixed
To do, but it's complicated
The underlying problem is going to take additional work.
Needs community fix
Captions introduced a bug into a Community-maintained gadget-space, unfortunately. The development team may able to advise volunteers on fixes where appropriate, but the team is unable to fix this themselves.
Needs community discussion
Two tasks can be implemented by the development team, but they require Commons community consensus to implement.
- Images (on articles, on file/category pages, and in the media viewer) should default to use their structured data caption as alt text when available
- Ignore babel box the user has set to knowing at level 0 on Commons (and so have different behaviour to Wikidata)
I'll post updates if/when I receive them. Keegan (WMF) (talk) 20:23, 18 January 2019 (UTC)
Can I switch this on and off?
- This section was archived on a request by: Keegan (WMF) (talk) 23:15, 26 February 2019 (UTC)
The table with an input possibility for structured data (image one-liners) now appears above the image discription. Is there a way to switch this on and off, or to relocate the table to a lower position on the file page? Elly (talk) 20:00, 19 January 2019 (UTC)
- @Ellywa: https://commons.wikimedia.org/wiki/Special:Preferences#mw-prefsection-gadgets, look for "captions", several choices there. - Jmabel ! talk 21:23, 19 January 2019 (UTC)
- @Jmabel: , thanks a lot! Elly (talk) 21:42, 19 January 2019 (UTC)
- (More documentations is at Commons:File captions. Jean-Fred (talk) 22:56, 19 January 2019 (UTC))
- @Jmabel: , thanks a lot! Elly (talk) 21:42, 19 January 2019 (UTC)
Copyright modeling on Wikidata

As I look into the future for our SDC feature releases, we have copyright and licensing statement support releasing in the next few months or so. It's probably a good time for interested Commons community members to start looking into how Wikidata setting up copyright modeling and ontology. Jarekt has started a help page for Copyright on Wikidata, and I encourage community members to have a look over and participate on the talk page if anything comes up that needs discussion. The development team doesn't hold a preference as to how modeling is implemented, but they would like see as much participation from Commons with Wikidata as possible before a final structure is released. Keegan (WMF) (talk) 20:58, 22 January 2019 (UTC)
- On that note d:Help:Copyrights at the moment covers Public Domain cases, but I do not think we figured out how to model copyrighted items, like files with {{Own}} and CC-BY license. We need more discussion on how to best do that. But lets keep the discussions on one place at d:Help talk:Copyrights. --Jarekt (talk) 21:16, 22 January 2019 (UTC)
- Took me a bit of digging, but look what I found. I think it can serve as a good starting point to improve on. I'll share it on the copyrights page too. Multichill (talk) 12:15, 26 January 2019 (UTC)
Are file captions also downloaded when someone downloads a file?
Are there also plans to let users download file captions as part of a file when they download it? Kind of like how Microsoft's Windows (Live) Photo Gallery allows users to add whole stories to pictures describing their content which is then saved as a part of the metadata. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 08:37, 26 January 2019 (UTC)
- Just to clarify: you would expect the captions to be downloaded as EXIF tag or a similar metadata format? Jean-Fred (talk) 10:58, 26 January 2019 (UTC)
- This would alter the SHA1 checksum for the file, a bad idea as that is the primary means of testing if uploads are identical duplicates. --Fæ (talk) 11:26, 26 January 2019 (UTC)
- Presumably, the SH1 used for that use case is calculated server-side, so before the on-the-fly addition of any metadata. Also, the current state is that license and author are already added to downloaded thumbs. Jean-Fred (talk) 11:50, 26 January 2019 (UTC)
- You may be conflating things. Thumbs display stuff on transclusion, which is not the same as downloading. You can download any thumb size you wish, but no extra metadata is added to it during the rendering process. Calculating SHA1 is the same whereever it is done. I use both the Commons API to return SHA1 values for hosted files, and I use standard Python hashlib to do the same to local files before an upload or after an upload. Other websites, like DVIDS, automatically edit EXIF data when they upload photographs to their website. It is an amazingly destructive thing to do, as it is then impossible to do any automatic, processing cheap, comparison to images which may be identical on other sites. In the DVIDs example, this means that Commons is plagued by duplicates of the same image from DVIDS, Flickr and specific military alternate sites where the EXIF is different in every location.
- Obviously, this is something that can be done, but there are big bad implications that mean it really should not be done. --Fæ (talk) 12:19, 26 January 2019 (UTC)
- “No extra metadata is added during the rendering process” → That certainly used to be the case (see eg phab:T44368) but indeed, does not appear to be current anymore − maybe something deprecated in the move to Thumbor (selected EXIF fields are still preserved in Thumbs though).
- I am aware of how file hashing works, and I appreciate the challenges you are facing when operating with third-party websites. I still fail to see how, were captions to be included in file downloads, this would interfere with the upload process. My understanding is that you avoid uploading duplicates by retrieving the SHA1 from the API (so before anything would be added), and compare it to your local files (which by definition, would not have captions added to them) − I don’t really understandand the usecase for downloading a file from Commons after the upload and then calculating its hash locally. Jean-Fred (talk) 13:14, 26 January 2019 (UTC)
- I feel odd now, it seems so obviously bad I thought it was intuitive. If we tamper with EXIF data based on volunteer added metadata, then there will be no easy way for other people to compare, say IA or Flickr files against the versions of the same files hosted on Commons. Even worse, people will download the file in 2019, and share it elsewhere, then in 2020, some well meaning volunteer will upload the same file from a collation site like Europeana, and because the caption has been altered over time, the API will fail to recognize it is a duplicate.
- The comparison of SHA1 values is the most fundamentally easy way to avoid duplicates. If we screw around with that simply because people quite like playing around with adding junk to EXIF data in vague non-standard ways, then pop, Commons pollutes its own future with random duplicates. --Fæ (talk) 13:24, 26 January 2019 (UTC)
- Presumably, the SH1 used for that use case is calculated server-side, so before the on-the-fly addition of any metadata. Also, the current state is that license and author are already added to downloaded thumbs. Jean-Fred (talk) 11:50, 26 January 2019 (UTC)
How to edit a caption
- This section was archived on a request by: Keegan (WMF) (talk) 23:15, 26 February 2019 (UTC)
Very elementary question. I wanted to edit the caption of one of my pictures but don't see how. There is no Wikidata item in the left-hand column. COM:Captions goes to Commons:Timed Text which is irrelevant. Help doesn't help me. So, where's the beginner's help? Jim.henderson (talk) 01:40, 25 January 2019 (UTC)
- Good question, I don't see any way to edit existing captions at present. --ghouston (talk) 01:54, 25 January 2019 (UTC)
_-_IRON_2_Cash,_Rev._Tong_%26_1._(S863)_-_Scott_Semans%27_(25_D._01_M._2019_A.).png)
- I can edit file captions, which is odd because as a mobile-only editor I'm usually excluded from editing functions. Do y'all see this screen or not? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 07:11, 25 January 2019 (UTC)
- Odd, a file like File:Kai Xi Tong Bao (開禧通寶) - IRON 2 Cash, Rev. Tong & 1. (S863) - Scott Semans.jpg has a caption that can be edited, but a file like File:Joseph_von_Fraunhofer,_engraving_by_Christian_Gottlob_Scherff.jpg has a caption that can't be edited. --ghouston (talk) 09:13, 25 January 2019 (UTC)
- Very odd indeed, I experience the exact same issue, now I'm curious what the differences are between these files, note that I added the caption on the Chinese cash coin using the MediaWiki Upload Wizard. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 09:29, 25 January 2019 (UTC)
- Odd, a file like File:Kai Xi Tong Bao (開禧通寶) - IRON 2 Cash, Rev. Tong & 1. (S863) - Scott Semans.jpg has a caption that can be edited, but a file like File:Joseph_von_Fraunhofer,_engraving_by_Christian_Gottlob_Scherff.jpg has a caption that can't be edited. --ghouston (talk) 09:13, 25 January 2019 (UTC)
- I can edit file captions, which is odd because as a mobile-only editor I'm usually excluded from editing functions. Do y'all see this screen or not? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 07:11, 25 January 2019 (UTC)
- @Jim.henderson, Ghouston, and Donald Trung: Sorry about this, there was a caching glitch caused by the roll-out of the software. It will automatically fix itself over time, or when the file's page is purged, or edited. Jdforrester (WMF) (talk) 16:02, 25 January 2019 (UTC)
- I encounter similar problem since 2-3 days on file pages - the H2 header of description section is not displayed. To edit the description I need to edit the whole page. The same on old and on new pages (File 1). When I add a caption and reload the page the section's heading appears (File 2). I've played around trying to make the header appear without adding a caption, but failed. I have the "collapse caption" gadget on, but switching it off doesn't help. Nova (talk) 19:18, 26 January 2019 (UTC)
- Works now, thanks. Nova (talk) 12:25, 27 January 2019 (UTC)
- I encounter similar problem since 2-3 days on file pages - the H2 header of description section is not displayed. To edit the description I need to edit the whole page. The same on old and on new pages (File 1). When I add a caption and reload the page the section's heading appears (File 2). I've played around trying to make the header appear without adding a caption, but failed. I have the "collapse caption" gadget on, but switching it off doesn't help. Nova (talk) 19:18, 26 January 2019 (UTC)
Structured data on Commons presentation reports
Heya,
I have created two reports from the presentations of this project to Wikimedia Commons contributors. Feel free to proofread them, move them, etc.:
Juandev (talk) 16:12, 28 January 2019 (UTC)
How would structured licensing look like for screenshots?
Hi! I recently took a look on how structured licensing statements will look like in the future. Commons:Screenshots is somewhat clear on what statements I should add to a file. One example is a file I uploaded is File:Paris wikipedia app android.jpg. Which licenses would show to the user? If I added Template:Free_screenshot/en, would wikidata show that information? Thanks! Tetizeraz. Send me a ✉️ ! 22:50, 3 February 2019 (UTC)
(Over)depictization
.jpg)
I'm a bit lost on what the current proposal is on how to use depicts. I found this feedback requests with it's talk page, but that's been inactive since October last year. Keegan: any pointers? I called this topic (Over)depictization because it relates to the topic of Over-categorization. Back in 2011 I wrote this proposal for next generation categories:
- Multiple languages - We're using Wikidata items so that's covered
- Enrich relations - On Wikidata we can link items together with all sorts of properties so that's covered
- Efficient intersections/searching - This topic is about this
Let's take the painting on the right as an example. It depicts Vincent van Gogh, but it also depicts a human, a man, a painter, etc. If you look at the category you'll find interesting categories like Category:Three-quarter view portrait paintings of men, facing left and Category:Men facing left in art. I think the first step is to break it up into atomic (as in, not intersected) items like "Three-quarter view portrait"(?), "men" and "facing left". These could be added to the item. But how to deal with implied properties? If it depicts Vincent van Gogh, it depicts a human and it depicts a man. If I search for "man", this image should be included somewhere. So we have two ends to that scale:
- Manually add implied depicts. We got complete overdepictization. This is a lot of user work. Imageinfo items will contain a pile of depicts statements. It does make search easier (from a technical perspective).
- Remove any implied depicts. We got no overdepictization. This saves the user a lot of work and it's the same concept of pushing files down the category tree. The number of depicts statements is limited. The big downside is the same as with the current category tree: It makes it harder to find things using search. The search engine should be improved to also include implied depicts statements. This isn't easy.
So the key to success here is the search engine. I already seen some chatter about implicit depicts and how difficult it is. The subclass tree on Wikidata will never be perfect. We can (and will) improve it, but we have to work with an imperfect model because we live in an imperfect world. Let's take that as a given (premise). Trying to make it perfect is like fighting windmills. So we should be able to adapt the search engine to use this imperfect data. We might notice that for certain domains going 8 levels up in the subclass tree is just fine, but for other domains it produces complete nonsense. We can't expect the WMF engineers to do this tweaking. From a technical perspective the search engine should be updated to include implicit depicts and what is included (or not) should be configurable here on Commons. That way the Commons community can tweak and improve the search results. I would imagine a user interface where you see the depicts properties and slightly greyed out the implicit depicts properties. I wonder what the plans are from the development team. Multichill (talk) 13:03, 26 January 2019 (UTC)
- Yeah. I mentioned in a previous discussion that in principle an image of a human should also be tagged with things like Homo sapiens, primate, mammal, animal, and organism, because there's no sense of inheritance in the proposed depicts setup. Of course it's unlikely that somebody tagging manually would remember to add all these extra topics, but a bot could easily do it. It gets a bit silly, but why would you stop somebody adding such topics, when they are correct and logically required? And then I suppose somebody will notice that searching for "animals at Guantanamo Bay" comes up with a result of human prisoners there and will make a big fuss about it. Ambiguity of language, what can you do? The other problem is that sometimes you have a large number of similar photos, perhaps all taken on the same day, all with the same topic. Currently you can group them in a category and categorise the whole lot at once, but with depicts, every individual image will be a search result of its own, potentially swamping any other images of the same topic. --ghouston (talk) 21:49, 26 January 2019 (UTC)
- The point in this case isn't about whether humans are animals or not, but where that relationship should be stored. If the search engine was traversing subclasses, then a search for animals would include humans (if the Wikidata subclassing was set up properly). With no traversal, "animal" needs to be added to each file individually. With the existing category system, we have Category:People which is ultimately a subcategory of Category:Animalia, but the system is quite erratic, since we also have Category:Animals with a whole category tree that apparently means "non-human animals", but it's nowhere stated as such. --ghouston (talk) 23:42, 26 January 2019 (UTC)
- I do not think we should tag painting of van Gogh with tags like "Homo sapiens, primate, mammal, animal, and organism", by hand or by bot. To many depict statements dilute their usefulness and we should only use the most specific term. If that hampers current search engine than we should concentrate on improving it. --Jarekt (talk) 18:05, 28 January 2019 (UTC)
- I hope very much.... otherwise the result of all this would have been the creation of a tag namespace... which is not necessarily bad but it was probably easier to get there... with the creation of such a namespace... :( Christian Ferrer (talk) 19:22, 28 January 2019 (UTC)
- We could add only the most relevant property, e.g., Vincent van Gogh and not Painter. But then that image won't turn up in any search for painters. We could add Carduelis carduelis to a picture of a goldfinch, but then it won't show up in a search for birds. --ghouston (talk) 21:56, 28 January 2019 (UTC)
- I hope very much.... otherwise the result of all this would have been the creation of a tag namespace... which is not necessarily bad but it was probably easier to get there... with the creation of such a namespace... :( Christian Ferrer (talk) 19:22, 28 January 2019 (UTC)
One way to deal with this is to just introduce more properties than depicted to describe item content, such as "painting format" to indicate if a painting is rectangular or oval or cathedral shaped, and whether the orientation is portrait/format. Another one could be "portrait style" for specifically portrait paintings, where you can indicate bust, half-length, three-quarter-length, seated, etc. Ñothing says we need to translate categories into the depicted statement. This is not a 1-1 relationship by any means. Jane023 (talk) 07:49, 30 January 2019 (UTC)
- The relevant thing to me is that if we introduce "shadow tags" in the search cache, or whatever we want to call them, they need to be tied to specific primary tags on the image. So that if somebody tags that an image depicts Van Gogh, with qualifiers that he is depicted in a particular part of the image, or in a particular pose, or wearing a particular hat, those qualifiers also need to be discoverable for a search run on the more generic topic.
- We also need to be able to search for a painting that depicts 4 humans, without getting confused as to how many humans there are in the picture if some but not others can be named. Similarly for a painting with 4 animals, if some are identified as lion and lioness but others are not. Jheald (talk) 18:32, 30 January 2019 (UTC)
- Does the depicts search engine optimisation (SEO) only concern Wikimedia search engines or also third party search engines (such as Ecosia, Microsoft Bing, Google, Baidu, Etc.) because if the former is true then we can always embed the file depicts to their subdepicts ans be able to filter out the specific dubdepicts. Let's say if you search "animal" all humans, cockatoos, and herrings get depicted but then you can filter out what animals you do and don't want to have, individual files in this case then would only need the most specific depict, let's say that Vincent van Gogh is a "Male Dutchman" which is a sub-category of "Dutchman" -> "Human" -> "Homo Sapiens Sapiens" -> "Homo" -> "Hominini" -> "Homininae" -> "Hominidae" -> "Simiiformes" -> "Haplorhini" -> "Haplorhini" -> "Primates" -> "Mammals" -> "Animals" -> "Filozoa" -> "Holozoa" -> "Opisthokonta" -> "Abazoa" -> "Unikonta" -> "Organism", listing each and every one of these would constitute overdepictisation but if only "Dutchman" or "Male Dutchman" (or more specific "Male Dutch painter from the 19th century") then a search for "Organism" would include this image as well as a search for "Mammals" as the depict-trees could just embed parent depict categories into child depicts. In fact I would probably state that for notable individuals such as Vincent van Gogh a "Vincent van Gogh" depict would be sufficient for listing all of his attributes such as "Male human", "Painter", "Person from the 19th century", "People born in Zundert", "People who died in Auvers-sur-Oise", Etc. And a search for each of these masterdepicts return these subdepicts, but not vice versa. This would optimise both specific and unspecific searches. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 08:52, 3 February 2019 (UTC)
@Multichill, Christian Ferrer, Ghouston, Jane023, and Donald Trung: sorry for the delay in response, I was offline last week. Search is going to be crucial, particularly granular search. The process of getting there is going to be granular as well, the release plan is going to take a "crawl, walk, run" approach and full-feature search is definitely running. Very tentatively for depicts, we're looking at releasing in the order of:
- Add/view/edit depicts on file pages
- Add/view/edit depicts in UploadWizard
- Search depicts statements
- Depicts qualifiers
- Filter search results
- Depicts of depicts
- Depicts and annotations
- Add/view/edit depicts in UploadWizard
So yes we are going to get to the place that's being suggested, the software will potentially largely be able to handle whatever the community throws at it to serve back to the user as appropriate. It's going to take steps, though, and ones that will be repeated to add other statement support after depicts support, to handle the use case that Jane023 suggested. Releases for depicts support are starting this month, we're sorting out when testing for the first stage will be available. I'll be advertising that everywhere as soon as I know. Keegan (WMF) (talk) 18:13, 4 February 2019 (UTC)
Caption - confusing behaviour
When I saw caption segment for the first time on Wikimedia Commons, I was confused by its behaviour. I would click into the field where "Add a one-line explanation of what this file represents" is written and start editing the caption in that proper language. It take me some time to find that pencial icon and figure out how it works. Would it be possible to open the input box just by clicking on the description (probably not I guess) or move that pencil icon down to that line or do something else with the design to be less confusing? Juandev (talk) 16:54, 4 February 2019 (UTC)
- Our designer may take another look at the pencil icon placement once the work around depicts and some other things finishes, it might not be ideal. It might take time to get back to it, though. Keegan (WMF) (talk) 18:20, 4 February 2019 (UTC)
Question, Why?
Sorry but you must be kidding. Why can't a bot copy the English description into your structured data field? Going back 10 years and changing these by hand is going to introduce errors that would be eliminated by a bot copy.
- "Summary" contains the field "Description English:" followed by a caption.
- "Structured data: Captions: English" is now a blank on all of my ~1500 past uploads.
You're going to have to give me a better rationale for taking the time to do this than I have seen so far. -SusanLesch (talk) 20:37, 22 January 2019 (UTC)
- @SusanLesch: captions comes with an API that lets the community build bots and tools to automatically or semi-automatically copy information into captions. As captions are brand new, and there are more features coming to structured data in the coming weeks and months, these tools haven't been written yet, but they can hopefully be expected in the near future. You don't need to fill in captions by hand if you choose not too, time is a limited resource. If you don't want to see captions on the file page until they can be filled in, or at least collapse the box, gadgets are available for this. Keegan (WMF) (talk) 22:01, 22 January 2019 (UTC)
- Thank you, Keegan (WMF). I don't mind the clutter as long as it has a purpose. -SusanLesch (talk) 22:06, 22 January 2019 (UTC)
It is worth observing that due to copyright issues, such as database rights, if the Caption is used as a CC0 database without mirroring the original image page license, then mass bot copying partial descriptions should be blocked or reverted. Without this we may well see later take down requests, as I have experienced with my own use of description texts during upload projects. Anyone thinking of writing a bot task, must have an associated community discussion and case review. --Fæ (talk) 12:49, 23 January 2019 (UTC)
- The solution is simple, add a standard message text that States "this file caption has been imported from the file description and falls under the Creative Commons Attribution-ShareAlike License; additional terms may apply." and don't use this tag for captions added using other methods or for captions added after a certain date, this should solve the copyright issues for re-users. But from what I've read Mike Peel wants to create an RfC about this so the copyright could be taken into account. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 12:55, 23 January 2019 (UTC)
- That really does not look like a solution, if captions are intended to be used as a database for reuse in other places. Neither does it solve issues such as texts taken from sources with other license restrictions like OGL or even text extracts from non-free/unclear sources where the image was taken as public domain. Once the caption becomes dislocated from the rest of the image page text, these complexities become active risks.
- I am also deeply concerned at seeing the much repeated myth that "facts" cannot be copyrighted. As an example "facts" like artist or creation date on historic artifacts are frequently subject to dispute and varied expert opinions and judgements. Mass processing this sort of text as if they can have no creativity or subjectivity is misleading and is likely to represent a copyright risk. The law in this area is highly varied between countries, please stop talking about copyright as if only the opinions of a few USA pundit lawyers matters. --Fæ (talk) 13:02, 23 January 2019 (UTC)
- I agree with Fæ, if the captions are CC0 than you can not have some messages stating otherwise. --Jarekt (talk) 14:34, 23 January 2019 (UTC)
The problem is that this feature is useless, as it duplicates an existing feature (namely, description tags). This will only serve to confuse readers as to why there are two different areas with potentially different captions. Either have one or the other—not both. — pythoncoder (talk | contribs) 13:18, 5 February 2019 (UTC)
Statusupdate
The "Latest updates" section is considerably outdated, so are some other sites. Could someone please update it? -- Michael F. Schönitzer 13:47, 6 February 2019 (UTC)
- I'm going to take a look at some updates to Latest, I've been waiting to see what information about depicts I can put in as soon as I know more about testing and release. Some of the older outdated pages, like Development, are likely to remain stale. Development plans have both moved too quickly and changed too much to keep that page updated in any meaningful way. I'll see what I can find. Keegan (WMF) (talk) 17:32, 6 February 2019 (UTC)
Do we want to bot-copy descriptions to captions?
I've posted a proposal about this at Commons:Village_pump/Proposals#Do_we_want_to_bot-copy_descriptions_to_captions? - comments appreciated! Thanks. Mike Peel (talk) 21:45, 8 February 2019 (UTC)
Copyright status of structured "items"
Are "Captions" and other SDC "items" released under the CC BY-SA 3.0 like the rest of Wikimedia Commons or under the CC0 license like Wikidata? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 23:42, 11 January 2019 (UTC)
- My guess is that free text captions are CC BY-SA 3.0, like the rest of the page. However most of the properties will be de-facto ineligible for copyright so for all practical reasons CC0. --Jarekt (talk) 03:43, 12 January 2019 (UTC)
- There's a phabricator ticket that's been asking this question since 2017, but with no meaningful input yet.
- With the captions that are live right now, it's something that needs to be clarified urgently. @Keegan (WMF): ?
- Since the whole page is licensed CC BY-SA 3.0, and there is nothing to indicate anything different for the captions, I think that means that any caption being added by a user at the moment has to be considered to be CC BY-SA 3.0. I think the contributor would be entitled to assume that that is the license under which they have made the caption string available, given that there is nothing else anywhere indicating anything other than this. This needs to be addressed quickly if the ultimate intention is to release the data CC0, because otherwise there will a considerable set of CC BY-SA 3.0 captions building up, that would have to be cleared to the more permissive release.
- A relevant question, if SDC is intended to be CC0 (and at the moment we have had no clear indication either way), is what restrictions this would place on data being harvested from existing CC BY-SA 3.0 file pages. Even if reporting that the creator of a painting was Leonardo da Vinci may be an uncopyrightable fact, extracting such information at scale may fall subject to database rights that might be only available BY-SA. Other information, eg saying that a painting was "probably painted c.1530" or was considered to be by "a follower of Raphael", may reflect real intellectual choices that could attract copyright in their own right, particularly if a substantial number were taken. This is a question that needs clarification, before substantial data transfer starts from Commons templates. Jheald (talk) 11:38, 12 January 2019 (UTC)
- Jheald, I disagree with legal theory that metadata, listing basic facts about someone or something can produce its own copyrights. You are not making artistic choices here and merely reporting information you found in the references. Otherwise you are doing something wrong. That is why it is OK to copy such information from Wikipedias or Commons to Wikidata. However, I agree that this should be clarified sooner than later. My vote would be to store most or all of Structured data under CC0 license so it is compatible with Wikidata. @Keegan (WMF): , I think this is important, especially since Commons is a project which is obsessed with getting copyrights right. We might need to discuss it as a project, but I also think WMF lawyers should look into it as well, especially if we start reusing the data and combining it with wikidata. --Jarekt (talk) 04:01, 13 January 2019 (UTC)
- It would probably be wise to simply add the text "by publishing this you agree that you release this caption with the CC0 license" but it might confuse people into thinking that this applies to all texts or something. Maybe one of the developers should open a proposal at "Commons:Village pump/Proposals" and ask for community feedback in how to clarify this without being "too intrusive". But a simple indication that all Structured Data on Wikimedia Commons "Items" are CC0 would suffice in the beginning of the process. Let's not forget that this is (legally) important for the re-users outside of Wikimedia websites as they're the people this whole system is built for. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 10:52, 13 January 2019 (UTC)
- I'm seeing where we are on all this. Keegan (WMF) (talk) 19:56, 14 January 2019 (UTC)
- It would probably be wise to simply add the text "by publishing this you agree that you release this caption with the CC0 license" but it might confuse people into thinking that this applies to all texts or something. Maybe one of the developers should open a proposal at "Commons:Village pump/Proposals" and ask for community feedback in how to clarify this without being "too intrusive". But a simple indication that all Structured Data on Wikimedia Commons "Items" are CC0 would suffice in the beginning of the process. Let's not forget that this is (legally) important for the re-users outside of Wikimedia websites as they're the people this whole system is built for. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 10:52, 13 January 2019 (UTC)
- Jheald, I disagree with legal theory that metadata, listing basic facts about someone or something can produce its own copyrights. You are not making artistic choices here and merely reporting information you found in the references. Otherwise you are doing something wrong. That is why it is OK to copy such information from Wikipedias or Commons to Wikidata. However, I agree that this should be clarified sooner than later. My vote would be to store most or all of Structured data under CC0 license so it is compatible with Wikidata. @Keegan (WMF): , I think this is important, especially since Commons is a project which is obsessed with getting copyrights right. We might need to discuss it as a project, but I also think WMF lawyers should look into it as well, especially if we start reusing the data and combining it with wikidata. --Jarekt (talk) 04:01, 13 January 2019 (UTC)
@Donald Trung, Jheald, and Jarekt: We are planning to ask users to release items on Structured Data on Commons under CC0, and we are working with the legal team to add the right license-related language. Full text pages on Wikimedia Commons may still be under CC BY-SA.
A relevant question, if SDC is intended to be CC0 (and at the moment we have had no clear indication either way), is what restrictions this would place on data being harvested from existing CC BY-SA 3.0 file pages.
The text on Commons is CC BY-SA currently, to the extent it's protected by copyright. However, most captions are not likely to be copyrightable, since they are short and factual. Copyright protects creative works of expression, and not the underlying ideas. It's possible that there will be some descriptions that are so idiosyncratic to get Copyright protection, and Commons has a couple of options if that comes up: 1) argue that they are not copyrightable, 2) just remove those captions and write a better, CC0 caption. Either choice would be guided by how the Commons community would like to settle it on Commons:File captions. Keegan (WMF) (talk) 22:08, 15 January 2019 (UTC)
- @Keegan (WMF): "Short and factual" doesn't get you a copyright waiver. To be without copyright there has to be essentially no choice in the text that was written. That's simply not true for a caption, and certainly not true for 40,000,000 of them. Jheald (talk) 23:06, 15 January 2019 (UTC)
- Hullo @Jheald: the WMF legal team says that Copyright law protects creative expression, and not ideas or concepts. Short phrases that can only be written in a limited number of ways are not protected. The caption field has a few limitations: it can only have 255 characters, it does not allow Wikitext, and it should factually describe the image. The vast majority of captions will not be a sufficiently creative work of authorship to be copyrightable. A few references from the team: Stanford Law School published a guide on how this question has been handled by U.S. Courts, and U.S. Copyright Office Circular 33 explains what level of creativity is required for protection. In cases where a description is so idiosyncratic as to require compliance with CC BY-SA, it should be removed from a CC0 caption field. Copyright law can be unsatisfyingly unclear, so if you need more help clarifying what kind of creativity should be considered, please contact the legal team and they may be able to help by writing guidance in Wikilegal. — Preceding unsigned comment added by Abittaker (WMF) (talk • contribs) 01:12, 16 January 2019 (UTC)
- @Abittaker (WMF): This is Commons. You're not just dealing with U.S. copyright here, you're dealing with copyright for the whole world. And I dispute the claim that just because the caption is limited to 255 characters and needs to factually describe the image, that that means there are only a limited small number of ways it could be written. On the contrary, there may be any number of aspects of the image that the caption-writer may choose to foreground, and any number of ways to present them. The choice of one rather than any of the others is the writer's expression, and that is what copyright protects. It's no good trying to wish this away: there is an issue here which needs to be faced. Jheald (talk) 01:22, 16 January 2019 (UTC)
- It may be interesting to note that the Indian Supreme Court recently affirmed that legal headnotes were protected by copyright. [4]. That's despite headnotes, on the face of it, being more formulaic and more derivative than image captions.
- Similarly, this 2006 paper [5] suggests that (p.187) "other than the headnotes, private publishers probably do not have copyright in the court decisions they are publishing" (emphasis added).
- In Canada the copyright status of headnotes was affirmed in the 2004 case CCH Canadian Ltd v Law Society of Upper Canada. Jheald (talk) 02:08, 16 January 2019 (UTC)
- Hullo @Jheald: the WMF legal team says that Copyright law protects creative expression, and not ideas or concepts. Short phrases that can only be written in a limited number of ways are not protected. The caption field has a few limitations: it can only have 255 characters, it does not allow Wikitext, and it should factually describe the image. The vast majority of captions will not be a sufficiently creative work of authorship to be copyrightable. A few references from the team: Stanford Law School published a guide on how this question has been handled by U.S. Courts, and U.S. Copyright Office Circular 33 explains what level of creativity is required for protection. In cases where a description is so idiosyncratic as to require compliance with CC BY-SA, it should be removed from a CC0 caption field. Copyright law can be unsatisfyingly unclear, so if you need more help clarifying what kind of creativity should be considered, please contact the legal team and they may be able to help by writing guidance in Wikilegal. — Preceding unsigned comment added by Abittaker (WMF) (talk • contribs) 01:12, 16 January 2019 (UTC)
We do not have to figure out legality of copying captions at this point. The CC0 aspect of SDC should be advertised and copyright aspects taken into account before any bot migration of captions or other free text descriptions. However other SDC data should be OK as those are non-copyrightable facts. Also I do not agree that we need to consider laws of all jurisdictions when discussing copyrights of SDC. There are many jurisdictions and some have some odd laws (See here for example). However when disusing laws related to Commons text, than the only law we need to consider is US law as that is where the servers reside. --Jarekt (talk) 03:58, 16 January 2019 (UTC)
- By the way, the text on the bottom of each Commons page "This text is available under the Creative Commons Attribution-ShareAlike Licence; additional terms may apply" should become something similar to d:Wikidata:Copyright: "All structured data from the [SDC] namespace is available under the Creative Commons CC0 License; text in the other namespaces is available under the Creative Commons Attribution-ShareAlike License; additional terms may apply. By using this site, you agree to the Terms of Use and Privacy Policy. " --Jarekt (talk) 04:14, 16 January 2019 (UTC)
I would strongly recommend keeping CC-BY-SA as the licence for structured data on Commons. We are talking about the potential of harvesting 50 million sentences' worth of caption from existing files, which are already licensed in CC-BY-SA (or something compatible). Any change in copyright terms that prevent existing image descriptions from being converted into structured data will defeat the point of adopting structured data. Deryck Chan (talk) 17:31, 20 January 2019 (UTC)
- Well, that’s debatable :) There was a similar discussion with Lexemes on Wikidata. In the end, they went for CC-Zero, in the full knowledge that this would prevent mass-copy from the Wiktionaries. Jean-Fred (talk) 18:13, 21 January 2019 (UTC)
- There are strong arguments for both, for "keeping CC-BY-SA" there is the ability of backwards compatibility that allows for a mass-import of community generated organisation hat will require the least amount of effort to help set up the structured data programme, however those in favour of CC-0 can point out that this would make the database fully exportable by third parties who wish to utilise Wikimedia Commons. In the end the issue comes down to what we want structured data on Wikimedia Commons to be, should it only be used for internal organisation? or are there external incentives that will benefit the generation of free knowledge? Maybe this would have to be discussed by the community, but I'm sure that we can trust the Wikimedia Foundation (WMF) and Wikimedia Deutschland (WMDE) to do what's in everyone's best interests.
 --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 15:49, 22 January 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 15:49, 22 January 2019 (UTC)
- There are strong arguments for both, for "keeping CC-BY-SA" there is the ability of backwards compatibility that allows for a mass-import of community generated organisation hat will require the least amount of effort to help set up the structured data programme, however those in favour of CC-0 can point out that this would make the database fully exportable by third parties who wish to utilise Wikimedia Commons. In the end the issue comes down to what we want structured data on Wikimedia Commons to be, should it only be used for internal organisation? or are there external incentives that will benefit the generation of free knowledge? Maybe this would have to be discussed by the community, but I'm sure that we can trust the Wikimedia Foundation (WMF) and Wikimedia Deutschland (WMDE) to do what's in everyone's best interests.
However, most captions are not likely to be copyrightable, since they are short and factual.
the WMF legal team says that Copyright law protects creative expression, and not ideas or concepts.
I bet neither one of you has been talking to WMF legal about this. Let me introduce myself. Alexis Jazz, one of Commons' not-actually-a-lawyer legal specialists*. You would generally be right if you were talking about one single caption, or one tweet. Or any string of 5 words from a Harry Potter book. So by that logic, I can copy 5 words from a Harry Potter book, print them in my own book, and sell this brilliant creation and make boatloads of money.
But what if I wanted to make more money?
Why, I just copy another 5 words! And I put them after those first not-quite-eligible-for-copyright 5 words. Because 10 words are much more interesting, and really, they aren't 10 words. No no no no! They are 5 words, and only 5, but there happen to be two strings of 5 words that follow each other. But still only 5 words really! But I guess a book with only 10 words won't make me a millionaire either. So let's copy another 5. And another. And another. Until I've copied the whole book. Or all of someone's Tweets. No copyright, right? After all, it's all just a string of letters and the alphabet isn't protected by copyright so we're in the clear.
That's what you are doing.
*Not legally a legal specialist. Offer void in Nebraska.
There are severe issues with this and I have raised this on VPP. - Alexis Jazz ping plz 00:04, 11 February 2019 (UTC)
Change caption to title and add a separate description property
Due to the discussion about bot-filling the captions with the description. I think it would be better to have a title in the structure data, witch could be filled by the current titles of the images. And a description, potentially filled by the current descriptions. --GPSLeo (talk) 20:51, 10 February 2019 (UTC)
- @GPSLeo: On the surface this is actually a good idea as titles like "File:Maerten van heemskerk, tauromachia nel colosseo in rovina, 1552, 01 (cropped).jpg" convey quite a bit of information, but then you have files like "File:100 0916.JPG" which are very useful images, but just less than informatively named. I can remember somewhere in the Structured Data on Wikimedia Commons discussions there being a few advocates for replacing image titles with Wikidata'esque Q numbers, but this was immediately shot down. But file titles, file descriptions, and file captions are all just fields where information is placed explaining the content of the file, theoretically they could all be interchangeable, but in practice some users develop a greater affinity for one over the other and their contributions reflect this accordingly. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:31, 11 February 2019 (UTC)
Proposal to "Fix the captions licensing"
For anyone interested please see the ongoing discussion "Commons:Village pump/Proposals#Fix the captions licensing" started by Alexis Jazz regarding the legal copyright © status of file captions. Anyone is free to give their two (2) Euro-cents on the matter. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 10:49, 11 February 2019 (UTC)
- Bizarre. Does the editing interface for the captions not reuse Wikidata's, which even includes a popup to warn of the separate license? Someone must have completely neglected to study our past experience. Nemo 11:04, 11 February 2019 (UTC)
- Clearly not. It appears to have been rolled out across the project on a policy of seeing how many things it would break, rather than thinking through how best to test it, before having an impact on 51 million web pages.
- How lovely it would be if questions like "what", "why", "when" were asked and supported by a community process, before system wide significant changes were made. Somehow the fact that it is far more expensive to resolve these questions downstream rather than in advance of making changes keeps on getting missed, despite the experience of the last 70 years of software development. --Fæ (talk) 11:39, 11 February 2019 (UTC)
- I respectfully disagree that the method the Wikimedia Foundation used was faulty, new features should be released without Community consent because "the community" (those in power or those who benefit from the status quo) will then do anything within their power to oppose any changes. Imagine if the blocking tools were up for debate, then globally locking accounts would've still been the only option instead of local blocks and the fact that the most prolific photographer on Wikimedia Commons is a user blocked on the English-language Wikipedia for threatening Filipino (Pinoy) editors with the wrath of his Latin American dwarfs and curses while here he is a well-behaved and thoughtful individual whose donations grace thousands upon thousands of Wikimedia pages show that a block on one Wikimedia website shouldn't automatically be imported to another. Or if the MediaWiki Upload Wizard wasn't created then most users would've been forced to use the old Upload Form which is very unfriendly to novice users and require you to have an intimate knowledge of copyright © tags beforehand. It’s also good that sysops aren’t interface sysops anymore because that could've caused some serious damage. I’m not saying that the Wikimedia Foundation are perfect, they’re not and several things like unsolicited global bans actively harm the project especially when they affect high profile importers like Russavia, but for this technical addition first requesting community consensus would halt progress, it’s better to fix an imperfect system than to disregard the system without giving it a chance, this is a community in which second chances don't exist and while positive contributions are forgotten the very next day something negative will never he forgotten, no matter how minor. I do agree that opting out should be an option as not all users use the MediaWiki Upload Wizard, but for users who just started editing Wikimedia Commons file captions is all they know and while “an old generation” of editors will slowly be replaced by a new one, all they know would be that data on Wikimedia Commons is structured. Wikidata also faced a lot of (especially local) resistance but as time progresses less and less of that remains, this has been a positive development. I don’t say that we should give the Wikimedia Foundation carte blanche, but we should allow them to learn rather than just shoot down every idea. The file captions are probably the least structured of all planned Structured Data on Wikimedia Commons and any negative feedback we give them now on these is something they can take into the development of the rest of the features, they would have to begin somewhere and starting with file captions is what they chose. I just hope that they won't break the MediaWiki Upload Wizard (for mobile) with the coming features, but we should at least give them a chance. A lot of user feedback has already been implemented, let’s just hope that they’ll keep doing that. We don't just edit Wikimedia Commons for ourselves, we edit it for the re-users and the Structured Data on Wikimedia Commons package will best enhance their experience. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 13:58, 11 February 2019 (UTC)
- Yeah, but it was stupid...
- I do have to agree with the fact that the launch of file captions was sloppily done, the Wikimedia Foundation should've never assumed that file captions could not be copyrighted and should have just added the Creative Commons 0 (Zero) license there since day one, but at least now they won't repeat this mistake with any other Structured Data on Wikimedia Commons feature. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 14:24, 11 February 2019 (UTC)
Wikidata RfC related to the inclusion of Wikimedia Commons categories
Everyone is invited to give their opinion whether or not Wikidata should allow for the inclusion of items with only a Wikimedia Commons category, this request for comment was started to help the Structured Data on Wikimedia Commons programme and could be found on Wikidata at "Wikidata:Wikidata:Requests for comment/Allow for Wikidata items to be created that only link to a single Wikimedia Commons category (Wikidata notability discussion)". Note that this request for comment is on Wikidata so following that link will take you off Wikimedia Commons (as if this website is a wikidrug ![]() ). --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:23, 12 February 2019 (UTC)
). --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:23, 12 February 2019 (UTC)
CC0 licensing mockups
Here are the designs for notifying contributors of licensing for captions/the structured data portions of Commons. The text has been signed off by the Wikimedia Foundation's legal department, and the function is heavily influenced by how Wikidata serves a licensing popout.
File page
The file pages works like Wikidata: a user is served a popup informing them of structured data licensing when entering the edit mode, and accepting the information will permanently dismiss the notice.

UploadWizard
Since the UploadWizard doesn't have an edit mode, the licensing for captions and structured data will be shown in the Release Rights step.
-
 No license selected.
No license selected. -
 License selected - own work.
License selected - own work. -
 License selected - not own work.
License selected - not own work.

.png)
.png)
Discussion (mockups)
Please let the team know of any questions or concerns you might have about these designs, so that we can attempt to address them. These notifications are going to go live here on Commons once they are coded up and ready to go. Keegan (WMF) (talk) 20:54, 5 February 2019 (UTC)
- For UW, the text says "By clicking 'publish' you agree to …", but the button you have to click is actually labelled "next". That's a bit confusing if you ask me. --El Grafo (talk) 10:19, 6 February 2019 (UTC)
- +1, furthermore the captions are not mandatory... and you can upload a file without caption.... so it is really confusing, at this place and in this form. IMO, in the UploadWizard, the text should be at the next step and just below the caption field. Christian Ferrer (talk) 12:28, 6 February 2019 (UTC)
- Thank you both, very helpful. Other observations are still appreciated. Keegan (WMF) (talk) 18:11, 6 February 2019 (UTC)
- I don't find the boxes confusing, but I must concede that they would have to be as clear as possible for everyone. However I oppose placing the licensing information anywhere later in the MediaWiki Upload Wizard as it will clutter up the file information fields, the second page of the MediaWiki Upload Wizard is literally called the licensing page and the above screenshots make the most sense. Alternatively at the bottom of every page on Wikimedia Commons there is a text which reads "This page was last edited on 6 February 2019, at 12:17. Text is available under the Creative Commons Attribution-ShareAlike License; additional terms may apply. By using this site, you agree to the Terms of Use and Privacy Policy.", this text could also be expanded to include Structured Data for Wikimedia Commons. Anyhow I dislike the idea of adding the license on the third (2) page of the MediaWiki Upload Wizard, even placing it under "information" would be confusing for some people or might even be seen as "deceiving". --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:13, 6 February 2019 (UTC)
- Thank you both, very helpful. Other observations are still appreciated. Keegan (WMF) (talk) 18:11, 6 February 2019 (UTC)
- +1, furthermore the captions are not mandatory... and you can upload a file without caption.... so it is really confusing, at this place and in this form. IMO, in the UploadWizard, the text should be at the next step and just below the caption field. Christian Ferrer (talk) 12:28, 6 February 2019 (UTC)
- Sorry, do we actually want the captions to need to be CC0 ? Did the community decide this?
- The consequence of this is that we won't be able to create captions directly from descriptions. Is this the right call? Jheald (talk) 18:48, 6 February 2019 (UTC)
- @Jheald: RIsler (WMF) may speak to the product decision on captions licensing being CC0; my understanding is that CC0 is a necessity for the feature as part of the ecosystem of the structured data project. As to your concerns about how some simple descriptions can or may be copied into captions, I believe @Mike Peel: is planning a Village Pump/Proposal on the topic, as how to handle statements of fact will be a community content policy decision. The best I can do is repeat the opinion of the Wikimedia Foundation Legal Department, which you have previously stated your disagreement with:
The text on Commons is CC BY-SA currently, to the extent it's protected by copyright. However, most captions are not likely to be copyrightable, since they are short and factual. Copyright protects creative works of expression, and not the underlying ideas. It's possible that there will be some descriptions that are so idiosyncratic to get Copyright protection, and Commons has a couple of options if that comes up: 1) argue that they are not copyrightable, 2) just remove those captions and write a better, CC0 caption. Either choice would be guided by how the Commons community would like to settle it on Commons:File captions.
- @Jheald: RIsler (WMF) may speak to the product decision on captions licensing being CC0; my understanding is that CC0 is a necessity for the feature as part of the ecosystem of the structured data project. As to your concerns about how some simple descriptions can or may be copied into captions, I believe @Mike Peel: is planning a Village Pump/Proposal on the topic, as how to handle statements of fact will be a community content policy decision. The best I can do is repeat the opinion of the Wikimedia Foundation Legal Department, which you have previously stated your disagreement with:
- Keegan (WMF) (talk) 19:20, 6 February 2019 (UTC)
- To add to what Keegan wrote above, from a product ecosystem standpoint we do want SDC's license to be compatible with Wikidata to enable smooth cross-project usage and avoid a lot of headaches (ex: in the future perhaps people will want to import Wikidata labels into image captions in cases where there are depicted objects, people, etc.) RIsler (WMF) (talk) 20:08, 6 February 2019 (UTC)
- As I explained above, you are grossly misinterpreting what legal said. - Alexis Jazz ping plz 19:08, 11 February 2019 (UTC)
- To confirm for the Wikimedia Legal team, I have been and I still am working with the team on this project. Text can be licensed CC BY-SA to the extent it's protected by copyright, and copyright protects creative works of expression, and not the underlying ideas. Names, titles, slogans, and other short phrases are not protected by copyright if they do not contain a sufficient amount of creativity. Unprotectable phrases can be used under CC0 even if uploaded under CC BY-SA. Stephen LaPorte (WMF) (talk) 01:06, 13 February 2019 (UTC)
- @Slaporte (WMF): Thank you for coming back to us. But these are not reusable names, titles, slogans, phrases we are talking about, they are descriptions written specifically to describe the images, reflecting choices about what wording to use, what aspects of the image to include or not to include, and often also knowledge, skill, and judgment about the object depicted. (For instance, User:Pigsonthewing's coin example diff).
- Secondly, does your answer represent a worldwide perspective? It's not so long ago (perhaps a decade) since the governing standard in English law was still Walter v Lane, a very low standard of originality indeed; and in Australia Telstra Corporation Ltd v Desktop Marketing Systems Pty Ltd. Have you considered the law outside the United States?
- Thirdly, there's the question of accumulation: even if copyright law allowed the stray reuse of one caption to be de minimis, the taking of 1000 descriptions, or ten thousand, or a million, is an appropriation of a substantial body of work. Have you considered this?
- Fourthly there's the question of database right. On the face of it, European contributors could justifiably argue that the totality of their descriptions represent a database in which they have invested considerable time and effort, of which appropriation for Commons wikibase represents an unauthorised taking, because Commons wikibase does not impose the "share alike" condition.
- Does WMF legal have views on these points? Jheald (talk) 10:36, 13 February 2019 (UTC)
- The example in question is "A silver hammered penny of Edward the Confessor, minted in Southwark between 1042 and 1044. Moneyer: Wulfwine." As I said in the previous discussion; I remain to be convinced that that is copyrightable. It does seem to meet the test "short phrases [that] do not contain a sufficient amount of creativity" (note that "research" is not "creativity"). Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 17:24, 13 February 2019 (UTC)
- Please avoid turning a passing comment into a "test". This is highly misleading and WMF Legal have not given any protection against damages for volunteers. EU law, UK law, USA law is very clear, it is entirely possible for "short phrases" to be copyrighted and it is very, very, clear that database rights do not vanish simply because you cut up metadata and paste it piecemeal into one sentence long fields on a website with a copyfraudulent CC0 claim. --Fæ (talk) 11:58, 14 February 2019 (UTC)
- The example in question is "A silver hammered penny of Edward the Confessor, minted in Southwark between 1042 and 1044. Moneyer: Wulfwine." As I said in the previous discussion; I remain to be convinced that that is copyrightable. It does seem to meet the test "short phrases [that] do not contain a sufficient amount of creativity" (note that "research" is not "creativity"). Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 17:24, 13 February 2019 (UTC)
- @Slaporte (WMF): Could WMF Legal please separately publish a statement of immunity for volunteers that copy text into the CC0 captions field from original sources with both/either moral rights and database rights in force? Both of these copyright concerns apply to our imported files on Commons and volunteers (as I see it) are already risking claims of damages. This should be fine and dandy if WMF Legal are the ones who become liable, because you gave us (unpaid volunteers) legal advice which we can easily understand and reference. If you are not prepared to do this, please make a definitive statement so that volunteers have no doubt about the financial personal risk they take should they choose to copy, cut and paste or automatically populate text into the captions field without first assuring themselves that their source has a CC0 release. As you are well aware, under EU and UK law that applies to many of us writing in this discussion, database rights apply to systematic mass copying of even simple data, these rights are not obviated by hosting Wikimedia web pages in the USA. Thanks in advance. --Fæ (talk) 10:59, 13 February 2019 (UTC)
- To confirm for the Wikimedia Legal team, I have been and I still am working with the team on this project. Text can be licensed CC BY-SA to the extent it's protected by copyright, and copyright protects creative works of expression, and not the underlying ideas. Names, titles, slogans, and other short phrases are not protected by copyright if they do not contain a sufficient amount of creativity. Unprotectable phrases can be used under CC0 even if uploaded under CC BY-SA. Stephen LaPorte (WMF) (talk) 01:06, 13 February 2019 (UTC)
- As I explained above, you are grossly misinterpreting what legal said. - Alexis Jazz ping plz 19:08, 11 February 2019 (UTC)
- To add to what Keegan wrote above, from a product ecosystem standpoint we do want SDC's license to be compatible with Wikidata to enable smooth cross-project usage and avoid a lot of headaches (ex: in the future perhaps people will want to import Wikidata labels into image captions in cases where there are depicted objects, people, etc.) RIsler (WMF) (talk) 20:08, 6 February 2019 (UTC)
- Keegan (WMF) (talk) 19:20, 6 February 2019 (UTC)
- I also found the CC0 boxes in the above images confusing. It should be clear that CC0 license relates to the SDC so it should be somewhere near SDC. I agree that SDC need to be released under the same license as Wikidata, otherwise it will be hard to use them together. I do not think that is something we want to be proposing and debating. We need to make clear to users that SDC is CC0 and the community should be deciding about bot tasks for filling SDC based on the file descriptions. Such bot tasks need to be evaluated based on if the data copied is eligible for copyright. Other than free-text descriptions / captions most image metadata (source, date, author, copyright, camera type and setup, etc.) are not eligible. --Jarekt (talk) 20:57, 6 February 2019 (UTC)
- Since years we have been arguing that paraphrasing and taking data only from copyrighted sources is not an infringement of copyright. Big parts of Wikipedia is based on cannibalizing 3rd party descriptions, image descriptions too are often small snippets of text taken from somewhere else. Now, as our texts and our descriptions are going to be cannibalized by SD, wikidata and similar, there is no reason to complain about. The way to go with CC0 is more than logical from the WMF POV. The importance of community contributions is diminished along with the vanishing community. best --Herzi Pinki (talk) 18:38, 7 February 2019 (UTC)
- The file description page popup is confusing, in that the first paragraph uses "you" and "your" (2nd person), and the second switches to "I" (1st person). Please be consistent. — Jeff G. ツ please ping or talk to me 13:13, 11 February 2019 (UTC)
- This is all well and good, but doesn't actually address the issue that all captions added up until the point that this is effectively implemented aren't actually licensed under CC0. GMGtalk 13:23, 11 February 2019 (UTC)
- @GreenMeansGo: the advice from WMF Legal above tells us that if a caption is a non-creative, i.e. a simple description, they can be re-licensed as CC0 as CC-BY was never a valid copyright claim in the first place. This is similar in concept to Template:PD-ineligible. I'm working on getting WMF Legal to reiterate this here on the wiki. Keegan (WMF) (talk) 17:43, 11 February 2019 (UTC)
- Yes, but that is not a rationale that can be applied en masse based solely on character count. If a tweet can be copyrighted (e.g., [6] [7]) at originally about half the length, then our 255 character captions certainly can be also. And there's really no way to tell which are substantially creative and which are not without manually reviewing them all, that is of course, unless you have an active CC0 dedication. GMGtalk 17:56, 11 February 2019 (UTC)
- I don't think it's a good idea to mass-import descriptions into captions for many reasons; neither I nor the WMF is/are/were taking such a position. I personally think a small set of manually curated files with known simple descriptions probably would have been a better route to take, with Commons defining within itself at Commons:File captions what it wants to consider a short, simple, factual description (and thus ineligible for copyright, as those links you provide make pains to point out). Keegan (WMF) (talk) 18:26, 11 February 2019 (UTC)
- All of these screenshots show too much clutter and confusion. New users will definitely be confused and think they have to release their uploads as CC0. Captions in the UploadWizard should be disabled by default. Users could enable captions in their preferences and when they do, you confront them with the license accept window. For users who don't do that, they will have to enter captions after uploading or wait for someone else to enter captions for their uploads. As this is after the upload, there will be much less confusion over what is being licensed. - Alexis Jazz ping plz 19:04, 11 February 2019 (UTC)
- "Your contribution" is nowhere near clear enough. The text needs to explain precisely what the user has to release under CC0. The heading is slightly helpful, but anyone who's dealt with legal documents knows that headings are non-binding. --bjh21 (talk) 20:22, 11 February 2019 (UTC)
- Hello everyone. Thanks for your input in this discussion. With WMF legal's help, we've begun implementing the CC0 structured data notices based on the feedback here. Today, you'll find a new popover explaining the terms when you attempt to add a caption on the File Page (clicking "Accept" will make the popover go away for subsequent edits), and there is a new notice about CC0 and captions on the Describe step of UploadWizard. Updates to the legal text in the site footer are being translated now and we expect them to appear on the site next week. Thanks for your help and understanding. RIsler (WMF) (talk) 01:50, 13 February 2019 (UTC)
- @RIsler (WMF): this is good. But what will be done about the captions that were entered before the popover? - Alexis Jazz ping plz 18:11, 13 February 2019 (UTC)
Copyright notice at the bottom of all pages
As I posted at Village Pump/Copyright[8], the text at the bottom of pages on Commons is also being modified to clarify licensing obligations[9]. Keegan (WMF) (talk) 18:31, 7 February 2019 (UTC)
- Y'all forgot the GNU Free Documentation License (which is still giving Alexis Jazz nightmares), as every edit you make in desktop mode has the message "By saving changes, you agree to the Terms of Use, and you irrevocably agree to release your contribution under the Creative Commons Attribution-ShareAlike 3.0 license and the GFDL. You agree that a hyperlink or URL is sufficient attribution under the Creative Commons license." (note 📝 that this isn't visible on mobile). I am not saying that the GFDL should apply to structured data, but it's currently not mentioned on the bottom of any pages which seems odd as every edit saved in "desktop mode" mentions it. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 08:01, 12 February 2019 (UTC)
- @Donald Trung: right, GFDL. Gotta put another bullet in that.
 - Alexis Jazz ping plz 14:32, 12 February 2019 (UTC)
- Alexis Jazz ping plz 14:32, 12 February 2019 (UTC)
- @Donald Trung: right, GFDL. Gotta put another bullet in that.
SQL to find captions
I'm trying to find a quick way to identify/report files in specific collections with captions. I raised the slow Pywikibot API method I have here, and suspect that a specific line of SQL could be massively faster, but after checking out the public database I have no idea where captions are supposed to be. Am I missing something, or have the database changes not been replicated yet to commons_p? --Fæ (talk) 15:52, 13 February 2019 (UTC)
- I was trying to do the same yesterday (fetching captions in SQL), and ended up in the same place − could not find anything in the database tables. Tentatively poking @Addshore: . Jean-Fred (talk) 09:53, 14 February 2019 (UTC)
- Captions (and all other content, like statements) are content, not metadata, so you can't pull it from MySQL (as we don't store it there, but in ExternalStore, like with wikitext). Once there's a WDQS instance for Commons you could use that, but that's not available yet, sorry. See T141602. Jdforrester (WMF) (talk) 19:15, 14 February 2019 (UTC)
- Wouldn’t it be possible to (additionally) save captions in the wb_terms table, just as it is done with labels, descriptions, and aliases at Wikidata? From my experience with WDQS, large-scale string operations such as regex searches are much more efficient in SQL than in SPARQL. —MisterSynergy (talk) 20:04, 14 February 2019 (UTC)
- @MisterSynergy: The
wb_termstable is deprecated and not written to in modern installations because they melt the database servers. Wikidata.org needs to migrate off the table soon, but is held back by lots of community-written hacks relying on it instead of using the scalable SPARQL servers, sadly. Jdforrester (WMF) (talk) 20:22, 14 February 2019 (UTC)- Oh really? At mw:Wikibase/Schema, it is not marked as deprecated. WDQS has that 1 minute timeout which makes it pretty useless for lots of string operations. At wikidata:Wikidata:Request a query we regularly have requests related to terms which do not work with SPARQL, but they do with SQL (using the Quarry tool or the toolforge console). —MisterSynergy (talk) 20:34, 14 February 2019 (UTC)
- @MisterSynergy: Didn't know about that page, now fixed. Jdforrester (WMF) (talk) 21:03, 14 February 2019 (UTC)
- Oh really? At mw:Wikibase/Schema, it is not marked as deprecated. WDQS has that 1 minute timeout which makes it pretty useless for lots of string operations. At wikidata:Wikidata:Request a query we regularly have requests related to terms which do not work with SPARQL, but they do with SQL (using the Quarry tool or the toolforge console). —MisterSynergy (talk) 20:34, 14 February 2019 (UTC)
- @MisterSynergy: The
- Wouldn’t it be possible to (additionally) save captions in the wb_terms table, just as it is done with labels, descriptions, and aliases at Wikidata? From my experience with WDQS, large-scale string operations such as regex searches are much more efficient in SQL than in SPARQL. —MisterSynergy (talk) 20:04, 14 February 2019 (UTC)
- @Jdforrester (WMF): Thanks for the answer. If the content is not in the tables, are the 'log actions' about captions somewhere? I imagine they have to be in order to populate history tab and contributions. For the use case I have I care less about the content: it’s more “Get a list of files which had a caption edited between date X and Y”, or “Get a list of all users who edited at least X captions”.
- Thanks, Jean-Fred (talk) 23:10, 14 February 2019 (UTC)
- @Jean-Frédéric: It's very messy, I'm afraid – Wikibase is designed to be fast to render and edit, and search is meant to take place on the SPARQL side. This query:
select rev_id, rev_text_id, rev_user, rev_user_text, comment_text from (SELECT * FROM revision LEFT JOIN revision_comment_temp ON rev_id = revcomment_rev WHERE rev_page=174) AS foo LEFT JOIN comment ON comment_id=revcomment_comment_id WHERE comment_text LIKE "/* wbsetlabel-%" ORDER BY rev_id DESC
- … gets you every revision that adjusted a caption (and with a code-side regex, what language, and whether it was an add/alter/remove), but it's (a) slow, (b) doesn't scale to multiple files without slowing down the database a bunch, and (c) could be gamed by users manually writing random edit summaries starting "/* wbsetlabel-" just to be difficult. That probably doesn't help. Jdforrester (WMF) (talk) 23:55, 14 February 2019 (UTC)
- @Jean-Frédéric: It's very messy, I'm afraid – Wikibase is designed to be fast to render and edit, and search is meant to take place on the SPARQL side. This query:
- Captions (and all other content, like statements) are content, not metadata, so you can't pull it from MySQL (as we don't store it there, but in ExternalStore, like with wikitext). Once there's a WDQS instance for Commons you could use that, but that's not available yet, sorry. See T141602. Jdforrester (WMF) (talk) 19:15, 14 February 2019 (UTC)
Captions and Hot Cat
I have encounter possible problem. Can someone reproduce it?
- Go to preferences and switch on Hot Cat
- Go to whatever file
- Add caption in two languages and save it
- Than Add more categories via Hot Cat tool and save it
Youll be warned that you are editing old revision, but this I think is not the truth, just kind of wrong recognition of Hot Cat. Juandev (talk) 20:07, 15 February 2019 (UTC)
- Same message if editing just one category. Juandev (talk) 20:31, 15 February 2019 (UTC)
This has already been reported. Christian Ferrer (talk) 23:40, 15 February 2019 (UTC)
Retroactive copyright? Or is the Elephant still towering over us?
-
 The new notices, not where I'd place them, but that's not even my biggest issue with them.
The new notices, not where I'd place them, but that's not even my biggest issue with them. -
 The new notices, not where I'd place them, but that's not even my biggest issue with them.
The new notices, not where I'd place them, but that's not even my biggest issue with them.
.png)
.png)
Today we finally got something we should've gotten since day 1 (one), see the above attachments, but from what I can tell this doesn't retroactively affect older file captions, sure WMF Legal assured us that they suspect that these fall under the "COM:TOO" but a fair amount of editors have expressed their doubts and requested clarification. Now here's the issue, older file captions aren't affected by this notice (Mobile 📱) as Jeff G. specifically said "Any caption I in my individual capacity have created on Wikimedia Commons falls (irrevocably) under the site's Creative Commons Attribution-ShareAlike License, version 3.0. —Jeff G. ツ please ping or talk to me 14:31, 12 February 2019 (UTC)" however his contributions aren't alone in this, all other file captions (except for mine) still potentially fall under this. In order to not repeat this mistake, could the template please be immediately updated to reflect any other subdivision of Structured Data on Wikimedia Commons as they roll out? The moment we get file depicts this template should be updated to reflect their licenses, we tend to be very careful when it concerns copyright © issues so please let's plan ahead before the next feature launch. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:05, 13 February 2019 (UTC)
- There is no good solution for all prior captions. They should be deleted as a precaution. Commons is not here to systematically commit copyfraud. --Fæ (talk) 11:16, 13 February 2019 (UTC)
- @Fæ: deletion is a very heavy-handed step, I think that a notice on some files that their captions might be Creative Commons Attribution-ShareAlike License, version 3.0 is probably sufficient. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:21, 13 February 2019 (UTC)
- It's not realistic to believe that in a year, 5 years or 20 years time, someone will not be mass processing and copying all captions elsewhere into other products, including reselling the data, on the presumption that all the text is CC0 and no attribution is needed.
- Simply sticking a weird template on the image page, will not even be visible to the normal API query. --Fæ (talk) 11:34, 13 February 2019 (UTC)
- Basically what Fae said. CC0 is not compatible with CCBYSA 3.0, and the only way to attack that is by invoking the threshold of originality. But TOO depends on creativity and not simplicity, where simplicity is only a proximate measure of creativity. TOO also varies wildly across jurisdictions and... basically I don't see any way of resolving the issue outside of replacing them entirely or winding up in some version of a giant cluster fuck. Well, that or just admitting that "we honestly don't really give a crap about whether they're properly licensed or not, we'll do what we wan't regardless and give us a takedown notice or shut up about it". That's the easiest solution, but is wholly antithetical to the entire rest of the project. GMGtalk 13:28, 13 February 2019 (UTC)
- @Fæ: deletion is a very heavy-handed step, I think that a notice on some files that their captions might be Creative Commons Attribution-ShareAlike License, version 3.0 is probably sufficient. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:21, 13 February 2019 (UTC)
- sure WMF Legal assured us that they suspect that these fall under the "COM:TOO"
- @Donald Trung: where did legal say that. Afaik that was just some gross misinterpretation by the devs who don't understand legal. These older captions have to be either deleted (too bad), manually checked for TOO (who's gonna do that? not me I tell you) or the authors need to be asked for permission, which given that many were probably copypasted.. no. - Alexis Jazz ping plz 20:42, 14 February 2019 (UTC)
- @Alexis Jazz: , you are right, the legal department of the Wikimedia Foundation didn't say that, the developers on this page stated that legal told them something and they just went with it, but as Jheald said above there has been a Phabricator ticket requesting a clarification of this since 2017 which got largely ignored. The worst part is that this has been addressed years before file captions were launched. I still think that a mass-message and a page for opting in for the Creative Commons 0 (Zero) license, this is better than deleting. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:07, 14 February 2019 (UTC)
- I just noticed above that Slaporte (WMF) actually works with the devs. But his reply makes me worry a bit.. Either Stephen doesn't understand the legal ramifications of copying many descriptions as opposed to just one or he has never read any actual description/caption. I don't know which would worry me more. - Alexis Jazz ping plz 22:41, 14 February 2019 (UTC)
- @Alexis Jazz: your example above about taking sentences from Harry Potter books covers a creative work and has nothing to do with this. We are discussing short, non-creative works that factual describe something. Short, non-creative, factual statements have never been protected by copyright, and those kinds of descriptions are what should be discussed for captions. When a description is a short, factual, non-creative statement, it's eligible for CC0 as such a thing was ineligible for CCBY in the first place. Conceptually, this is no different than Template:PD-ineligible. If a caption is potentially creative, it can be deleted or re-written. Keegan (WMF) (talk) 22:07, 15 February 2019 (UTC)
- "The rough practical test [is] that what is worth copying is prima facie worth protecting" (Peterson J, 1916) [10] "The word original does not in this connection mean that the work must be the expression of original or inventive thought... the Act does not require that the expression must be in an original or novel form, but that the work must not be copied from another work" (ibid.) This was in the wake of Walter v Lane (1900), which held that shorthand writers were entitled to prevent their record of a speech from being copied, even though it was drawn directly from what the speaker had said. Compare also the Australian case Telstra Corporation Ltd v Desktop Marketing Systems Pty Ltd (2001) which found that Telstra was entitled to copyright in the contents of a telephone directory -- you don't get a lot more factual or non-creative than that. Both English and Australian law have drawn back a bit from this in the last ten years, but to say "short, non-creative, factual statements have never been protected by copyright" is simply not true. The all-protecting approach of Peterson and Walter v Lane was dominant in most of the English-speaking world for the whole of the 20th century. Even today, the German Copyright Arbitration Board has suggested that takings of just seven words should be enough to trigger Germany's ancillary copyright for press publishers [11] -- even with "individual words and smallest text excerpts" specifically excluded. When Fae says below that "descriptions, captions and even titles are creative works", that is exactly correct. Use of titles is generally fair, because of the need to be able to refer to works. But the same can't be said of wholesale taking of descriptions and captions.
- I put up 4 questions for WMF Legal in the wake of User:Slaporte (WMF)'s contribution above. [12]. Unless and until we have a satisfactory response on those questions, I don't think we will have guidance we can treat as either sufficiently considered, or reliable. Jheald (talk) 23:26, 15 February 2019 (UTC)
- Perhaps also worth noting that the lead EU case on this at the moment is Infopaq (2009) which found that "storing an extract of a protected work comprising 11 words and printing out that extract, is such as to come within the concept of reproduction in part within the meaning of Article 2 of Directive 2001/29 ..., if the elements thus reproduced are the expression of the intellectual creation of their author; it is for the national court to make this determination." Jheald (talk) 00:17, 16 February 2019 (UTC)
- Descriptions, captions and even titles are creative works. Perhaps you could encourage WMF legal to be definitive? If only pure uncopyrightable data were allowed in captions your personal views would carry more weight, but that is not what the WMF rolled out. --Fæ (talk) 22:17, 15 February 2019 (UTC)
- Hi Fæ. "Perhaps you could encourage WMF legal to be definitive? If only pure uncopyrightable data were allowed in captions your personal views would carry more weight". This has occurred. I understand the statement from WMF Legal is contrary to your position, but this is what it is. It's not my personal view, as you've said previously. Keegan (WMF) (talk) 22:36, 15 February 2019 (UTC)
- @Keegan (WMF): I would really, really want to see Slaporte (WMF) elaborate on this, because I think he's sorely mistaken here. Could you release some simplistic data, even in large amounts, as w:Template:PD-USonly? Perhaps. I look forward to your proposal to start accepting PD-USonly here, because it's not even a valid license for content on Commons. But could you release it as CC0? No, absolutely not. Because you don't own the rights. COM:TOO in the UK for example is far lower, some countries have database rights. PD-USonly doesn't equal CC0. You should know that. And file descriptions aren't always "short, non-creative, factual statements". I laid out exactly what you should do on Commons talk:File captions#Best practices?. File captions may be re-introduced at some later stage, after some thorough discussion. Shoving broken features down our throat does not create goodwill. Working with us to create features that are useful will make everyone happy. My comment on Commons:Village pump#Proposal to remove captions feature holds true: "I don't think every new feature requires having a vote, but I do think the captions feature should be disabled for now. At the very least, there should be an option (without hacks) to disable it. The issue with huge boxes appearing needs to be fixed/made collapsible. phab:T213571 needs to be fixed. A clear plan on how this works together with descriptions needs to be presented. Realistic use cases need to be presented."
- Your comment on Commons talk:File captions puzzles me: "Captions are but a single feature of the entire suite, and one that had to be introduced first for a plethora of reasons". No. They didn't. Captions didn't have to be the first feature, shouldn't have been the first feature, and in the current form, should never even be a feature. Don't just plow on from here. The community goodwill you have has been severely damaged. - Alexis Jazz ping plz 23:27, 15 February 2019 (UTC)
- Hi Fæ. "Perhaps you could encourage WMF legal to be definitive? If only pure uncopyrightable data were allowed in captions your personal views would carry more weight". This has occurred. I understand the statement from WMF Legal is contrary to your position, but this is what it is. It's not my personal view, as you've said previously. Keegan (WMF) (talk) 22:36, 15 February 2019 (UTC)
- @Alexis Jazz: your example above about taking sentences from Harry Potter books covers a creative work and has nothing to do with this. We are discussing short, non-creative works that factual describe something. Short, non-creative, factual statements have never been protected by copyright, and those kinds of descriptions are what should be discussed for captions. When a description is a short, factual, non-creative statement, it's eligible for CC0 as such a thing was ineligible for CCBY in the first place. Conceptually, this is no different than Template:PD-ineligible. If a caption is potentially creative, it can be deleted or re-written. Keegan (WMF) (talk) 22:07, 15 February 2019 (UTC)
- I just noticed above that Slaporte (WMF) actually works with the devs. But his reply makes me worry a bit.. Either Stephen doesn't understand the legal ramifications of copying many descriptions as opposed to just one or he has never read any actual description/caption. I don't know which would worry me more. - Alexis Jazz ping plz 22:41, 14 February 2019 (UTC)
- @Alexis Jazz: , you are right, the legal department of the Wikimedia Foundation didn't say that, the developers on this page stated that legal told them something and they just went with it, but as Jheald said above there has been a Phabricator ticket requesting a clarification of this since 2017 which got largely ignored. The worst part is that this has been addressed years before file captions were launched. I still think that a mass-message and a page for opting in for the Creative Commons 0 (Zero) license, this is better than deleting. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:07, 14 February 2019 (UTC)
Could we avoid spreading deliberate disinformation about copyright please?
@Keegan (WMF): When a member of WMF Legal states "Unprotectable phrases can be used under CC0" nobody is disagreeing with this obvious statement. However this is not "contrary to your position" it actually fully supports my position. The disinformation you appear to be spreading is that in a scenario when there are no rules whatsoever about what text will go in a caption field, it is most likely that well meaning volunteers will be mass cut and pasting from the existing CC-BY descriptions and metadata, but whatever fits in a 255 character caption field is not necessarily copyright ineligible. That is false and encourages copyfraud, hardly the advice that WMF Legal would stand by should there be a take down or a case for damages due to systematic failure to respect the legal requirement for moral rights. --Fæ (talk) 11:41, 16 February 2019 (UTC)
Now this is getting a bit too bonkers for my taste
-
 I can accept file captions being repeated twice, but four times (4x) on the same file 📁 is beyond bonkers.
I can accept file captions being repeated twice, but four times (4x) on the same file 📁 is beyond bonkers. -
 I can accept file captions being repeated twice, but four times (4x) on the same file 📁 is beyond bonkers.
I can accept file captions being repeated twice, but four times (4x) on the same file 📁 is beyond bonkers.
_01.png)
_02.png)
So now I'm not just seeing the same "Captions" twice, I'm seeing them 4 (four) times on the same files, please don't delay file depicts, but I'm beginning to think that we're all Beta-testers now. ![]() --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:48, 16 February 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:48, 16 February 2019 (UTC)
- We've been a beta tester since Day 1. — regards, Revi 18:30, 16 February 2019 (UTC)
- Alpha. :( — Jeff G. ツ please ping or talk to me 18:32, 16 February 2019 (UTC)
- Mockup. Licensing issues would have been solved in alpha. - Alexis Jazz ping plz 08:58, 17 February 2019 (UTC)
- Alpha. :( — Jeff G. ツ please ping or talk to me 18:32, 16 February 2019 (UTC)
Captions Vs. Descriptions
Alright, I really do not want to sound daft or anything, and I've already heard read an explanation, but I genuinely can't tell the exact advantage of "captions" over "descriptions", I get that "descriptions" are in WikiCode and can't be used with the infrastructure of the new "Structured Data", but other than character limitations I don't exactly understand how "captions" help with structured data, do they allow for data-mining ⛏ to automatically create "depicts" based on them? How exactly do they organise files in ways that "descriptions" don't? When I search for a file the file descriptions are also searched, so how do file captions improve upon this? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:40, 16 January 2019 (UTC)
Also, descriptions can be multilingual as well, the way adding different languages is done using the MediaWiki Upload Wizard is identical, how are the languages of file captions better organised than those of "descriptions"? I've seen the new upcoming designs and they all look great, but I still don't see where the advantages of "Captions" come to play. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:44, 16 January 2019 (UTC)
- I think the next set of releases for structured data, depicts support followed by support for other properties, will help illustrate how captions fits in with the coming features, particularly on the back end of the software. Search with captions and statements, for example, will be an entirely different experience and it's very hard to illustrate that right now. The next question might be why wasn't captions released with this other stuff, then? The answer to that is the underlying technology behind captions that will power the rest of structured data - namely Federated Wikibase and multi-content revisions - is brand new and had to be integrated into Commons first, before we can finish development and release of the next feature set. Keegan (WMF) (talk) 22:35, 16 January 2019 (UTC)
- Ah, well patience is a virtue then, but seeing how we now have 3 (three) fields for descriptive information ("the title", "Descriptions", and "Captions") I can understand the backlash. But thanks for explaining, although I still think that removing the character limit from "captions" (or at least synchronizing it with "descriptions'" 10.000 character limit) and then having a bot automatically copy all current "descriptions" to captions would've been preferable.
- By the way, shall "depicts" and other planned structured data fields also be integrated with the MediaWiki Upload Wizard 🧙♂️? Or shall it not pass? And if so, is there concept art of this available? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:42, 18 January 2019 (UTC)
- More will be integrated into the UploadWizard that will provide context for captions, though I do not have details or designs to share right now. More will be available in the next couple of weeks as the team moves past captions fixes and into depicts testing. Keegan (WMF) (talk) 21:05, 18 January 2019 (UTC)
- By the way, shall "depicts" and other planned structured data fields also be integrated with the MediaWiki Upload Wizard 🧙♂️? Or shall it not pass? And if so, is there concept art of this available? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:42, 18 January 2019 (UTC)
I honestly still don't understand the differences on a superficial level (other than their lenght), but understand why it's needed on a technical level, so this section could also be archived. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:15, 27 February 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:15, 27 February 2019 (UTC)
"Depictes" (local Vs. Wikidata-based solutions)
Hello 👋🏻 y'all,
What are "Depicts" going to be? Are they going to be local items or will they be hosted on Wikidata? My idea 💡 would be for them to be locally hosted on Wikimedia Commons in a new namespace such as "Depict:Confucius" which could then link to the Wikidata page about "Confucius", one advantage this could have is that they wouldn't be called into question as much regarding their notability as Wikimedia Commons basically has no notability standards. If they're locally hosted they could be locally linked and connected with Wikidata, at "Wikidata:Wikidata:Requests for comment/Proposal to create a separate section for "Commonswiki" links" I requested Wikimedia Commons categories and galleries being linked at the same time to a Wikidata "item" and "Depicts" could then also be added on to that request, this would also enable translations from other Wikimedia websites to be seamlessly imported and puts minimal effort on the Community to maintain it. Thoughts 💭? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 16:49, 21 January 2019 (UTC)

What I suggest for Wikidata would be link this (stole the design from Christian Ferrer):
- In other projects
- Wikimedia Commons
And then information could be automatically imported, most English speakers don't know that "Pikachu" is "ピカチュウ" in Japanese, or that "Poké Ball" is "モンスターボール" (Monster Ball) in Japanese, but keeping it local would also allow non-notable (according to Wikidata standards) depicts to be hosted here such as Great Balls (スーパーボール, Super Balls), Ultra Balls (ハイパーボール, Hyper Balls), Master Balls (マスターボール), Safari Balls (サファリボール), Level Balls (レベルボール), Lure Balls (ルアーボール), Moon Balls (ムーンボール), Etc.. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:05, 21 January 2019 (UTC)
- The basic idea of notability in Wikidata is, that any Wikiproject needs it. So if there is anything with many pictures of it, it is okay to create a Wikidata item for it. If there is only one picture of it there is no need to create an item of grouping the images. --GPSLeo (talk) 17:38, 21 January 2019 (UTC)
- Now as an example from the Dutch-language Wikipedia let’s look at “w:nl:Bristol (winkelketen)” (Link 🔗 / Mobile 📱), which is related to the Wikimedia Commons category “Bristol (shop)”, its deletion log reads “Een pagina met deze titel is eerder aangemaakt en daarna verwijderd of hernoemd, zie hieronder: 10 jan 2008 10:41 MoiraMoira (overleg | bijdragen) heeft de pagina Bristol (winkelketen) verwijderd (cyberpestactie van werknemer belastingdienst) (bedanken)” which translates as that it was deleted because of “Cyberbullying by an employee of the Taxation Service”, according to their official website (URL IS MODIFIED HERE TO AVOID SPAM FILTER, THE ORIGINAL URL IS com/aclick AND THE MODIFIED URL IS comFILTERaclick there are 210 Bristol stores in the Benelux which is much more than some other similar stores covered on the Dutch-language Wikipedia (nlwiki), on the English-language we have the “salted” article “w:en:Ulefone”, which is related to the Wikimedia Commons category “Ulefone”, which has these reasons for deletion:
- "21:31, 9 September 2017 Premeditated Chaos (talk | contribs) protected Ulefone [Create=Require administrator access] (indefinite) (Repeatedly recreated) (hist) (thank)"
- "21:31, 9 September 2017 Premeditated Chaos (talk | contribs) deleted page Ulefone (A7: Article about a company, corporation or organization, which does not credibly indicate the importance or significance of the subject) (thank)"
- "20:49, 9 September 2017 Fabrictramp (talk | contribs) deleted page Ulefone (G7: One author who has requested deletion or blanked the page – If you wish to retrieve it, please see WP:REFUND (TW)) (thank)"
- "20:37, 9 September 2017 Sphilbrick (talk | contribs) deleted page Ulefone (A7: Article about a company, corporation or organization, which does not credibly indicate the importance or significance of the subject) (thank)"
- However simple Ecosia searches for “Bristol (winkelketen)” and/or “UleFone” shows a large number of independent sources covering these subjects, notability standards on Wikipedia's are corrupt and can be easily manipulated by any admin by “salting” the pages and any user interested in writing about “a salted” subject will be discouraged from writing about it, furthermore I’ve seen countless of good neutral articles deleted because they were “promotional” or “spam”, but let's not delve too deep into the issues of other wiki’s and how local admins do influence what does and does not get covered as we have a similar situation with the interpretation of “Commons:Scope” here, the issue is that a Wikidatacentric approach will have to work with the standards of other Wikimedia websites, and although all other Wikimedia websites combined cover 54,055,172 content pages (as of 14:28 22 D. 01 M. 2019 A.), but some subjects will simply never be covered on the other Wikimedia websites, this can be because of a lot of factors other than just notability, admin interfere of content creation, overzealous “spam-hunting”, Etc. People could just not have an interest in a subject or all the information is either “burried/hidden away” in old newspaper clippings, just not online, it’s an obscure subject that only existed during the 1970’s in Botswana, Etc. There are many scenarios where something could be the subject of multiple photographs without it ever being covered on Wikidata, I don't believe that Wikidata could ever be the sum of all knowledge (not under Deletionism and Exclusionism, anyway) and sure the current category system solves this, but aren’t structured data “items” supposed to be independent from the MediaWiki category and organisational system? Having a system independent system for organising the content on the project (Wikimedia Commons) that works well together with Wikidata but has the space to be flexible enough to organise things outside of the scope of Wikidata and other Wikimedia websites would be a better option than outsourcing everything to Wikidata, it limits the ability to actually structure the data on Wikimedia Commons.
- You simply can't walk through a major Dutch or Belgian city without seeing a Bristol shop, why should this subject not be noted when it's depicted while for example "w:nl:Scapino (winkelketen)" should. I'm not arguing that structured data shouldn't work with Wikidata, the point is that if something gets deleted off of Wikidata that is extensively covered here then we shouldn't let Wikidata "unstructure" the data here. Also Wikidata's notability doesn't cover any Wikimedia project, it specifically excludes Wikimedia Commons because Wikimedia Commons itself has no notability standards. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 14:03, 22 January 2019 (UTC)
Just use Wikidata if the data is needed across many entries, or write it out each time in the file data if it's not. If that's an issue on Wikidata, then that needs to be fixed on Wikidata. We don't need a second Wikidata here (or if you count structured data for files as a wikidata, then we don't need a third Wikidata). Commons is the media repository, Wikidata is the data repository. Thanks. Mike Peel (talk) 21:23, 22 January 2019 (UTC)
- Categories aren't media either, they just list what's depicted in the media which is why some files could be added to a large amount of categories while others only to a few, wasn't structured data promised to not be simply a collection of links to Wikidata per "Comment The first two logos were originally created for WikiProjects that directly sought to make Commons and Wikidata work together. But I am not sure that such a strong emphasis on Wikidata is necessarily appropriate for the structured data project. Wikidata can divide people; in particular, Structured Data is not a Wikidata "take over" of Commons; and in any case, much of the structured data will not be stored on Wikidata. So I would suggest a logo which does not explicitly reference Wikidata in this way. Instead, I am rather taken with the idea of the Structured Data bee. I would suggest putting the Structured Data Bee in the middle of the Commons logo, with the arrows reversed, so that the Bee is feeding Commons, which in turn is feeding the world. Jheald (talk) 23:01, 30 October 2017 (UTC)" from the page "Commons talk:Structured data/Get involved/Community focus group#How do we feel about a project logo?". Don't get me wrong, a better integration with Wikidata is vital for cross-wiki compatibility, but there is a reason why Wikidata has consistently worked for every other Wikimedia website and not for Wikimedia Commons, local problems might sometimes need local solutions. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:54, 22 January 2019 (UTC)
- You realise that Wikimedia Commons is now one of the main users of Wikidata, right? Thanks. Mike Peel (talk) 22:23, 22 January 2019 (UTC)
- Yes, for topics which are already on other Wikimedia websites, there is a reason why I can link "Category:Elephone" but I can't link
"Category:Oukitel""Category:Ziengs Schoenen" to Wikidata, Wikimedia Commons simply covers more subjects due to lower notability standards, only allowing users to tag what is depicted if it already exists on Wikidata does a major disservice to potential re-users who are looking for "less notable subjects". --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 22:29, 22 January 2019 (UTC)- Really? I just linked it to Ziengs (Q60887513). Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 20:39, 23 January 2019 (UTC)
- Yes, for topics which are already on other Wikimedia websites, there is a reason why I can link "Category:Elephone" but I can't link
- You realise that Wikimedia Commons is now one of the main users of Wikidata, right? Thanks. Mike Peel (talk) 22:23, 22 January 2019 (UTC)
I proposed to lower Wikidata's notability standards which would essentially solve this, however as that proposal is unlikely to pass we'll probably have to wait until the need is great enough to try to pass it again. As the developers are unlikely to create a parallel system locally on Wikimedia Commons for this, this conversation could best be archived. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:11, 27 February 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:11, 27 February 2019 (UTC)
Upcoming features
Is there a timetable for upcoming features and when we could test them on Beta Commons? Maybe this timetable could also be posted to the village pump so there would be more transparency between the community and the development of the Structured Data on Wikimedia Commons programme and more feedback could be used to improve these features before they officially launch. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 16:30, 25 February 2019 (UTC)
- Please see Commons:Structured data/Development, which is regularly updated by User:Keegan (WMF). Jean-Fred (talk) 16:55, 25 February 2019 (UTC)
- Indeed, keep an eye on that page. I need to update it at some point in the next day or two as depicts is pushed back slightly, due to some development surprises. I hope to have a beta test to provide by the end of the week. Keegan (WMF) (talk) 17:22, 25 February 2019 (UTC)
- Ah, well too bad that the file depicts will take a bit longer because they seem like a really useful feature, I can't wait to get my hands on them to try them out.
 --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:29, 25 February 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:29, 25 February 2019 (UTC)
- Ah, well too bad that the file depicts will take a bit longer because they seem like a really useful feature, I can't wait to get my hands on them to try them out.
- Indeed, keep an eye on that page. I need to update it at some point in the next day or two as depicts is pushed back slightly, due to some development surprises. I hope to have a beta test to provide by the end of the week. Keegan (WMF) (talk) 17:22, 25 February 2019 (UTC)
This was answered by "User:Keegan (WMF)". ![]() --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:19, 27 February 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:19, 27 February 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:19, 27 February 2019 (UTC)
Hiding captions
Let me get straight into the point:
How do I hide the captions from my view? Any CSS code I can put on my common.css to remove that element?
Thank you. — regards, Revi 10:59, 13 January 2019 (UTC)
- Found out the answer myself by looking at the above topic. For those who may be looking for this:
/** Initially posted by Mike Peel */
/** Just hiding captions */
.filepage-mediainfo-entitytermsview { display:none;}
/** Hiding "Structured Data" header */
.mw-slot-header {display:none;}
- — regards, Revi 11:04, 13 January 2019 (UTC)
- I thought original idea of Structured Data on Commons SDoC hereinafter (or a prototype of it I saw) was putting the SDoC section below the GlobalUsage or something like that. Is it me who has a wrong memory or has something changed thus creating this what the hell design? — regards, Revi 11:12, 13 January 2019 (UTC)
- @-revi: There are two gadgets available in your preferences now - one that hides it completely as per the css, and one that collapses it by default but lets you expand it again if you want. Thanks. Mike Peel (talk) 11:48, 13 January 2019 (UTC)
- Since I prefer codes on my local page rather than gadgets, thanks for letting me know but I will keep status quo. BTW, if possible, I want to force them to be H2, and moved to elsewhere (let's say, above Metadata section as prototype I recall was). Is it possible with CSS/JS? (Not asking you to do that but just wondering).
- I have no interest in using it as currently is (it just sucks) but with the modification to put them away from the top of the page, it would be usable. — regards, Revi 18:20, 13 January 2019 (UTC)
- @-revi: You can shrink it using e.g.
h1.mw-slot-header { font-size:1.5em;}. as far as I can tell, moving it to a different part of the page is something the WMF would have to do. Thanks. Mike Peel (talk) 19:29, 13 January 2019 (UTC) - I think you can move things around using JavaScript (but because personal JS is loaded at the end, it will "jump around") − see for example MediaWiki:Gadget-CategoryAboveAll.js which moves the category box at the top. Jean-Fred (talk) 21:17, 13 January 2019 (UTC)
- @-revi: captions certainly has some design issues that showed up in production that were not visible in testing. The team is working to identify the problems and push the fixes, I've made an update section that you can keep an eye on. Keegan (WMF) (talk) 17:57, 14 January 2019 (UTC)
- It would be very useful to make a list of what was missed in testing, so that the problems we had here are less likely to be replicated in the future. - Jmabel ! talk 22:32, 14 January 2019 (UTC)
- Oh of course, lists are being compiled and things will be shared. A majority of the issues following the release are bugs/design flaws that can only be surfaced from release into production; in most all software development there are limits to testing environments trying to replicate a live environment, with highly customized configurations, skins, javascript, css rules, abuse filters, etc. that come with all of the wikis.
- All these excuses aside, a new testing environment that will be better at finding things has been in the works for the past few weeks, and should be up and live in time for depicts and other statements testing in a couple of weeks or so. In theory, it will be very helpful in reducing bugs in production. Keegan (WMF) (talk) 00:01, 15 January 2019 (UTC)
- It would be very useful to make a list of what was missed in testing, so that the problems we had here are less likely to be replicated in the future. - Jmabel ! talk 22:32, 14 January 2019 (UTC)
- @-revi: You can shrink it using e.g.
- @-revi: There are two gadgets available in your preferences now - one that hides it completely as per the css, and one that collapses it by default but lets you expand it again if you want. Thanks. Mike Peel (talk) 11:48, 13 January 2019 (UTC)
The CSS element name must have been changed, given that I see the caption stuff despite the css hiding them. — regards, Revi 10:44, 16 February 2019 (UTC)
- @Keegan (WMF), you cannot quietly close the thread as if nothing happened. Don't treat us like a mockup testers (I really feel like I am the product) and use consistent CSS element name so I don't need to change it once more. — regards, Revi 01:26, 4 March 2019 (UTC)
- @-revi: My intention was not to "quietly close this thread as if nothing happened." I was reading through threads, seeing what was stale, and marking them for archive to clean up this page before we release depicts. Your continued presumptions towards me make me sad. Keegan (WMF) (talk) 17:10, 4 March 2019 (UTC)
- Hello @Keegan (WMF): well as you said that you were kind of new to the whole archiving thing, usually on pages like the help desk of WikiProject Korea the template {{Section resolved}} is only placed once the discussion has been... Well... Resolved, archiving inactive threads (which includes unresolved ones) happens after a certain amount of times, usually 7 (seven) days for a resolved one and here around two (2) months for an unresolved one. It's probably best to let the person who started the thread mark it as "resolved" or to let someone else mark it as "resolved" if the starter said that they had their enquiries answered. A stale discussion ≠ a resolved discussion. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:55, 4 March 2019 (UTC)
- I understand the tag can be removed by anyone, it says so right there on it, but that doesn't excuse what was said. In my opinion the issue is resolved as there is a gadget available for hiding captions, and the thread is stale as the situations have been resolved and there's nothing left to discuss. You don't need to "Well, actually" this. I stand by my statement about revi's lack of good faith in their comment removing the tag. Keegan (WMF) (talk) 18:23, 4 March 2019 (UTC)
- Also, I was saying I'm new to setting up an archive bot for a page myself, it's something I've ever done for my own talk page. As I enter my fifteenth year of being a Wikimedian, I'm not new to the archival process. Keegan (WMF) (talk) 18:39, 4 March 2019 (UTC)
- @Keegan (WMF): , pardon, I did not mean to question your seniority in any way and I am fully aware that you are "w:en:User:Keegan", a veteran to the project. I just meant that -revi didn't find this thread sufficiently resolved but as the ability to properly hide file captions has been introduced (as our colleague Alexis Jazz 🎺 explained below) I can fully understand your actions. I just do not think that "User:-revi" is sufficiently satisfied with the current situation of file captions on Wikimedia Commons and wants more solutions to be brought forth in this specific thread. Personally I'd like to see more technical discussions directed to the technical village pump and it might be handy to direct people there once file depicts rolls out for technical debate. (COI notice, I'm the bloke that proposed the creation of the VPT, so yeah I'm advertising it). --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:46, 4 March 2019 (UTC)
- Also, I was saying I'm new to setting up an archive bot for a page myself, it's something I've ever done for my own talk page. As I enter my fifteenth year of being a Wikimedian, I'm not new to the archival process. Keegan (WMF) (talk) 18:39, 4 March 2019 (UTC)
- I understand the tag can be removed by anyone, it says so right there on it, but that doesn't excuse what was said. In my opinion the issue is resolved as there is a gadget available for hiding captions, and the thread is stale as the situations have been resolved and there's nothing left to discuss. You don't need to "Well, actually" this. I stand by my statement about revi's lack of good faith in their comment removing the tag. Keegan (WMF) (talk) 18:23, 4 March 2019 (UTC)
- Hello @Keegan (WMF): well as you said that you were kind of new to the whole archiving thing, usually on pages like the help desk of WikiProject Korea the template {{Section resolved}} is only placed once the discussion has been... Well... Resolved, archiving inactive threads (which includes unresolved ones) happens after a certain amount of times, usually 7 (seven) days for a resolved one and here around two (2) months for an unresolved one. It's probably best to let the person who started the thread mark it as "resolved" or to let someone else mark it as "resolved" if the starter said that they had their enquiries answered. A stale discussion ≠ a resolved discussion. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:55, 4 March 2019 (UTC)
- @-revi: My intention was not to "quietly close this thread as if nothing happened." I was reading through threads, seeing what was stale, and marking them for archive to clean up this page before we release depicts. Your continued presumptions towards me make me sad. Keegan (WMF) (talk) 17:10, 4 March 2019 (UTC)
- @Keegan (WMF): you should probably take lessons from the whole Jdforrester thing. (though this thread isn't nearly as bad) If you had put a note at the bottom of this discussion saying "Collapse Captions and Hide Captions gadgets are working again." the {{Section resolved}} may have been accepted.. - Alexis Jazz ping plz 19:09, 4 March 2019 (UTC)
Can file depicts help train artificial intelligence?
Soon structured data on Wikimedia Commons will manifest itself with “Depicts” which allows people to categorise images with tags that link to Wikidata pages. These “Depicts” are designed to list every subject depicted in the image and reminds me a bit of how Google Photos works, Google Photos is an online service which can categorise every image in its database by which subjects are depicted in it with mixed success. Because it relies heavily on bots that group images together into categories and is able to search 🔎 images based on what's depicted in them Google Photos is actually quite advanced in how it automatically organises videos and images. Now Google Photos as a service can be improved by humans by letting the software 👩💻 via the website "Crowdsource.Google.com" where human beings can help detect certain subjects and give feedback if they are or aren't in a photograph by going through categories. Now file depicts can potentially help software programmes like those in Google Photos to help recognise certain subjects as then us Wikimedia Commons volunteers will add tags as to what subjects are depicted in a photograph.
Now if let's say a company trying to develop image recognition software wants to utilise the data generated through file depicts, could they realistically utilise this data to help train their software? Of course this is a question for years in the future as most files won't have any depicts during "the transitional period"/"the introductory period", but as a long time goal, would they actually be useful for such purposes? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 02:13, 5 February 2019 (UTC)
- I would think that (in theory) it should be roughly exactly as useful as categories. Whichever approach does a better job will be that much more useful to AI. - Jmabel ! talk 03:26, 5 February 2019 (UTC)
- User:Donald Trung: I am already using Commons categories to train a neural network, and it works more or less, but I am hopeful that Structured Commons will make such tasks much easier. If I want to train a neural network that recognizes pictures of dogs, I will need around 10000 pictures of dogs, and Category:Dogs does not have that many pictures, so I will have to use sub-categories. Problem: Sub-categories include so many pictures that do not depict any dog, for instance everything in Category:Books about dogs, Category:Cynology, and even Category:Salt Lake City Intermodal Hub (because it has a Greyhound station). That makes automatic AI training impossible. On the opposite, "depicts" statements will be much more usable, and concepts link to Wikidata items, which is much easier to link with the rest of the open data world than categories. Cheers! Syced (talk) 02:20, 28 February 2019 (UTC)
- @Syced: this is exactly what I'm hoping for, websites such as TinEye, Microsoft Bing, and Google already use certain algorithms to find similar images based on colour, but Google Photos tries to take it even further by also recognizing what is actually depicted in the images, unfortunately Google Photos often misses the mark and while we can train it today with https://crowdsource.google.com/imagelabeler/category , it does not have a huge database of images where volunteers have already pre-explained the content of the images, I hope that in the future Wikimedia Commons could help train AI's, we were promised Skynet over a decade ago James Camerondammit, yet many computers still can't find puppies, how is a terminator supposed to target John Conner if it can't recognise his face? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 07:02, 28 February 2019 (UTC) (obviously the last sentence is in jest, just clarifying it in case anyone thinks that I'm an actual robot supremacist.)
- Commons could be the first beneficiary of accurate Wikidata items recognition in images: The upload tools could recognize objects in the uploaded image and suggest values for "depicts". This won't be doable for items that don't already have many depictions, though. Syced (talk) 14:26, 28 February 2019 (UTC)
Relevance of captions for internal / external search?
Wondering how the content of captions will influence the ranking when searching for images. Either through WP internal search or through third party external search (e.g. google). Can we use / misuse captions for SEO? Is there a policy about? best --Herzi Pinki (talk) 00:46, 15 February 2019 (UTC)
- My opinion is that captions should definitely be used for internal search. Whether it is used by search engines is beyond our control, but I don't think it can be misused that much (similar to descriptions for instance). Cheers! Syced (talk) 02:04, 28 February 2019 (UTC)
Commons: or Help: page for Depicts
Work is wrapping up for depicts, and there's a question about where to link to "Learn more" about depicts statements(design screenshot).
- Should the page point to the (currently non-existent) Commons:Depicts or Help:Depicts?
- Would someone like to create the preferred page with just some placeholder text until we have more information to publish there?
I've been steering away from creating pages in the community space, but I'm happy to do so if it's considered to be okay. Keegan (WMF) (talk) 17:33, 27 February 2019 (UTC)
- I think that we could probably have a help page and a policy/guideline page, right? Or do it like "Help:SVG" where "Commons:SVG" and "COM:SVG" are redirects. It's probably best to let "the community" create them after launch, though it would be wise to post this to the village pump (Mobile 📱) so more eyes will see it first. File captions is at "Commons:File captions" for reference. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:23, 27 February 2019 (UTC)
- Oh yes, I'm absolutely for the community creating the policy after the feature launches, and definitely promoting such a page on the village pump is part of the plan. I learned from the captions launch that I did not emphasize the necessity of the page enough, only a few passing mentions, because it took a day or two for the page to be created (thanks, Jean-Fred!) after captions launched. What we do have now is a chicken or the egg situation, where we need to know what to page to link "Learn more" to, but the community preference is to settle on a name once the feature is launched.
- We can go head and have it link to Commons:Depicts and let redirects take care of the rest if the community decides on a different page name, but I want to make sure it's okay as an idea with y'all first, at least. Keegan (WMF) (talk) 19:42, 27 February 2019 (UTC)
- I think that we need to take a step back and not really look at how the most active users look at it but how the noobs look at it. If you were to give a 12 (twelve) year old the assignment to upload a file to Wikimedia Commons and let them discover everything in the fields, is everything clear to them? As they might not understand file depicts immediately having (even a rudimentary) informational page would be very desirable, people started only talking about file captions when they didn't get it, so the question is, should the product be launched before the manual? I'd say that a draft could be created at a theoretical "Commons:Structured data/How depicts work" or "User:Keegan (WMF)Depicts" which could then be copied to the "Help:"/"Commons:" space to accompany the launch of the feature. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:05, 27 February 2019 (UTC)
- @Donald Trung: I'm planning on writing up a short how-to for depicts as I did for file captions on MediaWiki.org, as mw.org is the "canon" host for documentation. It's free to be ported over here to accompany the release. However, the Commons documentation should provide some sort of policy in addition to how to simply use the thing, and that's where the community comes in to draft the policy.
- So...yes, I'm happy to write up help and will be doing so, the only question that remains here is: where do we anticipate parking things, so that the developers can go ahead and code in a link? The link can be changed both through redirects here and, if needed, patches to fix in the back end. We simply need a place to start :) Keegan (WMF) (talk) 21:11, 27 February 2019 (UTC)
- I think that we need to take a step back and not really look at how the most active users look at it but how the noobs look at it. If you were to give a 12 (twelve) year old the assignment to upload a file to Wikimedia Commons and let them discover everything in the fields, is everything clear to them? As they might not understand file depicts immediately having (even a rudimentary) informational page would be very desirable, people started only talking about file captions when they didn't get it, so the question is, should the product be launched before the manual? I'd say that a draft could be created at a theoretical "Commons:Structured data/How depicts work" or "User:Keegan (WMF)Depicts" which could then be copied to the "Help:"/"Commons:" space to accompany the launch of the feature. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:05, 27 February 2019 (UTC)
 Done I went ahead a made a stub at Commons:Depicts. I don’t see why we could not expand it with basic and less-basic information ahead of the launch, as it will be clear that this is not available yet. Jean-Fred (talk) 08:08, 28 February 2019 (UTC)
Done I went ahead a made a stub at Commons:Depicts. I don’t see why we could not expand it with basic and less-basic information ahead of the launch, as it will be clear that this is not available yet. Jean-Fred (talk) 08:08, 28 February 2019 (UTC)
- Thanks. There will be some conversation in the future about whether to provide "Learn more" links for every statement type, or to bundle them all together into a general information page about statements, but depicts solves the problem we have right now. Much obliged. Keegan (WMF) (talk) 17:16, 28 February 2019 (UTC)
Implementing "depicts" in an upload app
Dear all,
I maintain an app used to upload pictures to Commons. I am starting to implement "depicts", and would appreciate some feedback. Here is my vision of how my app will look like in 6 months:
Upload:
- The user picks a local picture they want to upload.
- The user is asked to enter a caption and description (in their own language).
- The app shows a screen that says "What does your picture depict?" with a search field. When the user types "tokyo tow" they see the matching Wikidata items such as https://www.wikidata.org/wiki/Q183536 (actually what they see is the captions of these items, in their own language).
- They can choose several. Actually, a few items appear as suggestions: items used recently, items whose label matches the entered caption/description, items geographically close to where the picture was taken.
Search:
- The user goes to the search screen.
- The app suggests some popular items such as Q183536 (Tokyo Tower), in the user's language.
- The user can also search textually for items by label, in the user's language.
- The user taps on an item.
- A few result images appear at the bottom of the screen (scrolling makes more appear automatically). At the same time, at the top of the screen the suggestions change to show the items that are most depicted in images that also depict the Tokyo Tower, for instance Zojoji and Night.
- The user can tap on another item, the search will show images that depict both items, for instance images that depicts both Tokyo Tower and Night. The suggestions change to show items that are most depicted in images that also depict the Tokyo Tower and Night, for instance Illumination.
- Tapping more items refines the suggestions again.
- No "OR" operation is allowed, only "AND".
What do you think about it? Anything to improve, anything that would not work? Thanks! Syced (talk) 04:15, 28 February 2019 (UTC)
- @Syced: Please understand that Commons does not host photos of the Eiffel Tower lit up at night (except any photographed by the lighting designers) because the lighting designs are above TOO in France. — Jeff G. ツ please ping or talk to me 18:54, 28 February 2019 (UTC)
- That's sad news, thanks for the tip :-) I changed the example. Syced (talk) 02:29, 1 March 2019 (UTC)
- @Syced: You're welcome. — Jeff G. ツ please ping or talk to me 12:51, 1 March 2019 (UTC)
- That's sad news, thanks for the tip :-) I changed the example. Syced (talk) 02:29, 1 March 2019 (UTC)
Wikitext
Just curious, but why can't descriptive information from Wikitext "Descriptions" and "Categories" be harvested to create structured data? Licenses could be harvested right? Then why can't a bot harvest vital user-generated information from both native descriptions and organization? It just seems like a major handicap that existing Wikitext on over 50.000.000 (fifty million) media files can't be utilised. ![]() --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 10:14, 13 January 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 10:14, 13 January 2019 (UTC)
- Sure, technically, they could be harvested. If we, the Wikimedia Commons community, want to do that, then we could have bots do that. We could hardly do that though before captions were available. (I guess there could have been a soft launch with "captions available but invisible and only editable by bots", but personnally I don’t think this was necessary − Wikidata also launched pretty much empty, and the community went on to make bots that seeded it).
- Also, I don’t think that this is the job of WMF to do it − fairly sure that had the WMF done something like that, there would have been outrage that they’re touching the content. Jean-Fred (talk) 12:25, 13 January 2019 (UTC)
Sufficiently answered. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 09:50, 5 March 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 09:50, 5 March 2019 (UTC)
Mobile glitch? (repeated file captions)
-
 This issue persists on "the "mobile version" but not "the desktop version".
This issue persists on "the "mobile version" but not "the desktop version". -
 This issue persists on "the "mobile version" but not "the desktop version".
This issue persists on "the "mobile version" but not "the desktop version".
_01.png)
_02.png)
Is anyone else seeing file captions double on "the Mobile 📱 version" of Wikimedia Commons? I noticed this recently but I don't see it using "Desktop view". --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:24, 10 February 2019 (UTC)
- I notice the same behavior than you. Please note that the problem seems to exist only for the English caption, not for the other languages. --Dodeeric (talk) 18:04, 10 February 2019 (UTC)
- Correction / precision to my previous answer: the caption which is shown in double is the one with the same language as the interface. If your interface is in English, it is the English caption which is shown in double; if the interface is in French, it is the French caption which is shown in double, etc. --Dodeeric (talk) 08:04, 11 February 2019 (UTC)
- That's some rather odd behaviour, we should probably file a Phabricator ticket for this. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 08:09, 11 February 2019 (UTC)
- Hello. We are aware of these issues and are working on them, and you can track progress on this Phabricator ticket RIsler (WMF) (talk) 20:29, 11 February 2019 (UTC)
- Thanks, that saves us all some time. Keep up the great work developing these features.
 --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 07:52, 12 February 2019 (UTC)
--Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 07:52, 12 February 2019 (UTC)
- Thanks, that saves us all some time. Keep up the great work developing these features.
- Hello. We are aware of these issues and are working on them, and you can track progress on this Phabricator ticket RIsler (WMF) (talk) 20:29, 11 February 2019 (UTC)
- That's some rather odd behaviour, we should probably file a Phabricator ticket for this. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 08:09, 11 February 2019 (UTC)
I still see the glitch (for now), but this is being handled on the Phabricator so I'm marking this section for archiving. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 13:54, 5 March 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 13:54, 5 March 2019 (UTC)
Archive bot for this page?
This page is going to continue to be busy over the course of the year as we release features. I'm thinking about setting up archive bot as we've previously been archiving this page by hand, but I'm curious about how long we think is appropriate to keep threads around. One week? Two weeks? A month? Often times the topics are good to keep around so that people don't keep creating new ones, but on the other hand the threads get stale and sometimes a new subject is warranted. Thoughts? Keegan (WMF) (talk) 21:05, 25 February 2019 (UTC)
- I
 Support this and actually wanted to request something like this some time ago, but then the radio went silent for a week or so, but yeah, the reason why the archiver bot didn't need to run as often before was because of the low traffic to this page and keeping feedback requests open for a long time was desirable, however as the file captions feature was implemented traffic increased because instead of just those of us who were interested in the Structured Data on Wikimedia Commons (SDC) programme coming here, everyone was suddenly experiencing SDC features (and bugs 😒) so the level of discussion increased. As the file depicts feature will roll out soon the number of discussions here are likely to "explode" as well, so it would be desirable to archive older discussions more frequently. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:48, 25 February 2019 (UTC)
Support this and actually wanted to request something like this some time ago, but then the radio went silent for a week or so, but yeah, the reason why the archiver bot didn't need to run as often before was because of the low traffic to this page and keeping feedback requests open for a long time was desirable, however as the file captions feature was implemented traffic increased because instead of just those of us who were interested in the Structured Data on Wikimedia Commons (SDC) programme coming here, everyone was suddenly experiencing SDC features (and bugs 😒) so the level of discussion increased. As the file depicts feature will roll out soon the number of discussions here are likely to "explode" as well, so it would be desirable to archive older discussions more frequently. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:48, 25 February 2019 (UTC)
- I would also suggest adding the
{{Resolved}}{{Section resolved}} template to discussions which are resolved for more efficient archiving. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:50, 25 February 2019 (UTC)
- I would also suggest adding the
- @Donald Trung: It appears only SpBot understands that template, and it would have to be activated by the use of {{Autoarchive resolved section}} with appropriate parameters. — Jeff G. ツ please ping or talk to me 13:51, 26 February 2019 (UTC)
- @Jeff G.: yep, it's already being utilised at the pages "Commons talk:WikiProject Korea" and "Commons:Help desk" so there is precedent, especially if some (lengthy) conversations will be resolved. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 14:01, 26 February 2019 (UTC)
- Support, I suggest starting at a month. — Jeff G. ツ please ping or talk to me 11:29, 26 February 2019 (UTC)
- Support Sounds good. 1 month is fine by me, we can refine later :) Jean-Fred (talk) 12:50, 26 February 2019 (UTC)
- Maybe 2 months is better, given the age of the latest roadmap (#Captions updates from 18 January). — Jeff G. ツ please ping or talk to me 13:34, 26 February 2019 (UTC)
- I would say 2 month are okay if we mark newer resolved topics(like Commons_talk:Structured_data#How_to_edit_a_caption) as resolved and archive them after 7 days. --GPSLeo (talk) 15:01, 26 February 2019 (UTC)
- Maybe 2 months is better, given the age of the latest roadmap (#Captions updates from 18 January). — Jeff G. ツ please ping or talk to me 13:34, 26 February 2019 (UTC)
Hey Keegan (WMF), shouldn't we also add :
{{Autoarchive resolved section |age=7 |archive='((FULLPAGENAME))/Archive/((year))' |show=yes |level=2 }}
To the top of the page? A lot of basic questions could arrive here and most people would probably know to look in the archives. This would also enable the template {{Section resolved}} to work. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 06:50, 27 February 2019 (UTC)
- Done. Thanks for the tips, I've only ever archived my talk page by hand so it's all new to me :) Keegan (WMF) (talk) 17:14, 27 February 2019 (UTC)
As I'm not sure if the "{{Resolved}}" template will be readable by the SPBot I added the "{{Section resolved}}" template below. Cheers. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 13:52, 5 March 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 13:52, 5 March 2019 (UTC)
MediaInfo entities RDF representation
Hey, I have written a first draft of a proposal for an RDF representation of MediaInfo entities with additional data from the MediaWiki files metadata. After a discussion/improvement phase, if the dev team is ok with it, I could submit some changes to the MW extension to emit this format, just like I did for WikibaseLexeme. Tpt (talk) 13:06, 5 March 2019 (UTC)
- Interesting, thank you. I'll pass it along. Keegan (WMF) (talk) 19:19, 5 March 2019 (UTC)
- @Keegan: Any idea what the current hoped-for landing date is for getting a version of WDQS live that includes CommonsData ? Jheald (talk) 22:41, 5 March 2019 (UTC)
- @Jheald: I do not know at this time. I'll be sure to post here when it is. Keegan (WMF) (talk) 17:15, 6 March 2019 (UTC)
- @Keegan: Any idea what the current hoped-for landing date is for getting a version of WDQS live that includes CommonsData ? Jheald (talk) 22:41, 5 March 2019 (UTC)
Usage of "depict" in edge cases
Everytime I upload a picture, I try to think about Wikidata items it depicts. I usually can find good ones (existing or not yet), but I encountered two subtle cases so far, and added them at the end of the Commons:Structured_data/Get_involved/Feedback_requests/Interesting_Commons_files#Others section.
Briefly said, it is:
- An industrial machine with a prominent "Made in Wolverhampton". What is its relationship with Wolverhampton?
- A "we have moved" notice. What relationship?
I would love to see your depictions about these. By the way, we should really write down ideal metadata for all images on that page, to make sure we have a clear idea of what we want. Cheers! Syced (talk) 03:02, 13 March 2019 (UTC)
Development update, March 2019
Greetings,
I will likely also be sending this message out to the Structured Data focus group, so my apologies in advance if you're going to see this twice.
A development update for the current work by the Structured Data on Commons team:
After the release of multilingual file captions, work began on getting depicts and other statements ready for release. These were originally scheduled for release in February and into March, however there are currently two major blockers to finishing this work (T215642, T217157). We will know more next week about when depicts and statements can likely be ready for testing and then release; until then I've tentatively updated the release schedule.
Once the depicts feature is ready for testing, it will take place in two stages on TestCommons. The first is checking the very basics; is the design comfortable, how does the simple workflow of adding/editing/removing statements work, and building up help and process pages from there. The second part is a more detailed test of depicts and other statements, checking the edge-case examples of using the features, bugs that did not come up during simple testing, etc. Additionally we'll be looking with the community for bugs in interaction with bots, gadgets, and other scripts once the features are live on Commons. Please let me know if you're interesting in helping test and fix these bugs if they show up upon release, it is really hard to find them in a test environment or, in some cases, bugs won't show up in a testing environment at all.
One new thing is definitely coming within the next few weeks, pending testing: the ability to search for captions. This is done using the inlabel keyword in search strings, and will be the first step in helping users find content that is specifically structured data. I'll post a notice when that feature is live and ready for use.
Thanks, let me know if you have questions about these plans. Keegan (WMF) (talk) 18:16, 8 March 2019 (UTC)
- I wonder how we can advocate search in Captions? Is it better than search in description? Juandev (talk) 11:28, 13 March 2019 (UTC)
Does anyone else ever get this? Having to agree three times
.png)
Sometimes when I upload images on Google Android using the Ecosia browser I get this (see the attachment 📎), this also occurs on Microsoft Edge (Microsoft Windows 10 Mobile) from time-to-time but less often. Is anyone else experiencing this as well? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 14:09, 12 March 2019 (UTC)
- I've filed a task for investigation. Keegan (WMF) (talk) 21:00, 12 March 2019 (UTC)
- Thanks, but I've rather wanted to know if I am not the only one before filing a task on the Phabricator. I'd rather not have too much volunteer time or resources invested into an issue that only mildly affects me if no-one else complains about it. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 21:02, 12 March 2019 (UTC)
This gets now tracked on the Phabricator so I'm marking it for archiving as it's best to keep the discussion centralised. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:53, 13 March 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 11:53, 13 March 2019 (UTC)
Newsletter not showing up
For some reason I don't get the Structured Data on Wikimedia Commons newsletter despite registering for it a couple of years ago, I had to manually copy it to be reminded of the upcoming developments. How come that I didn't get it? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 09:23, 13 March 2019 (UTC)
- @Donald Trung: there are two message lists for this project, one for the newsletter and one for feedback requests and other information and input. I see that you are signed up for the first list but not the second, the second is where I sent the development update (as it wasn't a newsletter). The first list is for newsletters only and is delivered to a mix of individuals as well as village pumps. The second list is used to send directly to individuals and calls for feedback and input on testing and design, as well as other bits of information that are posted in here in the Structured Data hub. You're welcome to sign up if you'd like, though honestly you participate and watch here enough that you're not missing anything being sent to individuals other than convenience. Keegan (WMF) (talk) 15:45, 13 March 2019 (UTC)
- Lately I actually haven't been actively watching this page and I can't edit anything at the Meta-Wiki so if it's not some form of WP:PROXYING could you please add me to that list? Most of the time I watch my own talk page while I only occasionally watch "community" pages such as these unless there is an ongoing event. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 16:06, 13 March 2019 (UTC)
Thank you 😊. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 16:20, 13 March 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 16:20, 13 March 2019 (UTC)
After I express everything in Structured data, will I still need to find categories telling the same?
Let's say I took a picture, I set its location to "Lincolnshire", I set its "depicts" to "house" and the color of that house to "pink".
After entering that Structured data, will I still need to spend minutes finding the right category, which in this case would be "Category:Pink houses in Lincolnshire"? (after checking whether "Category:Pink houses in Lincolnshire in 2019" exists or not)
Or will such categories be converted, with all of their content getting Structured data, and finally the category getting removed? Or on the opposite, will such categories be automatically added to new uploads based on their Structured data?
Structured data will document a picture among several "dimensions" such as time/location/color/etc, maintaining categories for each possible combination of these dimensions sounds redundant to me.
Thanks for your insight! Syced (talk) 07:54, 16 March 2019 (UTC)
- @Syced: The answer to your headline question is: Yes. Categories will remain for the foreseeable future. The structured data experiment is being allowed on condition it doesn't mess up the existing ways of doing things. Undermining categories, or encouraging the addition of lots of material without proper categorisation, would be messing up the reliability and expectation of recall of the existing methods of retrieval in just such a way. It's also worth noting that for a long time to come, SDC will contain neither the coverage of data to replicate the retrieval that categories currently give, nor will it have the search methods to know that a pink house in Belton (Q4884760) should be retrieved as being in turn in Lincolnshire, or that searching for a judge means searching for a person with a particular occupation.
- Categories also often have the advantage of being natural units for curation and refinement, that can be annotated. I don't see Commons giving that up lightly.
- I would hope that one day there will be tools that will be able to automatically suggest or refine categories given particular structured data statements. But that won't be possible until we can easily record and retrieve what categories mean in terms of statements and Q-numbers. Until that point, therefore, categorisation will need to carried out by hand.
- But I would reiterate the point I made in the section immediately above. Commons expects uploaders to make a reasonable attempt at decent categorisation. Uploaders that do not make such attempt, including large-scale upload projects, can expect to be blocked until they start to make such an effort. SDC will not materially change this. Jheald (talk) 09:26, 16 March 2019 (UTC)
- I see! I surely hope that Structured data's "Where" search field will be able to dig P131s (located in administrative), just like FastCCI does for categories. Searching for the string "judge" should indeed show you pictures that depict Q16533 (judge) or pictures of items that have Q16533 as the value of any of their properties (easier said than done). Cheers! Syced (talk) 12:59, 16 March 2019 (UTC)
- On the other hand, if/when Wikidata people finally manage to destroy categorization altogether (with possible prior syphoning off some of its data, to be able to crow about it), then it will be even easier to dupe the innocent bystander about how great Wikidata is and how horrible was the old way, with all those untrendy nerds and their Monobooks and landscape aspect displays. Meanwhile we’re fighting a losing battle against an overhyped, overfunded foe. And to think that when it started Wikidata in Commons was seen as a way to enhance categorization, enabling interesting stuff like multilingual categories… -- Tuválkin ✉ ✇ 09:34, 16 March 2019 (UTC)
- @Syced: To be clear, I personally don’t expect you or anyone to add any categories, if you don’t feel like it. Another thing many people don’t understand is that in a wiki what one user wont do another might go ahead and do. -- Tuválkin ✉ ✇ 09:38, 16 March 2019 (UTC)
- @Tuvalkin: Understood, thanks! I always carefully categorize my uploads, but for the sake of the argument let's say that after taking a picture of a pink house in Lincolnshire, I put it into the categories "Lincolnshire", "Houses", and maybe even "Pink"... would you deem that as acceptable? It is a honest question. Thank you! Syced (talk) 12:59, 16 March 2019 (UTC)
- Much to my amazement, there is a Category:Pink houses in Lincolnshire (only one member so far) but if there weren't, then its non-meta parent categories would be the most appropriate: Category:Pink houses in the United Kingdom and Category:Houses in Lincolnshire. - Jmabel ! talk 02:43, 17 March 2019 (UTC)
- @Tuvalkin: Understood, thanks! I always carefully categorize my uploads, but for the sake of the argument let's say that after taking a picture of a pink house in Lincolnshire, I put it into the categories "Lincolnshire", "Houses", and maybe even "Pink"... would you deem that as acceptable? It is a honest question. Thank you! Syced (talk) 12:59, 16 March 2019 (UTC)
Captions for a GLAM audience
Hello everyone, In two weeks I'm meeting with a French museum who wants to upload their collections (including modern art <3) to Commons. The training will also feature several students in art history. How should I communicate around captions and structured data present and future in a way that is non-confusing, useful to them, and honest ? Léna (talk) 10:28, 14 March 2019 (UTC)
- @SandraF (WMF): I think you might be able to give some advice here? Keegan (WMF) (talk) 17:09, 14 March 2019 (UTC)
- On most modern art, won't there be copyright issues? Artists don't generally transfer their copyrights to those in physical possession of their works, museum or otherwise. - Jmabel ! talk 20:04, 14 March 2019 (UTC)
- Modern art started in the 1860s, so I guess a sizable proportion of it is now public domain :-) I actually took pictures of barely-known Picasso works that might become public domain in half a century, I will try to live old enough so that I can upload them one day ^_^ Back on the topic, my opinion is that good captions are the ones that can be used as-is as thumbnail caption in a Wikipedia article (but without the wikilinks), so I would have a look at https://en.wikipedia.org/wiki/Modern_art and realize that most of the captions are like "Black Square by Kasimir Malevich, 1915", so I would suggest constructing captions as "<artwork title> by <artist name>, <creation year>". I am not a specialist about artwork in Structured Commons so others should answer better than me, but my understanding is that they will have to find the artwork's Wikidata item (create a new one if none exists), link to it from the media with a "depicts" statement (not sure whether this is technically possible already or not) and fill the metadata (genre, artist, what it depicts, etc) at that item. Syced (talk) 09:14, 15 March 2019 (UTC)
- @Léna: The most brutal part of the process is probably going to be the data reconciliation.
- Given that these are museum-grade works of art, each one should probably each be getting a Wikidata item in its own right. That means you don't really need to worry about where the Structured Data project is at, you will be targeting Wikidata directly, a more developed and stable known quantity. There are some tools and workflows already developed for translating collection information into Wikidata items -- User:Multichill has done a lot of this work and created much of this, and can probably point you to wiki-help pages describing his workflow.
- First thing to do is to identify whether any of the collection already has Wikidata items -- probably not, but you never know. For almost all of the collection, though, you can probably assume you're going to need to be creating new items. These can start out as skeleton items at first, and additional information can always be added. But as a rule of thumb, as much as possible of what you want to present on the file description page for the object you should aim to be getting into its Wikidata item. Then when you upload images, you can build the file description pages based on the information on Wikidata, including using templates like {{WrapWD}} or {{Label}} to automatically generate linked internationalised strings for field entries based on the labels for items at Wikidata.
- As I wrote at the top, the biggest step in this is likely to be the data reconciliation -- in particular the creator names: does Wikidata already have an item for this creator? Does a new one need to be made? OpenRefine can help you a lot here, but it can still be quite a brutal process. Other fields will also need reconciliation -- eg places of creation, provenance, etc. Places can be surprisingly difficult to reconcile, because Wikidata may have multiple items for the same place in different roles, or multiple places with the same name. Also if you have any subject metadata -- eg genre, style, things depicted in the work -- those are also things to reconcile; and again, you may find new items need to be made.
- The good news is that good Wikidata reconciliation should make Commons categorisation more easy. For example, having identified the Q-numbers for your creators, you can extract with a query which ones already have a creator template here, which ones already have a Commons category, etc. If they don't have a Commons category, you should probably create one once you start uploading images.
- It's worth noting that SDC is not going to make filepages disappear, and it's not going to make the need for categorisation disappear, not even in the mid- to long-term. Uploading projects that don't do proper categorisation are likely to get blocked until they do. So categorisation is something to take seriously. You will need to identify the category structure in the areas of the different aspects of the kind of things you will be uploading, and you may need to refine it. Jheald (talk) 11:03, 15 March 2019 (UTC)
- @Syced: and @Jheald: , thank you for your answers, there is lot of information in them and I will take time to fully digest them properly because they will help me in my practice of mass uploads of GLAM collections. However, the crucial point of my question was missed :) I don't need technical information on how to do uploads or copyright laws, but a communication expertise on how to answer newbies questions around structured data such as "Why there is a structured data area in the Commons file page ?" or "How is it different from the Wikidata item and the description area ?" Léna (talk) 11:22, 15 March 2019 (UTC)
- @Syced: and @Jheald: , thank you for your answers, there is lot of information in them and I will take time to fully digest them properly because they will help me in my practice of mass uploads of GLAM collections. However, the crucial point of my question was missed :) I don't need technical information on how to do uploads or copyright laws, but a communication expertise on how to answer newbies questions around structured data such as "Why there is a structured data area in the Commons file page ?" or "How is it different from the Wikidata item and the description area ?" Léna (talk) 11:22, 15 March 2019 (UTC)
@Léna: For your communications goals, maybe you can find inspiration in some recent presentations about SDC? Check the video on the right for the session on SDC at the recent GLAM-Wiki conference. For captions, I would personally write something like Artist Name: Work Title (year), collection The Museum Collection - that will probably make it most discoverable, and it is very similar to how artworks are 'captioned' in books. There is not really a 'best practice' for this on Wikimedia Commons yet though, and I'd be very curious to hear what your museum contacts themselves would like to see! SandraF (WMF) (talk) 11:32, 15 March 2019 (UTC)
- @Léna: (ec) "Commons is going to have its own database like Wikidata, but with an entry for every image, rather than Wikidata, which might contain an entry for a particular object. It will be coming soon, and you can start to see the first signs of it, but it's not quite here yet. This will be in addition to the conventional description pages and categorisations, which images will continue to have." Jheald (talk) 11:35, 15 March 2019 (UTC)
- @Jheald: But the entries for the subjects will be in Wikidata, right? We already have entries for some photographs (e.g. [13]), so in these cases, there will be a duplicate. This is a rather confusing. Regards, Yann (talk) 10:28, 16 March 2019 (UTC)
- @Yann: Okay, so in the above, substitute instead the wording "Commons if going to have ... an entry for every file" -- i.e. each distinct digitised image with its own description page.
- Literally, "each distinct digitised image with its own description page" already was here before captions, they can only duplicate what exists. The only relevant caption I have seen this week on my uploads was for someone to caption an official photograph of a politician with "bollocks". Luckily as I have the 'captions feature' switched off, I can neither see it on the page, nor edit it. --Fæ (talk) 11:30, 19 March 2019 (UTC)
- Commons will hold information that is specific to the file. Information that relates to the work will be on Wikidata, if a Wikidata item for the work exists, as probably one should most of the artworks in the museum. Jheald (talk) 13:36, 16 March 2019 (UTC)
- @Yann: Okay, so in the above, substitute instead the wording "Commons if going to have ... an entry for every file" -- i.e. each distinct digitised image with its own description page.
- @Jheald: But the entries for the subjects will be in Wikidata, right? We already have entries for some photographs (e.g. [13]), so in these cases, there will be a duplicate. This is a rather confusing. Regards, Yann (talk) 10:28, 16 March 2019 (UTC)
- After lot of thoughts I'm going to present captions and structured data as an illustration that we are a small movement in term of financial power (why we stayed so many years building a multi-lingual database of multimedia files with a software built for a monolingual encyclopedia) and always evolving (why the structured data is only half-baked) in a complex legal environment (why captions were not generated at first : CC0 vs CC-by-SA and responsibility of content is on the community, not the host). Léna (talk) 11:19, 19 March 2019 (UTC)
Glossary
I've started a glossary for the project, based on Wikidata's glossary. All edits welcome, feel free to make new entries, etc. Similar guidelines will probably be helpful but we're just getting started. Keegan (WMF) (talk) 18:17, 22 March 2019 (UTC)
It would probably also be good to have a dedicated "{{Structured data}}" navigational template to link all pages related to Structured Data on Wikimedia Commons (SDC) to. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:20, 22 March 2019 (UTC)Nah, it would probably be better to add "Commons:File captions", and "Commons:Structured_data/Glossary" to "Commons:Structured data/Navbox" and then add the latter to the bottom of those pages. Also to "Commons:Depicts". --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:33, 22 March 2019 (UTC)
- I really don't want to be a Nagging Nancy, but there's already another glossary, I propose that the newer one should best only be used for launched features such as file captions, statements, file depicts, Etc. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:39, 22 March 2019 (UTC)
- Ha, I totally forgot about that glossary, but yes they do appear different in scope. The /About one is more high-level to the organization of the project and work, the "new" one is more technically oriented towards features. I'll get links and descriptions for the pages organized next week. Keegan (WMF) (talk) 20:52, 22 March 2019 (UTC)
- Okay, we now have the
- Structured Data on Commons project glossary, information about the software project to put Wikibase on Commons and develop features to work with it.
- Structured data features glossary, information about the terminology used in the structured data features on file pages.
- That should take care of it. Keegan (WMF) (talk) 21:01, 22 March 2019 (UTC)
- Okay, we now have the
- Ha, I totally forgot about that glossary, but yes they do appear different in scope. The /About one is more high-level to the organization of the project and work, the "new" one is more technically oriented towards features. I'll get links and descriptions for the pages organized next week. Keegan (WMF) (talk) 20:52, 22 March 2019 (UTC)
Early depicts testing
The Structured Data on Commons development team has the very basic version of depicts statements available for early testing on Test-Commons. You can add very basic depicts statements to the file page by going into the new “Structured Data” tab located below the "Open in Media Viewer button." You can use the Latest Files link in the left side nav bar to select existing images, or use the UploadWizard to upload new ones to test with (although those images won’t actually show up on the site). The test site is not a fully functional replica of Commons, so there may be some overall problems in using the site, but you should be able to get a general idea of what using the feature is like.
Early next week I will call for broad, community-wide testing of the feature similar to what we did for Captions, with instructions for testing, known bugs, and a dedicated space to discuss the feature as well as a simple help page for using statements. Until then, you're welcome to post here with what you might find while testing depicts.
Thanks in advance for trying it out, you'll be hearing more from me next week. Keegan (WMF) (talk) 21:28, 21 March 2019 (UTC)
- Looking promising! At [14], the 'structured data' tab appears, but it's not possible to select it (at least when browsing while logged out). It works OK at [15], so presumably it depends on whether a depicts statement already exists or not (and anon editing at that page works OK). At that second link, how can we get the primary depicts ID into the artwork template? Thanks. Mike Peel (talk) 21:45, 21 March 2019 (UTC)
- Both works to me. Juandev (talk) 22:00, 22 March 2019 (UTC)
- I do not got a way do add depicts in the upload wizard and images do not get displayed with the message "Unauthorized This server could not verify that you are authorized to access the document you requested." But adding depicts to uploaded files works. --GPSLeo (talk) 22:40, 21 March 2019 (UTC)
- That is probably because upload was not set. If developers want us to test it via uploadWizard, they should link it from the Upload file link in the menus below the logo.Juandev (talk) 22:00, 22 March 2019 (UTC)
Test-Commons do not seem to be working properly, at least I can't see any file over there (all seem to be broken).-- Darwin Ahoy! 00:38, 23 March 2019 (UTC)
References & deprecation & more
After hitting "random file" enough times, I finally found a file with a 'structured data' tab that worked: https://test-commons.wikimedia.org/wiki/File:Godward_Idleness_1900-dupe!.jpg
A couple of points: Statements ought to be referenced, or to have the capability to be referenced. If the information has been imported from a GLAM's catalogue, it should be possible to record that sourcing on the statement. If a given authority says that an image is of a particular species of plant, it should be possible to reference that authority.
However, imported data can also be wrong -- for example, an engraving that was previously thought to be of A, but is now known to be of B. It needs to be possible that people used that the image depicted A, because otherwise people may find and add this information; but it also needs to be possible to record that the statement is wrong, by showing that it is deprecated.
Next: on this image we're showing it as depicts (P180) Idleness (Q19953492), but also depicts (P180) kitten (Q147), girl (Q3031). The latter statements really shouldn't be on Commons -- or at least, not shown as local -- if they can be inherited from Idleness (Q19953492) on Wikidata.
Finally, looking at the page full-screen on a widescreen laptop (my normal web-browsing mode), there is a vast gulf in the middle of the page between the labels on the left of the things depicted, and the right hand side with links and 'make primary'. This doesn't feel like good design. Surely there should be a maximum on the width of this panel? A mouse-over tooltip to explain that 'Idleness' is a 'painting by John William Godward' (its Wikidata description) would probably be useful too, otherwise (i) just the bare word people might find quite confusing, and (ii) so that somebody who does mouse-over can easily confirm that the statement has been properly coded it is Idleness (Q19953492) and not idleness (Q16323159) that the statement relates to.Jheald (talk) 22:47, 21 March 2019 (UTC)
- I think these image should not get any depicts (P180) for images like this there should only digital representation of (P6243) be used. --GPSLeo (talk) 22:54, 21 March 2019 (UTC)
- Personally I would agree, but if we take that view we should impose it (and make it work) right from the start. I really don't want to be having to search for and clean up a load of bad data down the track "because it was added in an early version". Jheald (talk) 23:00, 21 March 2019 (UTC)
- I'd prefer to keep things simple: just say "this depicts this object" (where that object has a Wikidata item), and we can go from there. digital representation of (P6243) was a bad idea and should be deleted (it's now at d:Wikidata:Properties_for_deletion). Thanks. Mike Peel (talk) 23:50, 21 March 2019 (UTC)
- Personally I would agree, but if we take that view we should impose it (and make it work) right from the start. I really don't want to be having to search for and clean up a load of bad data down the track "because it was added in an early version". Jheald (talk) 23:00, 21 March 2019 (UTC)
- Hello all. Thanks for testing this feature early. I'll take this opportunity to address a few of the points brought up here. First, as far as depicts vs. digital representation of, this is an ongoing debate within the community and we encourage everyone to continue to work together towards a model/policy that makes sense for Commons. The development team intend to support both properties. In the case of artwork, there are some potential issues with duplicating information that is already stored in a Q item on Wikidata, which is why some time ago we started work on a feature we called 'depicts of depicts', which would essentially "import" depicts data from any depicted artwork that had its own depicts statements on Wikidata. That import was only stored in the search index for the file, and displayed in the file page UI in a special way, but never actually added to the MediaInfo item on Commons. This work (detailed in this ticket) pre-dated the creation of the 'digital representation of' property and the desire of some community members to model the situation differently. We are looking into repurposing our original plans so that they work with the new property. This could potentially be part of the later release where we launch support for all statements. In regards to support for references and deprecation - our initial rollout will not support these features as we need to learn more about real usage in this new context on Commons. References and deprecation are confusing and often inaccurate systems on Wikidata already and we didn't want to introduce those same problems here without putting a lot of thought into the design. We appreciate ideas and feedback as we gradually introduce all these new concepts to Commons. Finally, in a patch that will arrive before we release depicts support, we'll adjust the width of the field so when viewing in fullscreen things won't be terribly spaced out (ticket here). Thanks, as always. RIsler (WMF) (talk) 01:32, 22 March 2019 (UTC)
- @Jheald: deprected? Why? Why not you change wrong item, with the correct one? Or use a different property something like "wrong identification" XY date 2013?
- kitten (Q147), girl (Q3031) shouldnt be on commons? I think the opposite. Idleness (Q19953492) is actually name of the file, so I would set items, which are obvious = painting, woman, cat.Juandev (talk) 22:11, 22 March 2019 (UTC)
Do not roll out only depicts (P180) without any way to add other statements
I think if the structured data gets rolled out only with the option to add statements with depicts (P180) people will start to add the location in these field. I think we only want what the image depicts there and information about the location in an other field like location (P276) or located in the administrative territorial entity (P131). May this could be corrected later by a bot, but I think it would be better to never let people start to misuse depicts (P180). The topic of above is likely about the same issue. --GPSLeo (talk) 23:06, 21 March 2019 (UTC)
- Most of that information should be stored on Wikidata, not here. Mike Peel (talk) 23:57, 21 March 2019 (UTC)
- Hello, all. Thanks for the feedback. We are looking forward to more of these discussions within the community about how P180 "should" be used. What if, for instance, I have a scan of a postcard of Paris? Is it wrong for me to say depicts: Paris ? It would certainly be wrong to say location: Paris, especially if I wasn't in Paris when I took the photo. So what's the "right" way to do it? We have to account for many Commons use cases, and using Wikidata-style structured data to model multimedia is kind of a new thing, so there is much for everyone to learn and discover. With that said, there will certainly be rules for depicts that the community decides upon at some point. We are leaning towards the community using AbuseFilter to enforce those rules, much like Wikidata does in some cases already. RIsler (WMF) (talk) 03:08, 22 March 2019 (UTC)
- I don't think you can say "It would certainly be wrong to say location: Paris". Photographs have a location associated with the position of the camera, and we can also give a location for the depicted subject(s) (camera and subject locations). If you are scanning a photo on a postcard, the camera location of interest would be the camera location that created the original image. There may be other locations; the location where a photo was digitized is unlikely to be of much interest (although the person/organization that digitized it would be recorded); the location where an artist painted a picture (maybe in their studio) could also be different to the point of view of the painting. We do have categories for images that "depict Paris", namely under Category:Views of Paris. --ghouston (talk) 03:19, 22 March 2019 (UTC)
- Hello, all. Thanks for the feedback. We are looking forward to more of these discussions within the community about how P180 "should" be used. What if, for instance, I have a scan of a postcard of Paris? Is it wrong for me to say depicts: Paris ? It would certainly be wrong to say location: Paris, especially if I wasn't in Paris when I took the photo. So what's the "right" way to do it? We have to account for many Commons use cases, and using Wikidata-style structured data to model multimedia is kind of a new thing, so there is much for everyone to learn and discover. With that said, there will certainly be rules for depicts that the community decides upon at some point. We are leaning towards the community using AbuseFilter to enforce those rules, much like Wikidata does in some cases already. RIsler (WMF) (talk) 03:08, 22 March 2019 (UTC)
Points by Juandev
Hey, thank you for providing us a testing environment. I have few proposals and questions regarding that:
- Do we plan other statements than depicts? e.g. objec location, which is the part of broader object - eg painting Mona Lisa stays in Louvre gallery
- Would you enable quelifiers to depicts items?
- How we will use "depicts" for audio files? Probably same way, but than depicts sounds misleading.
- Would be interesting to connect depicts items with image area layers. Let say, there is the panorma of the city and today we can describe different depicted object to the image (maybe extension imagearea could be used also). So it would be interesting to somehow connect both data.
- How to fill depicts, when the mane motive of the image is unknown - such images are also hosted in WMC and they are set to categories like Unidentified X? One sollution might be to set the closes item. So if I have unidentified plant the item might be "plant", if U object, item "object". But I thing this is not the right way.
- Simmillar question would be non-existent item. Why we cannot set nonexistent values on Wikidata?
- hard to find right item - when there are more items of the same name - provide thumbnail from wikidata? This problem is picky even on the Wikidata itself if you have a lot of items of the same name.
- and I would redisegn that dropdown menu with items. Its pretty wide, which is mostly not needed, but unecesarry thick
Juandev (talk) 21:53, 22 March 2019 (UTC)
- I add one point here:
- Do we want to say that an image like this depicts the Spandauer Forst (Q2306658) or do we want to say that that what is depicted is in (located in/on physical feature (P706)) Spandauer Forst (Q2306658)? --GPSLeo (talk) 10:07, 23 March 2019 (UTC)
- Thanks, Juandev. I can answer 1-3 at the moment.
- Other statements will be released soon
- Qualifiers will be enabled, yes
- "Depicts" might not be right for audio, the solution is not settled yet
- I hope to be able more questions with time, as many do not have firm answers yet. Keegan (WMF) (talk) 17:25, 25 March 2019 (UTC)
Strange captions
Please see LauraHarvey45 contributions. The first diff to File:Backlit keyboard.jpg says
- "Image by Colin via Privacy Canada. A backlit laptop computer keyboard. Most fingers are on the “home” keys for touch-typing; the ‘U’ key is being pressed. Focus stack of 36 frame combined/retouched using Helicon Focus. Further retouching in Photoshop"
While "by Colin" might be fine, I have no idea what "Privacy Canada" have to do with it. Is that a website where my image is used? The next two sentences come from the keyboard description, but the focus stack sentences come from File:Philips Series 7000 shaver head.jpg. The rest of User:LauraHarvey45's contributions mention "Gun News Daily", presumably because that website uses those photos. Does anyone know what is going on?
Does Commons have a help page for Captions? For example, a Caption that was merely a title might be fine on Wikipedia where there is a link to the attribution page, but elsewhere would fail CC licensing terms for not including the author, the specific licence used, and urls/links. -- Colin (talk) 08:52, 25 March 2019 (UTC)
- Just a hint: Commons:File captions --XRay talk 11:39, 25 March 2019 (UTC)
- "Precise guidelines on file captions still have to be developed" :-(. I hope Commons Structured Data is planning to extract licence and attribution info in a structured way, so that automated full legal captions can be generated. I'd still like to know where the above caption info came from. -- Colin (talk) 15:01, 25 March 2019 (UTC)
- Meanwhile, common sense should apply. Don't hesitate to edit if you think you can improve it.
- In particular, certainly feel free to remove false information, and I don't see any reason the caption should mention the photographer unless the photographer is notable. - Jmabel ! talk 15:05, 25 March 2019 (UTC)
- What I'm concerned about is if there is some tool or website that causes such wrong captions to be created. -- Colin (talk) 15:58, 25 March 2019 (UTC)
- “I hope Commons Structured Data is planning to extract licence and attribution info in a structured way, so that automated full legal captions can be generated.” − yes, storing licensing information as structured data is very much on the SDC roadmap (see Commons:Structured data/Development for some more information).
- (that being said, licensing information is probably one of the area where our templating system kind-of-not-too-bad-sort-of-works − see COM:MRD for more information − and from which we should be able already to generate license-compliants by-lines [not using the word caption for this on purpose for clarity], as does the Help:Gadget-Stockphoto ; or the Commons:Attribution Generator [although it’s unclear to me how much it reimplements/hardcodes the MRD functionality…)P
- Regarding the captions here, I guess the best course of action is to ask the user how they wrote them.
- Jean-Fred (talk) 16:53, 25 March 2019 (UTC)
- "Precise guidelines on file captions still have to be developed" :-(. I hope Commons Structured Data is planning to extract licence and attribution info in a structured way, so that automated full legal captions can be generated. I'd still like to know where the above caption info came from. -- Colin (talk) 15:01, 25 March 2019 (UTC)
"Depicts" statements ready for testing and release
Copied over from the Village Pump
After the resolution of some technical blocks, the Structured Data on Commons team is ready to test and release support for statements on Commons, starting with the depicts property on the file page. Depicts statements are meant to be some of the simplest possible descriptors for a file. For example, File:Square_-_black_simple.svg contains what can be considered a depiction (P180) of a geometric square (Q164). I would like to emphasize that this first release of depicts statements is very, very simple and there is much more to come to build out the feature. Further support for depicts statements, such as in the UploadWizard and with qualifiers, will be released within the next few weeks after the initial support goes live here.
The development team is looking to make sure of design and functionality for adding, editing, and removing statements. The current plan is to test depicts on Test-Commons for a week to find potentially breaking bugs, do a systems test on Test Commons to discover configuration discrepancies, and then release live into production here on Commons. Once we release the software, there will be bugs that show up here on production Commons that did not or do not show up in testing; the team will work to document, triage, and fix these bugs. If all goes well, depicts will be turned on next week, during the week of 1 April'. I will post in advance which particular day the software will be turned on once that is determined.
Please help test depicts before it is released here. Testing information is available on this page, and you can leave your feedback on the test talk page. If your testing finds no major concerns or flaws that you'd like to comment on, please let us know that as well. Even a simple “Looks good to me” is helpful feedback. You must be logged in to test depicts; Test-Commons is tied to CentralAuth so your account here should work there without any action from you.
Additionally, any thoughts or concerns about gadgets or tools that might break because of this launch are appreciated so that the issues can be sorted out to be fixed. These community-developed resources are especially vulnerable to problems when new software is released live and we'd like to make sure people are looking out for them.
Thanks, let me know if you have any questions about the testing and release process. Keegan (WMF) (talk) 16:44, 26 March 2019 (UTC)
- Thanks for the info Anthere (talk)
- @Keegan (WMF): Probably not ready, see phab:T219450. This caused a serious issue on Commons. Much more testing is needed. Also to avoid the fiasco of captions. Thanks, Yann (talk) 16:07, 28 March 2019 (UTC)
- @Yann: phab:T219450 is a nasty bug indeed. It looks like it's being addressed and a patch is up to get things fixed. I want to be clear about this with you: there will very likely be bugs when we release into production here that we didn't find in testing/the test environment. We're introducing multi-content revision and federated Wikibase into industrial scale use for the first time ever, there's no way to mimic it in testing. I will continue to be clear about this, there should be no expectations that no bugs will show up. It's simply unrealistic. Things may break. If and when this happens the development team will be responsive and fix things. Keegan (WMF) (talk) 17:22, 28 March 2019 (UTC)
- @Keegan (WMF): Of course, there may be bugs on the new feature(s), but deployment should not break the existing environment. Regards, Yann (talk) 17:35, 28 March 2019 (UTC)
- What I'm saying is, with this project we're deploying software that adds a totally new framework to MediaWiki, it's not only working within MediaWiki, and here be dragons. It's impossible to know with 100% certainty with this software bundle nothing will break. The team is doing what it can to mitigate this, including breaking down the release into the most very basic parts, and it will respond to problems, but we're dealing with unknowns because this has never been done before here. Keegan (WMF) (talk) 17:46, 28 March 2019 (UTC)
- There is an old joke, we used to use an our example for responding to "middle management" about production quality issues on the factory floor. "We love quality targets. As you want a target of 3 failures this month, we have broken three units. Can we have our performance bonus early?".
- Of course, that joke was before so-called "Agile" development as understood uniquely in Silicon Valley, where people believe that breaking everything is good, and if they believe it hard enough it might be true. Alternatively, you could invest in reliable, credible, repeatable testing. --Fæ (talk) 18:02, 28 March 2019 (UTC)
- What I'm saying is, with this project we're deploying software that adds a totally new framework to MediaWiki, it's not only working within MediaWiki, and here be dragons. It's impossible to know with 100% certainty with this software bundle nothing will break. The team is doing what it can to mitigate this, including breaking down the release into the most very basic parts, and it will respond to problems, but we're dealing with unknowns because this has never been done before here. Keegan (WMF) (talk) 17:46, 28 March 2019 (UTC)
- @Keegan (WMF): Of course, there may be bugs on the new feature(s), but deployment should not break the existing environment. Regards, Yann (talk) 17:35, 28 March 2019 (UTC)
- @Yann: phab:T219450 is a nasty bug indeed. It looks like it's being addressed and a patch is up to get things fixed. I want to be clear about this with you: there will very likely be bugs when we release into production here that we didn't find in testing/the test environment. We're introducing multi-content revision and federated Wikibase into industrial scale use for the first time ever, there's no way to mimic it in testing. I will continue to be clear about this, there should be no expectations that no bugs will show up. It's simply unrealistic. Things may break. If and when this happens the development team will be responsive and fix things. Keegan (WMF) (talk) 17:22, 28 March 2019 (UTC)
- @Keegan (WMF): This is utterly unbelievable — both the technical mess up, and then the excuses. You guys are supposed to be professional developers, not geeks tinkering with stuff. Seems though we have all the bad aspects of the former (pandering to trends, sabotaging power users, corporate legalese, PR stunts) but none of the professionalism, plus all the bad aspects of the latter («Dude!, we totally trashed the whole rig, live!») yet none of the star-eyed idealism about building a better world in shortsleeves. -- Tuválkin ✉ ✇ 18:17, 28 March 2019 (UTC)
Depicts (P180) vs Digital representation of (P6243) ?
What is going to be the status of depicts (P180) versus digital representation of (P6243) ?
Presumably it's only P180 that will initially be available, but should editors be advised to hold off adding P180 to images if P6243 will be more suitable?
Is the development team aware of P6243, and is it intended that "depicts" searches will take it into account? Jheald (talk) 10:12, 28 February 2019 (UTC)
- P6243 is only for precise digitization of 2D artwork if I understand correctly? For instance if I take a picture of Mona Lisa from across the room I can not use P6243 right? Syced (talk) 12:48, 28 February 2019 (UTC)
- @Syced: Good question. I tried to ask it in the proposal discussion for P6243, but I'm not sure whether I ever got a clear answer. (What do you think?) Ultimately the meaning of the property will get defined by how it turns out to get used... with no uses yet, the boundaries may not be 100% clear. Jheald (talk) 13:29, 28 February 2019 (UTC)
- @Jheald: Yes, the dev team has monitored the evolution of P6243. As you mentioned, much depends on how community will actually use it. There are no current plans to include it in depicts searches. RIsler (WMF) (talk) 18:34, 28 February 2019 (UTC)
- @Jheald, RIsler (WMF), and Syced: Sandra pointed out this question to me. We want to model what is in an image for searching, but also for legal status. I think we'll have three relevant properties here:
- depicts (P180) - Everything that is visible in the image. We're using categories for this now.
- digital representation of (P6243) - For a digital representation of a 2D work. This is more a legal focused property. We're using {{PD-art}} for that now. When the original work is in the public domain, the digital representation of that work is also in the public domain. With this property we have that as structured data.
- New property "includes work" - To cover cases where images include other works. These works can be in the public domain (photo of an old statue) or still in copyright. In that case it should be qualified why the copyrighted work can be included. This would cover Freedom of panorama cases for which we now use {{FOP}} . Cases for which we now use {{De minimis}} would be covered too.
- This way we should be able to cover a lot of cases with multiple works involved. Do you agree? I still have to propose the missing property. Probably would also need to create a bit of documentation when to use what property. Multichill (talk) 14:02, 15 March 2019 (UTC)
- @Multichill: I think the specific question that was bothering me was this: if it is true that an image is a digital representation of (P6243) a particular work, what (if any) depicts (P180) statements should be added on CommonsData?
- My understanding was that in such a case no depicts (P180) statements should be added on Commons -- all such statements should be added on the relevant item on Wikidata.
- This is of considerable relevance for phab:T199241 ("If a MediaInfo items depicts something that has its own 'depicts' statements, add those to the search index too") -- the ticket should include the case that a MediaInfo item is a digital representation of (P6243) something with a depicts statement.
- We should also be considering the question of how early digital representation of (P6243) needs to be being made available as an option alongside depicts (P180) in user interfaces. Jheald (talk) 15:12, 15 March 2019 (UTC)
- @Multichill: Sorry I'm late to this party. Busy days :-). These are all good questions and I wish we had solid answers to them. We've attempted to have some general community discussions on this topic in the past, but it ultimately seemed too abstract for people to grasp without concrete tools to play with. Much may come down to just doing incremental work and seeing how people actually use things so we can model accordingly. Some people think that depicts (P180) should always be used, sometimes in addition to digital representation of (P6243) if necessary. Others like JHeald feel like P180 shouldn't be used at all in the case of a 2D faithful reproduction, and only P6243 should be used along with a 'import depicts statements from the Q item' system like the one in the ticket he mentioned (which we will be revisiting soon). Others view P6243 as not necessarily a "legal focused property", but simply a more accurate one (which is viewed as important among the "data purity" crowd). Which direction is 'right'? I'm not sure yet. As for "includes work", that may be a useful solution, but I wonder how it works with the proposals on [the Wikidata Copyrights modeling https://www.wikidata.org/wiki/Help:Copyrights], and whether we'd be better off simply using that as a guideline for licensing qualifiers on a depicts(P180) statement. I suspect some people may even use this as a counterargument in a property proposal discussion. The dev team is open to building in features that help simplify the complexities, but we also don't want to build stuff that boxes people in, or UX that doesn't reflect real-world workflows (many of which have yet to form). My personal preference is to rely on 'depicts' as much as possible for simplicity's sake, but I feel I may be in the minority there :-) RIsler (WMF) (talk) 02:23, 22 March 2019 (UTC)
- From what I can see, this can all be done with depicts (P180), it doesn't need a new property. That matches what we do here with categories - you'd only include an image showing an artwork in the category for that artwork (if it exists), not a whole set of categories saying whether the image shows a dog, cat, person, etc. You can then derive that information from Wikidata if needed, in the same way that the information would be stored in the categories that the category for the artwork is in. Thanks. Mike Peel (talk) 21:11, 27 March 2019 (UTC)
- Yes, categories are for what we see and these are replaced with depicts. This is for the template {{PD-Art}}.
- For other readers, Mike nominated this property for deletion at d:Wikidata:Properties_for_deletion#digital_representation_of_(P6243). Multichill (talk) 21:24, 27 March 2019 (UTC)
- @Multichill: and all: So for File:Mona Lisa, by Leonardo da Vinci, from C2RMF retouched.jpg as an example, rather than simply saying depicts (P180)=Mona Lisa (Q12418) and pulling the rest of the info from the Wikidata item, you want to say digital representation of (P6243)=Mona Lisa (Q12418) and depicts (P180)=Lisa del Giocondo, sky, body of water, bridge, armrest, landscape, mountain
 , Lisa del Giocondo, sky, body of water, bridge, armrest, landscape, mountain - and then repeat that information for all images depicting the Mona Lisa? If yes, why? Thanks. Mike Peel (talk) 20:21, 29 March 2019 (UTC)
, Lisa del Giocondo, sky, body of water, bridge, armrest, landscape, mountain - and then repeat that information for all images depicting the Mona Lisa? If yes, why? Thanks. Mike Peel (talk) 20:21, 29 March 2019 (UTC) - Ah, I just realised that we're talking about {{PD-art}}, not {{Artwork}}. That explains some of my confusion, but now I'm not sure why we can't just do depicts (P180)=Mona Lisa (Q12418) and get copyright status (P6216) from there? Thanks. Mike Peel (talk) 20:26, 29 March 2019 (UTC)
- Depicts doesn't distinguish between an exact reproduction and the painting is in the file.
- @Multichill: and all: So for File:Mona Lisa, by Leonardo da Vinci, from C2RMF retouched.jpg as an example, rather than simply saying depicts (P180)=Mona Lisa (Q12418) and pulling the rest of the info from the Wikidata item, you want to say digital representation of (P6243)=Mona Lisa (Q12418) and depicts (P180)=Lisa del Giocondo, sky, body of water, bridge, armrest, landscape, mountain
- From what I can see, this can all be done with depicts (P180), it doesn't need a new property. That matches what we do here with categories - you'd only include an image showing an artwork in the category for that artwork (if it exists), not a whole set of categories saying whether the image shows a dog, cat, person, etc. You can then derive that information from Wikidata if needed, in the same way that the information would be stored in the categories that the category for the artwork is in. Thanks. Mike Peel (talk) 21:11, 27 March 2019 (UTC)
- @Multichill: Sorry I'm late to this party. Busy days :-). These are all good questions and I wish we had solid answers to them. We've attempted to have some general community discussions on this topic in the past, but it ultimately seemed too abstract for people to grasp without concrete tools to play with. Much may come down to just doing incremental work and seeing how people actually use things so we can model accordingly. Some people think that depicts (P180) should always be used, sometimes in addition to digital representation of (P6243) if necessary. Others like JHeald feel like P180 shouldn't be used at all in the case of a 2D faithful reproduction, and only P6243 should be used along with a 'import depicts statements from the Q item' system like the one in the ticket he mentioned (which we will be revisiting soon). Others view P6243 as not necessarily a "legal focused property", but simply a more accurate one (which is viewed as important among the "data purity" crowd). Which direction is 'right'? I'm not sure yet. As for "includes work", that may be a useful solution, but I wonder how it works with the proposals on [the Wikidata Copyrights modeling https://www.wikidata.org/wiki/Help:Copyrights], and whether we'd be better off simply using that as a guideline for licensing qualifiers on a depicts(P180) statement. I suspect some people may even use this as a counterargument in a property proposal discussion. The dev team is open to building in features that help simplify the complexities, but we also don't want to build stuff that boxes people in, or UX that doesn't reflect real-world workflows (many of which have yet to form). My personal preference is to rely on 'depicts' as much as possible for simplicity's sake, but I feel I may be in the minority there :-) RIsler (WMF) (talk) 02:23, 22 March 2019 (UTC)
- @Jheald, RIsler (WMF), and Syced: Sandra pointed out this question to me. We want to model what is in an image for searching, but also for legal status. I think we'll have three relevant properties here:

.jpg)


- This is not going to work with only depicts. Of course we're not going to copy all the depicts from Wikidata, those are on the Wikidata item which is connected through digital representation of (P6243). What makes you think I would even consider doing that? Multichill (talk) 20:49, 29 March 2019 (UTC)
- After an off-wiki chat with Multichill, I've withdrawn the deletion request. This seems to be about copyright, not about how to describe what the image depicts. I've made some tweaks to the property description to try to make that clearer, but it still needs more work to clearly explain what this property is for, otherwise it will probably be misused in the future. Thanks. Mike Peel (talk) 21:09, 29 March 2019 (UTC)
- This is not going to work with only depicts. Of course we're not going to copy all the depicts from Wikidata, those are on the Wikidata item which is connected through digital representation of (P6243). What makes you think I would even consider doing that? Multichill (talk) 20:49, 29 March 2019 (UTC)
Faceted search?
I was wondering if faceted search is on the roadmap somewhere? Couldn't find an obvious task in Phabricator. As a user I would expect to be able to search for Rembrandt and get Rembrandt (Q5598). Based on that I would expect suggestions like: Paintings/drawings/prints by Rembrandt or streets named after Rembrand. See this query. You can change the "Q5598" in the query with something else to get similar suggestions sometimes with quite unexpected results. Heavy usage items like Berlin might take some time to complete. Multichill (talk) 20:56, 27 March 2019 (UTC)
- Looks like phab:T213360 ("filtered search") is furthest ticket blocked out so far for search refinement, and even then only focussed on what could be a very first step, with deliberately restrained objectives. Jheald (talk) 01:23, 29 March 2019 (UTC)
- @Multichill: I know the development team talked about perhaps getting search to that point. I'm not sure what the technical and content blockers might have been or are. I'll see what I can find out. Keegan (WMF) (talk) 19:30, 29 March 2019 (UTC)
- Thanks Keegan. Right now we're basically only doing full text search with some tweaks. With just depicts enabled faceted search isn't very interesting yet, but once we start adding more metadata like when and where it was taken, it suddenly becomes very interesting. Multichill (talk) 19:39, 29 March 2019 (UTC)
Searching structured data is available
Searching structured data is possible using the standard Commons search bar. I've added search instructions for captions to Commons:File captions; depicts and other statements will be searchable right out of the box when they are released. Keegan (WMF) (talk) 17:46, 29 March 2019 (UTC)
Switching off watchlist changes
Hi, when a caption is added it causes an entry in the watchlist so is there some flag that needs to be toggled to ignore these changes? Keith D (talk) 23:14, 31 March 2019 (UTC)
- Support. — Jeff G. ツ please ping or talk to me 00:20, 1 April 2019 (UTC)
- I do not see a need. Changing the caption is nearly the same like changing the description and there is also no way to not show changes of the description. --GPSLeo (talk) 08:39, 1 April 2019 (UTC)
- It is not like changing the description as it cannot be seen in the wikitext of the page so should be separate and have some way of seeing/hiding such changes similar to wikidata changes. Keith D (talk) 11:20, 1 April 2019 (UTC)
- Support Yes, an option for hidding captions editing would be useful. --Yann (talk) 11:51, 1 April 2019 (UTC)
- An option for only displaying captions editing would also be helpful to counter vandalism. — Jeff G. ツ please ping or talk to me 14:08, 1 April 2019 (UTC)
- The artificial limit of 1,000 changes is also a driver for this. Keith D (talk) 16:10, 1 April 2019 (UTC)
- @Keith D: I agree, but where is "The artificial limit of 1,000 changes" documented? — Jeff G. ツ please ping or talk to me 03:20, 3 April 2019 (UTC)
- @Jeff G.: It was a change introduced, I think last year, because of performance issues. If you look in preferences under both Recent changes tab the "Number of edits to show in recent changes, page histories, and in logs, by default:" & Watchlist tab the "Maximum number of changes to show in watchlist:" indicate that the Maximum allowed is 1000. Keith D (talk) 16:18, 3 April 2019 (UTC)
- @Keith D: I agree, but where is "The artificial limit of 1,000 changes" documented? — Jeff G. ツ please ping or talk to me 03:20, 3 April 2019 (UTC)
- The artificial limit of 1,000 changes is also a driver for this. Keith D (talk) 16:10, 1 April 2019 (UTC)
- An option for only displaying captions editing would also be helpful to counter vandalism. — Jeff G. ツ please ping or talk to me 14:08, 1 April 2019 (UTC)
- Thanks for the request, it's a good idea. The team will make a Phabricator ticket and work out the details. I'll post the link when it's made. Keegan (WMF) (talk) 19:18, 2 April 2019 (UTC)
The addition of captions however is tricky... I saw someone (mass?) adding the category name as caption, resulting into abominations. Is anyone monitoring such activities? Nemo 16:31, 5 April 2019 (UTC)
File names versus descriptions
Wiki has long insisted that filenames be descriptive, mostly for the convenience of wiki editors but against military and private sector guidelines regarding filenames for images. Also against file-naming for the purpose of traceability of originator, licensing and attribution.
An image filename usually starts with the filename assigned by the camera, sometimes augmented or changed by the originator, then augmented again, like when uploaded from flickr to Commons. The final and uniquely identifying filename as uploaded to wiki should NOT be altered by wiki or anybody else.
An image file should also show a separate and additional line for a description, preferably provided by the originator but alterable if required. This feature is already sorely missed and will become of even greater importance, together with a reliable filename, for Structured Data
The image pixel size presently displayed under the image need not be in such a prominent position, if displayed at all. Image pixel size is of less informative value since it does not disclose the degree of jpg compression also influential in regards to image file size and image quality.
As a side note: Wiki's syntax for a Slideshow, a child of Gallery, produces an image of less quality than when displayed in a gallery. This needs to be corrected, or selectable, even if it slows down the loading of images when displayed in a full quality slideshow.
Respectfully, Bengt Nyman (talk) 13:43, 5 April 2019 (UTC)
- Hi, I disagree about everything of what you said... Regards, Yann (talk) 15:30, 5 April 2019 (UTC)
- I dot understand what you want to say. The captions we have now are captions, in many cases they will be the same like the filename except of some numeration or IDs in other cases the Caption will be the same like the description, because the filename is very short. In the future the filenames could maybe get replaced by never changing IDs, but I think all filenames will be stored anyway an there should be redirects too. --GPSLeo (talk) 16:18, 5 April 2019 (UTC)
- Image filenames should not be used as captions. Images should have a filename and a caption. Two separate lines of information. Bengt Nyman (talk) 19:35, 5 April 2019 (UTC)
- One example File:Close up of Utricularia vulgaris flowers in the Teufelsbruch swamp 04.jpg what would you put in the caption that is not in the file name? --GPSLeo (talk) 20:16, 5 April 2019 (UTC)
- Image filenames should not be used as captions. Images should have a filename and a caption. Two separate lines of information. Bengt Nyman (talk) 19:35, 5 April 2019 (UTC)
Can't edit file captions while a file is being requested to be renamed
-
 I can't do it on the Desktop mode.
I can't do it on the Desktop mode.
(wait, this "Mobile 📱 view".) -
 And I can't do it using the Mobile 📱 mode.
And I can't do it using the Mobile 📱 mode.
(And this is the "Desktop view".)
_01.png)
_02.png)
For whatever reason when I requested a file to be renamed (please see File:10 Rupees - Bank of Madras (1930's).jpg) I stopped being able to edit the file captions which still display the wrong date (a century apart from when the banknote was actually made) . Is anyone else also experiencing this bug? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:27, 6 April 2019 (UTC)
- Yes, I am also not able to edit the caption. --GPSLeo (talk) 19:49, 6 April 2019 (UTC)
- @Donald Trung: Same for me, both mobile and desktop. However, upon inspection, the top image is from (probably early) 1840s, but the bottom is dated 1860 (60 in what appears to be pencil). — Jeff G. ツ please ping or talk to me 20:29, 6 April 2019 (UTC)
- @Jeff G.: Thanks for the corrections, I will implement them momentarily. @Jeff G. & @GPSLeo thanks for the feedback, I'll report it to the Phabricator later. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:53, 6 April 2019 (UTC)
- @Donald Trung: You're welcome. — Jeff G. ツ please ping or talk to me 01:41, 7 April 2019 (UTC)
- @Jeff G.: Thanks for the corrections, I will implement them momentarily. @Jeff G. & @GPSLeo thanks for the feedback, I'll report it to the Phabricator later. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:53, 6 April 2019 (UTC)
And... A patch is already for review. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 03:47, 7 April 2019 (UTC)
- This section was archived on a request by: Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 03:47, 7 April 2019 (UTC)
Why?
This Structured Data "feature" is a failure on the order of Flow. Why is this the case? Let us count the ways:
- Wikimedia did not hold a large-scale consultation like w:en:WP:TPC19, which would have enabled them to get the community's view on it as well as make it less redundant. Which brings us to...
- It adds needless complication to Commons. All it does is duplicate the file description box, with the main difference being that people actually use the wikitext description template.
- Making data machine readable would be nice, but is not a priority for readers or even experienced editors like me.
- Wikitext support is even worse than in Flow; that is to say, there is none.
- Very poor handling of page protection, one of MediaWiki's most important features.
- Has an "I accept the terms and conditions" dialog box. Really, there was no way to display that message in a less intrusive and more Wikipedia-like way?
- IT REQUIRES JAVASCRIPT.
For these reasons, I have set my adblock to block this disaster from Commons file pages, so I never have to see this abomination ever again. I urge Wikimedia to reconsider the vast amounts of donation money they are putting into a feature that not many people actually like. — pythoncoder (talk | contribs) 16:37, 17 April 2019 (UTC)
- User:pythoncoder, Structured data is a work in progress which came after long period of discussions. I am not sure if you are familiar with Wikidata, but we hope to be able to to store metadata related to all images in similar format, in addition and possibly instead of current wikitext based metadata storage. Being able to query the data, the way we can query Wikidata is very important for maintenance and re-usability of Commons content. I agree that we will have some duplication of metadata since it is being stored in 2 parallel formats, but it is a necessary side-effect. --Jarekt (talk) 18:17, 17 April 2019 (UTC)
- I’m just thinking that 1) you should be able to contribute even if JavaScript is disabled, to provide maximum accessibility, and 2) there should be more work done to reduce duplication (e.g. auto-import description fields to the new system). — pythoncoder (talk | contribs) 19:18, 17 April 2019 (UTC)
- You can contribute to Wikidata with a command line tool, this could be adapted for Commons. --GPSLeo (talk) 20:26, 17 April 2019 (UTC)
- I’m just thinking that 1) you should be able to contribute even if JavaScript is disabled, to provide maximum accessibility, and 2) there should be more work done to reduce duplication (e.g. auto-import description fields to the new system). — pythoncoder (talk | contribs) 19:18, 17 April 2019 (UTC)
"Requested depicts" (or "Most requested Wikidata items")
Maybe there should be a feature where Wikimedia Commons users could add depicts which do not link to currently existing Wikidata items, this is a similar to how for example on the Dutch-language Wikipedia there is a list of how often the same red link is used and these non-existing pages are then categorised as "requested Wikipedia articles" and the more often a red link is used the higher it goes on the list. I suggest that we should do the same for depicts where Wikimedia Commons users could add depicts for non-existing Wikidata pages which are then listed (either here or on Wikidata) and could then be created. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:04, 5 April 2019 (UTC)
- @Donald Trung: If you want to add a “depicts” statement and the item doesn’t exist yet, just create the item. Wikidata items aren’t like Wikipedia articles that have to meet a certain encyclopedic standard to not be deleted – if all you have is a name and a rough date when the person lived (i. e. floruit (P1317)), that’s fine for a start. (Later, you can still query for frequently depicted items that are missing certain statements, or have the lowest statement count, or other criteria.) —Galaktos (talk) 21:22, 17 April 2019 (UTC)
- Raises an important issue, though. At the moment there are bots that check, when items are nominated to Wikidata's "items for deletion" page, to see whether they are referred to from statements on any other Wikidata item. Similar functionality will be needed, to check and advise whether the items are the object of any depicts statements on Commons, once an API is in place to be able to check this. Jheald (talk) 22:46, 17 April 2019 (UTC)
- "Wikidata items aren’t like Wikipedia articles that have to meet a certain encyclopedic standard to not be deleted" Er, yes they are, but the barrier for entry is set much lower. See d:Wikidata:Notability. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 13:50, 18 April 2019 (UTC)
- @Pigsonthewing: I didn’t say that Wikidata has no notability criteria. But on Wikipedia even articles for notable subjects may be deleted (or incubated) if the articles themselves lack quality. On Wikidata, in my experience this generally doesn’t happen: even rudimentary stub items are better than nothing. --Galaktos (talk) 17:37, 18 April 2019 (UTC)
- d:Wikidata:Requests for deletions. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 20:44, 18 April 2019 (UTC)
- @Pigsonthewing: If you’re trying to tell me anything with that link, I’m afraid you’ll have to use a few more words than that – I’m no idea what that reply is supposed to mean. (Also, kindly ping me if it’s not too much trouble.) —Galaktos (talk) 11:00, 19 April 2019 (UTC)
- I thing we do not have things as the depict of an image, that is in scope on Commons, but not notable for a Wikidata item. --GPSLeo (talk) 13:14, 19 April 2019 (UTC)
- Regarding SDC there is concern about two things in Wikidata:
- Some Wikidata editors have the impression that there is a problem with way too much (self-)promotional content at Commons. I do not know about Commons project details and processes, but reasons may be a deliberately low notability threshold, or Commons' inability to timely remove such content. (There is a similar problem at Wikidata, but due to the fact that the project is already Structured Data only, it is somewhat easier to dealt with it.)
The concern now is that someone uploads an image to Commons, for example by themselves, and that automatically warrants a Wikidata item as well. There is quite some pressure from communities such as Search Engine Optimizers who deliberately want an item about themselves or their businesses, purely based on self-provided information. This way, Wikidata would quickly be in a position that "everything is considered notable" via the backdoor called Wikimedia Commons, which neither the technical infrastructure nor the community could handle properly. - Commons core content are media files, many of them are user generated content. That is fine, but it sets Commons conceptually somewhat apart from most of the other Wikimedia projects. The problem now is that much of the information which should in future go to the structure data (and in particular to Wikidata itself) is kind of auxiliary content—such as file categorization—and as such usually completely unsourced.
Wikidata's notability criteria are designed in a way that for each item it should be relatively easy to find external sources that describe reasonable parts of the content within an item. Wikidata is far away from having individual references on each and every statement, but in fact for the vast majority of items there are either sitelinks with proper sources connected, or external identifiers/references in the item in place which point to external sources. However, the key aspect about Wikidata's notability criteria is that entity notability is generated outside of the Wikimedia universe, by a description of the entity in a "serious source" (i.e. not under control of the entity, and typically also not user generated content websites).
- Some Wikidata editors have the impression that there is a problem with way too much (self-)promotional content at Commons. I do not know about Commons project details and processes, but reasons may be a deliberately low notability threshold, or Commons' inability to timely remove such content. (There is a similar problem at Wikidata, but due to the fact that the project is already Structured Data only, it is somewhat easier to dealt with it.)
- I think in general there is a lot of support for SDC within the Wikidata community, but I would be surprised if there won't be some disputes regarding the mentioned issues in the future. (Disclaimer: I am Wikidata admin) —MisterSynergy (talk) 18:12, 19 April 2019 (UTC)
- Hi, I have mentioned several times at the very beginning of SDC that the notability within Wikidata will be a major issue. Nobody seemed to care until now. But here we are... I think it should be possible to define with objective criteria what subjects are in scope, and therefore warrant a Wikidata for SDC, and what are not, and this only based on current Commons policies. Commons:Notability already exists, and is a redirect to COM:SCOPE. It should probably be deleveloped with more detailed examples. Or may be we can do that on Commons:Depicts? Regards, Yann (talk) 18:33, 19 April 2019 (UTC)
- Well, I am sure that things will settle in a way both projects can live with; as usual, there may be some friction we experience on the way :-) It would be great, however, if existing Commons content such as person data from categories would not simply be (automatically) dumped in Wikidata, particularly in cases where no items exist yet.
Commons:Depicts is specifically for the depicts statements, but that is only a part of SDC. Although the notability question is related to it (how to use "depicts" if there is no Wikidata item for what is depicted), I think this talk page is probably the best place to discuss the problem. —MisterSynergy (talk) 19:19, 19 April 2019 (UTC)- With the first version of a "guideline" I started a topic about this here: Commons talk:Depicts#Missing Wikidata items --GPSLeo (talk) 23:12, 19 April 2019 (UTC)
- Well, I am sure that things will settle in a way both projects can live with; as usual, there may be some friction we experience on the way :-) It would be great, however, if existing Commons content such as person data from categories would not simply be (automatically) dumped in Wikidata, particularly in cases where no items exist yet.
- Hi, I have mentioned several times at the very beginning of SDC that the notability within Wikidata will be a major issue. Nobody seemed to care until now. But here we are... I think it should be possible to define with objective criteria what subjects are in scope, and therefore warrant a Wikidata for SDC, and what are not, and this only based on current Commons policies. Commons:Notability already exists, and is a redirect to COM:SCOPE. It should probably be deleveloped with more detailed examples. Or may be we can do that on Commons:Depicts? Regards, Yann (talk) 18:33, 19 April 2019 (UTC)
- Regarding SDC there is concern about two things in Wikidata:
- I thing we do not have things as the depict of an image, that is in scope on Commons, but not notable for a Wikidata item. --GPSLeo (talk) 13:14, 19 April 2019 (UTC)
- @Pigsonthewing: If you’re trying to tell me anything with that link, I’m afraid you’ll have to use a few more words than that – I’m no idea what that reply is supposed to mean. (Also, kindly ping me if it’s not too much trouble.) —Galaktos (talk) 11:00, 19 April 2019 (UTC)
- d:Wikidata:Requests for deletions. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 20:44, 18 April 2019 (UTC)
- @Pigsonthewing: I didn’t say that Wikidata has no notability criteria. But on Wikipedia even articles for notable subjects may be deleted (or incubated) if the articles themselves lack quality. On Wikidata, in my experience this generally doesn’t happen: even rudimentary stub items are better than nothing. --Galaktos (talk) 17:37, 18 April 2019 (UTC)
Depicts statements coming this week
The Structured Data on Commons team plans to release support for depicts statements this week, on Thursday, 18 April. The community's testing over the past several weeks helped identify and fix issues before launch, and the development team spent time setting up extensive internal testing to make sure the release goes as well as possible.
This release is very simple, with only the most basic depicts statements available. There is a significant amount of technological change happening with this project, and this release contains a lot of background change that the team needs to make sure works fine live on Commons before adding further support. More parts to depicts statements, and other statements, will be released within the next few weeks.
A page for depicts has been set up at Commons:Depicts. As I can't actually write instructive Commons policy or guidelines, I encourage those who have tried out simple depicts tagging add a few lines to the page suggesting proper use of the tool. I also encourage the use to be conservative at first, as we wait for more advanced features within the coming month or two as additional statement support goes live.
I'll keep the community updated as the plans progress throughout the week, the team will know better within the next day or two if things are definitely okay to proceed with release. Keegan (WMF) (talk) 21:34, 15 April 2019 (UTC)
- Thanks Keegan (WMF). I've had a go at getting the ball rolling on a guide. But I'm afraid I've already hit a contradiction between your encouragement to "be conservative at first", and the discussion at Commons_talk:Structured_data/Get_involved/Feedback_requests/Good_coverage where the proposal suggests very liberal use of generic tags, but the commenters (and I) prefer a more conservative approach similar to steering clear of overcategorization. Should we just stick to the most specific tags for now? --99of9 (talk) 06:40, 16 April 2019 (UTC)
- At this point I would definitely advise people to be specific when using basic depicts. What neither the development team nor community want to happen in the first few weeks is have people populating depicts with statements that can easily wait and go into depicts qualifiers, depicts of depicts, or other statement structures that would make more sense. It's increased workload for sure to go back and restructure things if people have been overly liberal at first, when patience for deeper statement support will be worth it. Keegan (WMF) (talk) 15:31, 16 April 2019 (UTC)
- Ok good, I've clarified the guideline. I'm less optimistic that other statement structures will solve the basic issue of people or bots wanting to tag an image with every single item it depicts a subclass*/instance of. It seems to me that the search should do the drilling down like that. --99of9 (talk) 00:53, 17 April 2019 (UTC)
- @99of9: Ultimately, I think the way round this (as discussed a bit in the 'Good coverage' chat) could be to show inferred search targets as "shadow tags", so that (i) people will be able to see more clearly why a search may or may not have returned a particular page; and (ii) people will be less encouraged to add such redundant tags manually, if they are already visible (albeit greyed-out, or presented differently, or behind a (+) expand button). But this will take additional work, and I think the dev team's priority is quite correct if it is trying just to get something up on the wall as soon as possible, that we can look at and think about. Jheald (talk) 09:15, 17 April 2019 (UTC)
- Ok good, I've clarified the guideline. I'm less optimistic that other statement structures will solve the basic issue of people or bots wanting to tag an image with every single item it depicts a subclass*/instance of. It seems to me that the search should do the drilling down like that. --99of9 (talk) 00:53, 17 April 2019 (UTC)
- At this point I would definitely advise people to be specific when using basic depicts. What neither the development team nor community want to happen in the first few weeks is have people populating depicts with statements that can easily wait and go into depicts qualifiers, depicts of depicts, or other statement structures that would make more sense. It's increased workload for sure to go back and restructure things if people have been overly liberal at first, when patience for deeper statement support will be worth it. Keegan (WMF) (talk) 15:31, 16 April 2019 (UTC)
- One question: Will the possibility to add depicts in the upload wizard also get released this week or later? --GPSLeo (talk) 10:12, 17 April 2019 (UTC)
- @GPSLeo: Depicts in UploadWizard will not be released this week, but will be next. Keegan (WMF) (talk) 16:06, 17 April 2019 (UTC)
Depicts coming tomorrow, 18 April
The development team is going ahead with deployment tomorrow, 18 April, between 15:00 and 16:00 UTC. Some community members are working on developing early guidance on using the feature at Commons:Depicts, and I've added some initial information about searching depicts items when they're live. Keegan (WMF) (talk) 19:29, 17 April 2019 (UTC)
- @Keegan (WMF): In case of any deployment issues, is the WMF working on Friday 19 April? I ask as it's a vacation day in many countries. Thanks. Mike Peel (talk) 19:57, 17 April 2019 (UTC)
- @Mike Peel: that's a great question. Yes, the team is working on Friday, 19 April and will be able to respond to any immediate post-deployment issues, should something happen. Keegan (WMF) (talk) 20:18, 17 April 2019 (UTC)
The deployment is delayed for a few hours, due to a bug completely unrelated to SDC (T221368, in case you're curious). We'll resume the release when the bug gets resolved. Keegan (WMF) (talk) 15:19, 18 April 2019 (UTC)
Depicts rescheduled for Tuesday, 23 April
Unfortunately the bug blocking the release was not resolved in time to release depicts today. Releases are not done on Fridays, so the team has rescheduled for Tuesday, 23 April from 15:00-16:00 UTC. I'll continue to keep the community posted as release approaches. Keegan (WMF) (talk) 20:44, 18 April 2019 (UTC)
- The process of releasing depicts will begin within an hour or so. I have a separate post to make here when it's been live for a few minutes and we're sure everything is working properly. Keegan (WMF) (talk) 14:29, 23 April 2019 (UTC)
Depicts statements are live on file pages
The ability to add structured "depicts" statements to file pages is live on Commons. When viewing a file page, the first major change you'll see is the introduction of a tab for accessing structured data for a file.

Once you've accessed the structured data tab, you'll see the ability to edit depicts statements and the ability to mark a statement as prominent.

More information about depicts is being developed at Commons:Depicts, including advice for how to use depicts as well as searching for statements. Feedback about the release - questions, comments, bugs found, design concerns, etc. - can be posted at the Structured Data on Commons talk page. The team will do a review of initial feedback and findings after depicts is launched on Commons to triage, develop, and deploy fixes.
A few things to note:
- It may take awhile for structured data and depicts statements to show up on every file, particularly if it's a file you've loaded recently, as Commons has a very large cache and it takes time to refresh.
- The same goes for search, it'll take some time to populate the search index.
- Adding/editing statements is not currently available through the mobile skin.
- Adding/editing statements may be slow on some files at first.
- UploadWizard functionality is not enabled yet.
To repeat something I wrote in the pre-release announcement, for emphasis:
This release is very simple, with only the most basic depicts statements available. There is a significant amount of technological change happening with this project, and this release contains a lot of background change that the team needs to make sure works fine live on Commons before adding further support. More parts to depicts statements, and other statements, will be released within the next few weeks.
Thanks to all the community for the help in planning, designing, and testing these new features over the past couple of years. I look forward to reading what everyone has to say. Keegan (WMF) (talk) 15:56, 23 April 2019 (UTC)
Mark as prominent?
What's the goal of this marking option? I found no explanation.
For example, think about a good cityscape-like image of a certain village including a random dog partly visible in the foreground.
- Is an object (e.g. the dog) "prominent" in regard to the file itself, because it takes a relevant part of space of an image?
- Or is an image "promiment" in regard an object (e.g. the village), because it's one of the "higher quality" images of that location? (and "dog" should not be marked as promiment, because many better images of dogs are available)
--Te750iv (talk) 17:27, 23 April 2019 (UTC)
- This is also discussed at Commons_talk:Depicts#Prominence, and some documentation was added to Commons:Depicts#Prominence. Jean-Fred (talk) 17:46, 23 April 2019 (UTC)
Comments
Hi. It's surprisingly fine. I have several questions/remarks:
- 1) a Cat-a-lot-alike tool is probably needed. Struc-a-lot?
- 2)
How can this be queried? I mean, in Wikidata there is this thing. OK Commons:Depicts#Searching depicts statements
OK Commons:Depicts#Searching depicts statements - 3)
Would there be additional fields aside "depicts"? I mean, something in the lines of "date" (P585), "place depicted"?,.... All of these can probably be lumped together in P180 (in Wikidata there are items for days of the month, for years and so on after all, but it may be healthier applying some compartimentation. OK Commons:Depicts#Items expected to be covered by other statements - 4) Displaying the associated Commons-category next to the item after saving changes would be interesting, because that would allow to use this "depicts-stuff"+wikidata_labels as a "quick dictionary" for non-English-speakers when it comes to adding categories (usually written in English).
Strakhov (talk) 18:08, 23 April 2019 (UTC)
- @Strakhov: regarding 2 – Wikidata also has Special:WhatLinksHere (limited, but still often useful), but that doesn’t work when the statement and value are on different wikis (Commons and Wikidata). --Lucas Werkmeister (talk) 20:04, 23 April 2019 (UTC)
Usability papercuts
- As a Wikidata editor, I expect that after adding a depicted value, I can press Enter on the empty input field to save my edits. Here, that’s not possible – I first have to move the focus to the “publish changes” button (Shift+Tab), or click it using my mouse.
- On Wikidata, when I search for an item and the results are ambiguous (e. g. similar works of art), I can middle-click on them to open the items and inspect them more closely, since the search results are links. Here, even though the individual search results have a “pointer” cursor, they’re not actually links and I can’t follow them. If I want to find out which item is the correct one, I have to figure that out on Wikidata and then copy the item ID and paste that here. (Compare T207363 for a similar oversight on our end.) --Lucas Werkmeister (talk) 20:12, 23 April 2019 (UTC)
- Indeed. I had already filed 1/ as phab:T221687.
- I also noticed 2/ but forgot about it − thanks for reporting it :) The workaround here is that 'choosing' a value does not save the claim, and gets you a hyperlink to the Q-item (with phab:T221676 as caveat), so you can investigate the value that way.
- Jean-Fred (talk) 21:46, 23 April 2019 (UTC)
- Thanks, that’s a good tip for 2/. Meanwhile I found another papercut (there’s a reason I didn’t put the count in the heading 😛) –
- Edit summaries are translated (“Created claim” (en) → „Aussage erstellt“ (de), yay), but instead of the labels of the entities involved, you just see their IDs:
Created claim: (d:P180): (d:Q60180918)
– not especially useful. --Lucas Werkmeister (talk) 22:58, 23 April 2019 (UTC)
Maybe the above could be made available as well. It was specifically created for Commons. Jura1 (talk) 21:14, 23 April 2019 (UTC)
- Could be added to Commons:Structured data/Properties table. Jean-Fred (talk) 21:47, 23 April 2019 (UTC)
Media entity id not visible
Looking at the source I found that File:Gibraltar_lighthouse.jpg has the id M1227756 ( Special:EntityPage/M1227756 or Special:EntityData/M1227756.json ). It would be good if that was visible on the page and possibly https://commons.wikimedia.org/w/index.php?title=File:Gibraltar_lighthouse.jpg&action=info Jura1 (talk) 02:26, 24 April 2019 (UTC)
Create item/property
If these wont be usable on Commons, they probably shouldn't be on Special:SpecialPages#Wikibase.
(Despite me listing features that may be in the pipeline/possible bugs, I think the "depicts"-part of the implementation works out nicely.) Jura1 (talk) 02:26, 24 April 2019 (UTC)
Points to live version
I have few more points when using live version:
- The design of structured data section is very good and functionality looks fine to, expects some of the following:
- I think for a person, who uses commons and have never worked with Wikidata it might not be clear to use singular (so house instead of houses), because in Commons categories its common to use plural and in some languages which are even very flexive as Czech you can have other forms of a word to describe depiction. So maybe lets point somewhere that words should be set in infinitive.
- Than the trouble is that we provide values in mother tangue, but description of values in various languages, so the language barrier is not so removed as expacted
- It might be interesting to have an option to go to the link, where the description could be translated.
- Could we removed Wikipedia disambiguation from the value search (e.g. Container (Q232627)). I cannot see the reason, why to have disambiguation values in depicts.
- I wonder weather we can create a tool which help to specify item. Lets say you have an image with geographical coordinates and you add value "church". Could something read geographic coordination and provide the value of a spacific church (e.g. when you start to type church, provide Church of Saint James)?
- so if we link now, to wikidata from commons values, will be there links from wikidata values to wmc images? Or how this connection is going to work?
- Could we provide a link for creation or tool to create new item if it does not exists? The example is File:Zlivice, Zlivický rybník.JPG which depicts Zlivický Pond, which does not exists on Wikidata. I would say we have much more "objects" on Wikimedia Commons, than on Wikidata.
Juandev (talk) 07:43, 24 April 2019 (UTC)
- 3.1 is tracked at phab:T221676. Jean-Fred (talk) 17:09, 24 April 2019 (UTC)
My two cents:
- It would be useful some kind of qualifier, when on picture are e.g. 3 frogs, I must type "frog" only, no possibility how to specify there are more frogs.
- I am missing description and file usage when editing "depicts" - sometimes it can help with searching correct Q. Maybe some gadget for people with wide display for displaying both?
- There will be need to create many new items on wikidata. It would be fine, If I can crerate it directly from commons.
Sikky (talk) 18:29, 24 April 2019 (UTC)
- I want to +1 the desire for a script or gadget that shoes the Structured data Tab within the normal information tab (maybe as a collapse box?) so that I can add statements in one screen -- I know that the value of this script will change as we get tools and more functions added ontop of the structured data -- but in he short term, I am feeling like this is the only way to intuitively do this. Sadads (talk) 18:50, 24 April 2019 (UTC)
- @Sikky: your first point comes in the future.Juandev (talk) 06:41, 25 April 2019 (UTC)
Why aren't file captions under the Structured Data tab?
-
 Example on desktop viewing made.
Example on desktop viewing made. -
 Example on mobile view mode.
Example on mobile view mode. -
 Example on mobile view mode.
Example on mobile view mode.
_01.png)
_02.png)
_03.png)
I can see that file captions are still listed under "File information", is this going to change anytime in the future or is the "Structured Data" tab reserved only for newer features? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 01:13, 24 April 2019 (UTC)
- Captions will remain on the main file page. The rest of structured data's features will be behind the tab. Keegan (WMF) (talk) 16:45, 24 April 2019 (UTC)
- @Keegan (WMF): , ahhh, oké, but why though? It kind of seems misleading to have a tab for "Structured data" but then exclude file captions, this might cause some people to think that file captions are not structured data but general file information. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:36, 25 April 2019 (UTC)
- I agree that captions should be hidden away in the structured data tab. — Jeff G. ツ please ping or talk to me 18:27, 25 April 2019 (UTC)
- @Keegan (WMF): , ahhh, oké, but why though? It kind of seems misleading to have a tab for "Structured data" but then exclude file captions, this might cause some people to think that file captions are not structured data but general file information. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 17:36, 25 April 2019 (UTC)
On an unrelated note I can't add file captions in mobile 📱 but that was to be expected as support for mobile has always been less than optimal. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 01:13, 24 April 2019 (UTC)
- Correct, support for the mobile skin is not available yet. I do not know the timeline at the moment. Keegan (WMF) (talk) 16:45, 24 April 2019 (UTC)
Item description
Why the search does not search in item descritpions also. E.g. I am looking for the therm "Malé náměstí". It provides me seven items, but none of them is the one I am looking for. But in Wikidata I may search "Malé náměstí Prachatice" and it will take me to the right one, which I am looking for.
The other problem I can see here is same names for the items, already set, but missing description disallow me to set the priority to one of them - without clicking and getting to Wikidata, I dont know, which one is which. Juandev (talk) 10:53, 26 April 2019 (UTC)
- Thank you for all the feedback you've been leaving, Juandev. The development team is in the process of collecting it all, I'll link to tasks if/when they get created. Keegan (WMF) (talk) 18:40, 26 April 2019 (UTC)
Thanks. The wierd think is that if I set one value e.g. San Francisco, and next I look for Church of Saint James, it provides me with other churches, but not the one in San Francisco and I should go to Wikidata and copypaste it from there. Juandev (talk) 07:51, 27 April 2019 (UTC)
Tools and Gadgets affected by structured data
Lets list here which tools and gadgets where afected by the introduction of structured data.
- Hot Cat - when adding values of depicts, the hot cant than announces you are editing and an old version, but it works properly. Juandev (talk) 07:57, 27 April 2019 (UTC)
Juandev (talk) 07:57, 27 April 2019 (UTC)
Repetition of Caption sections
Hi,
On attached:

I'm seeing two iterations of the caption section each containing two (empty) iterations of the "British English" section. The actual caption is under "English". How did this happen and how can I correct it?
Murgatroyd49 (talk) 09:32, 18 March 2019 (UTC)
- OK now I'm getting paranoid, it also happened at File:Sutherland Circle.jpg, just after I added that image to a Wikipedia page. Murgatroyd49 (talk) 12:20, 18 March 2019 (UTC)
- @Murgatroyd49: that sounds like a cache issue with MediaWiki that should clear up on hard page refresh. It happens from time to time in all kinds of interesting places. Let me know if it's a regular occurrence for you, or if it's only happening to files you've recently touched. Keegan (WMF) (talk) 17:19, 18 March 2019 (UTC)
- @Keegan (WMF): Thanks I'll keep an eye on it. Murgatroyd49 (talk) 17:32, 18 March 2019 (UTC)
- @Keegan (WMF): Quick update, it's not happened since, hopefully whatever it was has been resolved. Murgatroyd49 (talk) 15:46, 26 April 2019 (UTC)
- Great, thank you for the followup. Keegan (WMF) (talk) 18:41, 26 April 2019 (UTC)
- @Keegan (WMF): Quick update, it's not happened since, hopefully whatever it was has been resolved. Murgatroyd49 (talk) 15:46, 26 April 2019 (UTC)
- @Keegan (WMF): Thanks I'll keep an eye on it. Murgatroyd49 (talk) 17:32, 18 March 2019 (UTC)
- @Murgatroyd49: that sounds like a cache issue with MediaWiki that should clear up on hard page refresh. It happens from time to time in all kinds of interesting places. Let me know if it's a regular occurrence for you, or if it's only happening to files you've recently touched. Keegan (WMF) (talk) 17:19, 18 March 2019 (UTC)
New caption problem, when using the "use image on wikipedia" link button, it no longer gives the form [Image title.jpg|Some caption] but [Image title.jpg|Image title]. Murgatroyd49 (talk) 16:02, 28 April 2019 (UTC)
Adding a depicts statement adds the page to my watchlist
Whenever I add a depicts statement, the page gets added to my Watchlist, even though 'Add pages and files I edit to my watchlist' in my Preferences is disabled. Either this should not happen, or there should be a separate add-to-watchlist switch for files where I've edited the structured data. --Vesihiisi (talk) 17:00, 28 April 2019 (UTC)
- Already tracked. Raymond 17:12, 28 April 2019 (UTC)
Issues with gadgets after update
The 3 gagdets created when file captions went live do not work anymore after the update, or at least only partially. Should we discuss this here or in the technical Village Pump? I would not discuss this on the gadget pages in the moment. — Speravir – 02:05, 25 April 2019 (UTC)
- I would discuss it also here as SD team was interested in this issue also. The question is weather they will be fixed by their author or who will do it if not the author. Juandev (talk) 06:44, 25 April 2019 (UTC)
- (Ping @Keegan (WMF), Mmullie (WMF), and Jean-Frédéric-) OK. First: At least the description for them is so that officially only file captions are handled.
- MediaWiki:Gadget-Hide-Captions.css: (I do not use this.)
.mw-slot-headerapparently does not exist anymore; it seems the gadget should be changed to
- MediaWiki:Gadget-Hide-Captions.css: (I do not use this.)
.wbmi-tabs .oo-ui-menuLayout-menu, .wbmi-entityview-captionsPanel { display:none; }
- MediaWiki:Gadget-Compact-Captions.css: (I do not use this either.) Again,
.mw-slot-headercan be removed. Whether all other selectors still exist I don’t know. I suggest to add
- MediaWiki:Gadget-Compact-Captions.css: (I do not use this either.) Again,
.wbmi-tabs-container .wbmi-tab.oo-ui-panelLayout { margin-top: 0 !important; }
- Maybe the
!importantpart is not necessary in Mediawiki CSS. Quite probably also the new structured data tab could made more compact.- MediaWiki:Gadget-Collapse-Captions.js: In my starting question I did not notice that the structured data tab blends out all file information, also the conventional one, so we do not need a change there. But for the File captions since a change last week the toggle in uncollapsed state overlaps the Edit string, so it is unusable. These rules work for me to fix this:
.wbmi-entityview-captionsPanel .mw-collapsible-toggle { margin-top: -1rem; } .wbmi-entityview-captionsPanel .wbmi-entityview-captions-header .wbmi-entityview-editButton { right: 6.5rem !important; top: -0.25rem !important; }
- Again, whether the
!importantpart still is needed in Mediawiki CSS is beyond my knowledge. For the second rule the value6.5remunfortunately depends on a language dependant string (the word for “Collapse”) which has different lengths. I hope the German word “Einklappen” (used by me) is one of the longest variants. For RTL languages therightproperty seems not to be important, but they also need thetopshift. - Since this gadget is a script I guess the CSS code has to be added with the ResourceLoader module addCSS.
- — Speravir – 22:32, 27 April 2019 (UTC)
- Thanks Speravir for the research and the code.
- Collapse-Captions: The captions box is already correcrtly hidden.
- Compact-Captions: When this gadget was created, the captions box was humongous ; now it’s much more compact by default not sure how much needed it is now… Implemented some changes, started hunting unused elements, would need some more cleanup.
- Collapse-Captions: Done added the CSS classes to MediaWiki:Gadget-Collapse-Captions.css to move the Edit around (you can load both CSS and JS in Gadgets, see Special:Diff/347689135).
- Jean-Fred (talk) 10:13, 29 April 2019 (UTC)
- THX, Jean-Fred for the changes. Regarding the last one: I didn’t know, this is possible. And, of course, this is much better respective the only real solution then. — Speravir – 20:23, 29 April 2019 (UTC)
- Thanks Speravir for the research and the code.
Same value multiple times

I accidently add same value multiple times and it worked. Juandev (talk) 06:00, 26 April 2019 (UTC)
- @Juandev: This actually makes sense for once we have qualifiers in place where you might want to describe different individual items depicted within a file. Sadads (talk) 21:05, 28 April 2019 (UTC)
- I see. Juandev (talk) 08:38, 29 April 2019 (UTC)
Refresh page
Maybe it would be a good idea to refresh the page after inserting depicts (or caption). As I stated above, e.g. Hot Cat is confused and think that I am editing old version, and thus you need to refresh the page manually if you want to be sure, that Hot Cat will work properly. The similar situation happened recently in firefox when I opened recently closed page. I have seen there are no items for structured data. So I have inserted them again and then I realised, I have duplicated them. Juandev (talk) 07:41, 28 April 2019 (UTC)
- +1. I have already suggested that. Regards, Yann (talk) 08:27, 28 April 2019 (UTC)
- +1, it is highly recommended to get some attention to this. It is irritating to have HotCat to functioning in this way. One of the reasons why HotCat is there is to make the work of category additions/removals easy, without going into the "actual" edit mode. But this is spoiling that. Is there any phabricator ticket on this? KCVelaga (talk · mail) 11:34, 1 May 2019 (UTC)
Error in a caption → undo → no predefined edit summary
Hello,
When there is an error in a description and I click 'undo' in the page history, a predefined edit summary is provided for my edit: "Undo revision ___ by ___ (talk)". For instance: [16].
When there is an error in a caption and I click 'undo' in the page history, no predefined edit summary is provided for my edit. For instance: [17].
Is there a Phabricator task for this problem?
Regards --NicoScribe (talk) 16:23, 1 May 2019 (UTC)
- Well that's not right. Thanks for reporting, I'll provide an update after investigation. Keegan (WMF) (talk) 16:53, 1 May 2019 (UTC)
Error in a caption → undo → no addition to watchlist
Hello,
In my preferences, I have selected "Add pages and files I edit to my watchlist" and "Add pages where I have performed a rollback to my watchlist".
When there is an error in a caption and I click 'rollback' in the page history, the page is added to my watchlist. For instance: [18].
When there is an error in a caption and I click 'undo' in the page history, the page is not added to my watchlist. For instance: [19].
Is there a Phabricator task for this problem?
Regards --NicoScribe (talk) 16:45, 1 May 2019 (UTC)
- I can see why the rollback preference doesn't work for undo actions as well; they have different functionality and purpose though they perform a similar action. The preference for "Add pages and files I edit to my watchlist" is a different story. I've brought it up with the team, they'll discuss it and make a task as needed. Keegan (WMF) (talk) 18:18, 1 May 2019 (UTC)
Depicts support coming in UploadWizard next week
Support for depicts statements tagging will be enabled for the UploadWizard sometime next week. I'll let the community know when it's released, as well as provide some instruction on how to access it. If you'd like to try it out now yourself, you can visit Test-Commons for testing. If you have some feedback, you can leave it here. Keegan (WMF) (talk) 18:54, 2 May 2019 (UTC)
Depicts statement, no link if no description
Hi, If I enter a depict statement, there is no link to Wikidata if the item there doesn't have a description. Regards, Yann (talk) 04:34, 3 May 2019 (UTC)
- Tracked at phab:T221676. Jean-Fred (talk) 13:46, 3 May 2019 (UTC)
Tracking depicts work
The development team's been busy getting things cleaned up from the depicts release.
Fixed
- Structured Data (SD) panels no longer spread across the entire width of the window
- Improvements for adding a large number of captions at once
- MediaInfo content from Commons no longer appears on other wikis
- Conflict between FlickReviewr2 and caption submission in UploadWizard
Fixing
- Depicts label problems when Wikidata label for the item doesn’t exist in requested language
- Visual problems for depicts on mobile
- Auto-suggest search box for depicts not working on mobile
To be fixed
- Text overflow of Wikidata label on depicts
- No default edit summary text for SD undo
- Pages not added to watchlist on SD undo
- SD edits adding pages to watchlist when not appropriate
- Slight formatting bug on long captions
Can't fix
- Request for edit summary on statements to use Wikidata labels instead of Q and P numbers - those labels aren’t stored on Commons and would have to be fetched from Wikidata, which would be extremely challenging for now
I'll update this list if anything changes before launching depicts in the UploadWizard next week. Keegan (WMF) (talk) 16:27, 3 May 2019 (UTC)
Development of SPARQL query service for SDC
It looks like User:Smalyshev (WMF) has been going gangbusters towards getting a SPARQL query service similar to WDQS up and running for SDC.
There's now a "Wikidata & SDC" column on the Phabricator board for WDQS showing tickets relevant to the development. And in particular, it looks like there's now a clear way forward been agreed for the required supporting hardware installation. (phab:T221921).
Congratulations to all concerned, for decisively moving forward on this. Jheald (talk) 17:22, 3 May 2019 (UTC)
"Support community/volunteer tools around Structured Commons" --- Declined ????
Rather surprised to see Phabricator ticket phab:T180139 "Support community/volunteer tools around Structured Commons" closed as Declined, with explanation "Too broad in scope".
Similarly phab:T180197 "Support needed changes to volunteer tools for Wikimedia Commons and Wikidata that will benefit from operating with structured data on Commons" closed as Declined, with explanation "No real workflow to follow here".
Surely the whole point of tickets like these is to act as umbrella containers, to help people organise together further more Phabricator tickets for specific tasks where a small amount of central support could reap huge benefits -- or even just to note impacts, opportunities, or issues for key tools that SDC may present.
It seems very very odd to have simply written these tickets off wholesale. @Keegan (WMF): Care to explain? Jheald (talk) 23:02, 3 May 2019 (UTC)
- +1 - Jmabel ! talk 00:01, 4 May 2019 (UTC)
- @Jheald: thanks for your interest. Those tickets were created early on in the project before our team had clearly defined how we want to file tickets for our work. Those old tickets don't match what we do for process. The same work is being done, but in different tickets worded different ways. What you're seeing is housekeeping. Keegan (WMF) (talk) 02:18, 4 May 2019 (UTC)
Language code (sms: Skolt Saami) not recognized
Hello. I've uploaded some photos with descriptions that I've tried to use the sms language code with, but the uploader states "Unrecognized value for parameter language: sms." so there's clearly a problem with this language code. When I check out the file pages such as this one, the problem is real as the language doesn't show up in the caption box at all (caption in Skolt Saami: peeʹrvesǩ, sääʹmniõđid keäʹpper') and it only shows up as Sms in the summary. Furthermore, this most likely affects quite a few of the Saami languages, since Northern Saami is the only one that always works, so it'd be good to get this resolved asap. Thanks for the help. -Yupik (talk) 19:39, 1 May 2019 (UTC)
- I've filed a task to add
smsto the Universal language selector that file captions uses. Keegan (WMF) (talk) 20:41, 1 May 2019 (UTC)- Thank you. I haven't tried it out, but usually if
smsdoesn't work,smndoesn't work either. Could you add that as well? Thanks. -Yupik (talk) 21:57, 1 May 2019 (UTC)- I added the language code to the ticket. Keegan (WMF) (talk) 18:01, 2 May 2019 (UTC)
- Thanks! Let's hope I don't find another project where I can't use Skolt Saami :D At the beginning of April, a ticket was created so we could use it on Wikidata. -Yupik (talk) 08:30, 3 May 2019 (UTC)
- I added the language code to the ticket. Keegan (WMF) (talk) 18:01, 2 May 2019 (UTC)
- Thank you. I haven't tried it out, but usually if
- This is arguably not a bug. The language is not valid in Wikimedia Commons. Nemo 21:36, 2 May 2019 (UTC)
- What would you call it? -Yupik (talk) 08:29, 3 May 2019 (UTC)
- From a technical standpoint, it's a feature request - adding something new to the software. A bug is when something already in the software has a problem. Keegan (WMF) (talk) 16:13, 3 May 2019 (UTC)
- Ok, I'd call it a bug because it's something that should be in the software and isn't, but I see where you're coming from. -Yupik (talk) 17:49, 5 May 2019 (UTC)
- From a technical standpoint, it's a feature request - adding something new to the software. A bug is when something already in the software has a problem. Keegan (WMF) (talk) 16:13, 3 May 2019 (UTC)
- What would you call it? -Yupik (talk) 08:29, 3 May 2019 (UTC)
A distinctive appearance for the files that have depict statement(s) (or other structured datas...)
I just wondered if it could be usufull to have the possibility, when you come to a file page, to see at the first glance, and without to have to click on the structured data tab, if something have already been added in this tab. Example the tab "Structured data" could be in blue when something is stated, and black (as it is currently) when nothing is stated. Also valid for future developments, not only for the depict tags, I mean if there is a structured data (different than the caption) for the file, then the link become blue. Christian Ferrer (talk) 18:00, 5 May 2019 (UTC)
- This would be good, but the indication should comply with we accessibiity guiedlines - which using colour alone would not. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 19:13, 6 May 2019 (UTC)
- +1 I would love to have a status number following the structured data label (i.e. 5 statements), so that I know whether or not to dig into the tab and find ways to contribute. On Wikidata, I am frequently creating queries that prioritize items that have "few" statements -- and its a good indicator of depth, for folks who are looking for things to do. The other option could be something like recoin indicators -- but I don't think those kinds of completeness indicators will make much sense until we have critical mass. Sadads (talk) 10:41, 7 May 2019 (UTC)
- Yes, and for accessibility this should happen via CSS & classes, so it is possible to style it differently. - Jmabel ! talk 22:51, 7 May 2019 (UTC)
This new property could be used to identify valued/featured/quality images with statements (structured data). Jura1 (talk) 06:32, 8 May 2019 (UTC)
Notability
Hi, Now that the Depicts feature is live, can we talk about the notability criteria? I would suggest the following, for a start, but there are many questions coming. Regards, Yann (talk) 13:52, 4 May 2019 (UTC)
- Every named person depicted on Commons should have a Wikidata entry. If an image of a person is accepted as in scope on Commons, it means that the person should have en entry in Wikidata.
- Every work of art depicted on Commons should have a Wikidata entry.
- Every animal species depicted on Commons should have a Wikidata entry.
- Should we have entries for currency?
- File:Monnaie de Bactriane, Eucratide I, 2 faces.jpg: This is a unique object, so may be a special case.
- Some comments:
- 1. There are also photos with named persons they are not notable, like from Wikimedia events or for user pages.
- 2. I would agree, but what if an artwork is part on an other item like a statue on a bridge.
- 3. Are already notable. And I think we do not think that we have photos of (identified) species they do not have a Wikidata item. --GPSLeo (talk) 13:59, 4 May 2019 (UTC)
- There's an RfC still open in the Wikidata community about notability for Commons and the subjects of Commons categories. User:Yann, you should probably read the comments there, particularly in relation to named persons -- User:Mike Peel got temporarily blocked on Wikidata for trying to systematically create Wikidata items for named people with categories on Commons. There's quite a lot of sensitivity about this in the Wikidata community, particularly from some members that have made quite a mission out of trying to identify and delete items that people and companies have been contributing about themselves (for search-engine recognition?)
- Probably there's less objection to trying to make sure that eg every 18th-century cartographer with a Commons category should have a Wikidata item; but even that, perhaps, should not be taken to be entirely uncontroversial. Jheald (talk) 16:13, 4 May 2019 (UTC)
- As I have already said many times, we have an issue here (Why do I feel repeating myself?). I have an objection if people who never edit Commons get to block creation of entries needed for Structured Data to work properly.
- 1. At least, if the person warrants a category, it also needs a Wikidata entry.
- 2. If we have separate pictures for the sculptures, we need Wikidata entries for them.
- 3. I am only talking about identifed species of course. Regards, Yann (talk) 16:25, 4 May 2019 (UTC)
- @Yann: That's all well and good; but, however much I might agree with you, unless you can convince Wikidata admins of that position, or the general Wikidata community, we are no further forward. Jheald (talk) 19:08, 4 May 2019 (UTC)
- There are also real-world objects like Category:Wind turbine parts. There's no Wikidata item for such things, and I'm not sure if it should be created. Do you just have Depicts:Component? --ghouston (talk) 02:06, 5 May 2019 (UTC)
- The parts of a wind turbine definitely fit the Wikidata notability. --GPSLeo (talk) 08:08, 5 May 2019 (UTC)
- "Every named person depicted on Commons should have a Wikidata entry" do they ? Like I'm fine with there being a category of images of me being grouped.. I'm not so sure how I would feel about a wikidata page where people then start documenting my birthday and whatever else they can find about me online... —TheDJ (talk • contribs) 14:34, 6 May 2019 (UTC)
- @TheDJ: Valid point, but I should have mentioned "except Commoners", which I did below. If the person warrants a non-hidden category, we should have a Wikidata entry. Commoners' categories are usually hidden. Regards, Yann (talk) 15:36, 6 May 2019 (UTC)
- @Yann: Hmm. Someone else (certainly not me) decided I merit a non-hidden Commons category. Historically, Commons has had the lowest threshold of notability for people, with Wikidata a bit higher, and the various Wikipedias higher yet. This definitely means that Wikidata's threshold would be pulled down to match Commons', and I'm honestly not sure that's a good idea. It's one thing to group photos of relatively private individuals so that they can be found, and quite another to create a place where people can hang rather open-ended data about that person. I would think that in the European Union, especially, the latter would be pretty objectionable. - Jmabel ! talk 00:16, 7 May 2019 (UTC)
- Commons doesn't have a notability policy for categories, does it? Commons:Categories covers other things. Commons only has a policy about which files are in scope, a requirement that a category be non-empty, and a guideline on user categories. --ghouston (talk) 02:46, 7 May 2019 (UTC)
- We don't exactly have a notability policy, but we've been known to delete a category as frivolous. - Jmabel ! talk 04:51, 7 May 2019 (UTC)
- Commons doesn't have a notability policy for categories, does it? Commons:Categories covers other things. Commons only has a policy about which files are in scope, a requirement that a category be non-empty, and a guideline on user categories. --ghouston (talk) 02:46, 7 May 2019 (UTC)
- @Yann: Hmm. Someone else (certainly not me) decided I merit a non-hidden Commons category. Historically, Commons has had the lowest threshold of notability for people, with Wikidata a bit higher, and the various Wikipedias higher yet. This definitely means that Wikidata's threshold would be pulled down to match Commons', and I'm honestly not sure that's a good idea. It's one thing to group photos of relatively private individuals so that they can be found, and quite another to create a place where people can hang rather open-ended data about that person. I would think that in the European Union, especially, the latter would be pretty objectionable. - Jmabel ! talk 00:16, 7 May 2019 (UTC)
- @TheDJ: Valid point, but I should have mentioned "except Commoners", which I did below. If the person warrants a non-hidden category, we should have a Wikidata entry. Commoners' categories are usually hidden. Regards, Yann (talk) 15:36, 6 May 2019 (UTC)
- There are also real-world objects like Category:Wind turbine parts. There's no Wikidata item for such things, and I'm not sure if it should be created. Do you just have Depicts:Component? --ghouston (talk) 02:06, 5 May 2019 (UTC)
- "I have an objection if people who never edit Commons get to block creation of entries needed for Structured Data to work properly" How would you take it if someone said, say, "I have an objection if commons editors who never edit en.Wikipedia get to delete images needed for Wikipedia articles"? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 18:41, 6 May 2019 (UTC)
- @Pigsonthewing: This would be a valid objection if you were talking about the scope. But here it is just a strawman argument. That's why we have the policy that a file is in scope as soon as it is used in another Wikimedia project. Regards, Yann (talk) 04:49, 7 May 2019 (UTC)
- And no image used on a project has ever been deleted on Commons. Right. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 12:47, 7 May 2019 (UTC)
- @Pigsonthewing: Can't say "never", but... deleted for being out of scope? I'd be interested in seeing an example. Deleted as a copyright violation, certainly: being used on a project doesn't make it copyright-free or provide a license. - Jmabel ! talk 22:47, 7 May 2019 (UTC)
- And no image used on a project has ever been deleted on Commons. Right. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 12:47, 7 May 2019 (UTC)
- @Pigsonthewing: This would be a valid objection if you were talking about the scope. But here it is just a strawman argument. That's why we have the policy that a file is in scope as soon as it is used in another Wikimedia project. Regards, Yann (talk) 04:49, 7 May 2019 (UTC)
- @Yann: That's all well and good; but, however much I might agree with you, unless you can convince Wikidata admins of that position, or the general Wikidata community, we are no further forward. Jheald (talk) 19:08, 4 May 2019 (UTC)
- Bear in mind that there is also at least one admin on Wikidata who summarily deleted the item about himself, even though he is the subject of numerous pictures on Commons, and several non-hidden categories, apparently just because he doesn't want one to exist. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 18:41, 6 May 2019 (UTC)
- I am not too worried about contributors' entries in Wikidata. We can always have a separate policy for them. Yann (talk) 04:49, 7 May 2019 (UTC)
- I am not too worried about contributors' entries, either. I am worried about Admins acting ultra vires; and so should you be. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 12:47, 7 May 2019 (UTC)
- I am not too worried about contributors' entries in Wikidata. We can always have a separate policy for them. Yann (talk) 04:49, 7 May 2019 (UTC)
- Items about living people must comply with this policy: d:Wikidata:Living people. Sadly, it's not well written (for discussion of some of the issues, see d:Wikidata:Requests for comment/Privacy and Living People. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 18:49, 6 May 2019 (UTC)
Objects
- File:Binocular compound microscope, Carl Zeiss Jena, 1914 (6779276516).jpg? — Preceding unsigned comment added by Yann (talk • contribs) 06:12, 5 May 2019 (UTC) (UTC)
- @Yann: Not sure I see what you are driving at. Jmabel ! talk 16:50, 5 May 2019 (UTC)
- With old, and sometimes unique, objects like this, I don't know what depict statements to use. Regards, Yann (talk) 17:11, 5 May 2019 (UTC)
- There's an item for microscopes, unsurprisingly, d:Q196538. If you knew a model designation, it would probably be OK to create an item for it, since there are items like d:Q60021939. However, I'm not sure about something like "Carl Zeiss microscope", as a subclass of d:Q196538. There's no item for "Samsung mobile phone", for example. --ghouston (talk) 02:09, 6 May 2019 (UTC)
- Perhaps d:Q196538 with the manufacturer as a qualifier. Or brand, since it's hard to tell who really makes things these days. --ghouston (talk) 02:29, 7 May 2019 (UTC)
In another domain, I created Maccabees Chapel (Q63530582), but should we also have separate entries for the organs (there are 2), the stained glass windows, the pulpit, the bells (45 in total), etc.? Regards, Yann (talk) 10:59, 6 May 2019 (UTC)
- Wikidata is the database and it has its criteria for items. I thing very specific "models" of whatever should be there so we can create them. The question for us is quering which si difficult and not every Commons contributor is able to write efective queries or undertand Wikidata structure. So the trouble for this discussion is, we dont know much the structure or what we can query. I am pointing to the fact that if it is possible to list the above file in the list of microscope if itll have just Carl Zeiss Jena, 1914 item.Juandev (talk) 18:25, 8 May 2019 (UTC)
Criteria
For Structured Data on Commons to work properly, we need a Wikidata entry for
- Every person who has a non-hidden category (contributors' category are usually hidden).
- Every work of art needs a category for depict statements.
- Every identified species need a category for depict statements.
- Every public (city hall, post-office, etc.) or named building (church, etc.). This excludes non-notable private buildings, except some special cases.
- Every named street or road.
Criteria for objects, vehicles, and natural places need to be defined. Regards, Yann (talk) 11:14, 6 May 2019 (UTC)
- Yann, I agree with most of your above points; however Wikidata notability criteria are govern by Wikidata community, so any changes to d:Wikidata:Notability, swill need to be approved there. Two of the criteria there apply here:
- "It contains at least one valid sitelink to a page on Wikipedia, [...] or Wikimedia Commons." So if we have a category here we can create item there with it as a sitelink.
- "It refers to an instance of a clearly identifiable conceptual or material entity. The entity must be notable, in the sense that it can be described using serious and publicly available references." The first part covers most of your items, but second one can be more tricky.
- Also Wikidata discourages Autobiographical items, but non-hidden categories should cover it. --Jarekt (talk) 18:47, 6 May 2019 (UTC)
- The sitelink to a Commons category argument would be enough for Commons, but it was precisely rejected in Wikidata. The second point should indeed cover most cases. Regards, Yann (talk) 04:58, 7 May 2019 (UTC)
- "It refers to an instance of a clearly identifiable conceptual or material entity. The entity must be notable, in the sense that it can be described using serious and publicly available references." Are there categories, excluding * in */* by * categories, they do not fit this criteria? --GPSLeo (talk) 10:22, 7 May 2019 (UTC)
- In reply to Yann, it was only rejected because file depicts didn't exist at the time and the Wikimedia Commons community didn't see it as beneficial to themselves to "go over there" and vote it into policy, if the proposal would be opened next year it would probably pass. It failed because of a premature publication as I proposed it to optimise file depicts before their launch rather than run into the problems like we do now and try ro solve it later. I say wait some time after the current discussion closes and re-open it after the need has been proven great enough that passing it would be uncontroversial. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:12, 7 May 2019 (UTC)
- Also regarding #3 (number three), this should technically already be do-able by using Wikispecies to create a species page first and then creating an item on Wikidata. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:14, 7 May 2019 (UTC)
Personally I think that every Wikimedia Commons category should have a Wikidata item by default, but I can understand the "Wikidata spampocalypse" arguments because they are completely valid, in fact we can it to spill over to all Wikimedia websites to some extend. I read about how Wikidata is being used by third (3rd) parties and certain services such as Amazon's Alexa and Google's Google Assistant heavily rely on Wikidata as well as basically every major service which crawls the internet, simply being on Wikidata adds you to "the intellectual zeitgeist" or "the documented sum of human knowledge" and simply uploading things related to your company would easily let's you circumvent Wikidata's notability standards. If we do this the Wikidata (and Wikimedia Commons) "spampocalypse" will become inevitable, though as an inclusionist this is something I would hail as it would make Wikimedia huge leaps closer to becoming "the sum of all human knowledge". It is also important to note that if this doesn't happen file depicts will become "essentially inferior Commonswiki categories" and nothing else, while using Wikimedia Commons categories I could place someone in "John Smith" while with Wikidata items I would probably be limited to "Lawyers in New Zealand" or something.
Either Wikidata (and by extend Structured Data on Wikimedia Commons) will utilise the existing community-powered Wikimedia Commons category system or we will be forced to use extremely overarching umbrella items for depicting things we've already had categories for for over a decade. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 20:06, 7 May 2019 (UTC)
- I think we do not run into trouble if we do not change the notability criteria. A short look at d:Wikidata:Requests for deletions shows not deletion request for an item liked to a commons category. I mean, if we import every scientific article in the database we also can create an item for "wood table" or "crate" --GPSLeo (talk) 21:44, 8 May 2019 (UTC)
Depicts statements now available in the UploadWizard
The ability to add optional structured "depicts" statements in the UploadWizard is now available. When opening the UploadWizard, the first major change you'll see is the introduction of a tab for adding data to a file towards the end of the process.

Once you've reached the point to add data, you'll see the ability to edit depicts statements.

Please note that adding structured data is not required, and files are uploaded and published before the step to add data. The step can be skipped completely.
Feedback about the release - questions, comments, bugs found, design concerns, etc. - can be posted on this page.
Thanks to all the community for the help in planning, designing, and testing this new feature. Additional statement support for file pages and the UploadWizard will be added in the coming weeks. Keegan (WMF) (talk) 19:33, 7 May 2019 (UTC)
- Question I'm uploading five pictures of a churchyard. Why can't I apply the same depicts statement to all of them in one go? Or can I? Rodhullandemu (talk) 09:05, 11 May 2019 (UTC)
- Hello. We have not yet enabled an "apply to all" feature. It will certainly be coming soon, but we need to design it with the big picture in mind and we're still working on how such a feature would work with campaigns, other statements besides depicts, additional API calls, etc. Thanks for your patience, and we'll post an update when the feature is ready (perhaps as part of the release that will support more statements beyond depicts). RIsler (WMF) (talk) 21:21, 14 May 2019 (UTC)
Hide Structured Data tab?
Is there any community tool to remove the SD tab on the file description? I simply do not want to be bothered with the clutter. (I see Hide Caption Gadget doesn't hide this) — regards, Revi 19:53, 24 April 2019 (UTC)
- I’d gladly use a tool to hide the SD tab, too. And too bad the captions cannot be moved there. -- Tuválkin ✉ ✇ 23:44, 24 April 2019 (UTC)
- Revi, in the moment this works – add the following into your common.css or as I would prefer it into the Wikimedia section of your browser addon settings (I use Stylus and know xStyle):
/* Hide tab for structured data on file pages */ #ooui-php-8 { display: none; }
- Because this ID is very generic or abstract (there are even more of this type) it is possible that the naming changes in near future. — Speravir – 02:20, 25 April 2019 (UTC)
- Yes, I noticed immadiately the lame ID they chosen; I suppose it matches both previous “work” (CSS classes
oo-ui-buttonElement-framedandoo-ui-buttonElement-button) and the JPEG screenshot they presented this new gizmo with.
- It’s a sad state of things when power users think they (we) are being skewered by supposed code gods and then turns out that they are just script kiddies who were given admin flags and running orders to wreck the whole thing and fast. I mean I’d rather see Wikipedia and Commons destroyed with finesse and razor sharp tech skills, if it has to happen.
- ›sigh‹ Help me here: I worked in a couple notable software projects in the past decade (at T.A.P. and C.G.D., two big-cheese T.L.A.s in my country) and back then people who’d pull out stunts like these (crappy human-readable labelling and {{badjpg}}s) would be demoted to the cooffee refilling service — is this acceptable nowadays, though, or is this just a Silicon Valley thing?, or is the WMF just doing a really bad job at hiring techies, on top of all other blunders?
- -- Tuválkin ✉ ✇ 10:30, 25 April 2019 (UTC)
- Honestly, Tuválkin, you’re entitled to your own opinion on the skill-level of WMF employees, but I think that musing aloud on the alleged incompetence of people, moreover on a page that they likely read as part of their job, is neither helpful nor polite. If you have a point to make, I’m sure you can make it without that, no? Jean-Fred (talk) 12:51, 25 April 2019 (UTC)
- Jean-Frédéric, screenshots as JPEGs and auto-generated IDs is not «alleged incompetence», as there’s not possible allegation of the competence thereof. Likewise it is not «helpful nor polite» to have to work as a volontary in a non-profit environment with hired help which is incompetent and yet their bosses seem to be ecstatic. I see no solution, and therefore I’m reduced to sporadic outbursts of cynical frustration. What do you suggest instead?
- As for the WMF devs, I understand that’s unpleasant to be challenged publicly, but the solution should be simple (in this case it’s PNGs and human-readable labels).
- -- Tuválkin ✉ ✇ 09:54, 30 April 2019 (UTC)
- Honestly, Tuválkin, you’re entitled to your own opinion on the skill-level of WMF employees, but I think that musing aloud on the alleged incompetence of people, moreover on a page that they likely read as part of their job, is neither helpful nor polite. If you have a point to make, I’m sure you can make it without that, no? Jean-Fred (talk) 12:51, 25 April 2019 (UTC)
- Yes, I noticed immadiately the lame ID they chosen; I suppose it matches both previous “work” (CSS classes
- FYI: the "lame ID" wasn't chosen - it is an automatically generated unique id for OOUI DOM nodes that are generated in HTML and progressively enhanced in JS later on.
- I'd also recommend against using such id (
#ooui-php-8) as a selector because if other elements are added, it's quite likely that that ID would be another node entirely. A good amount of nodes have awbmi-prefixed classname & using those as a selector would be safer. Maybe something like:.wbmi-tabs .oo-ui-tabSelectWidget > *:nth-child(2) { display: none; }
- Above CSS might also break if things get moved around, but at least it's slightly less likely to suddenly hide something completely different unexpectedly. Mmullie (WMF) (talk) 18:48, 25 April 2019 (UTC)
- THX for info, and you are right, of course, with the note regarding the selector. — Speravir – 22:30, 27 April 2019 (UTC)
- Mmullie (WMF), thanks for explaining that what’s supposed to be a human-readable label was “auto-generated” (as if auto-generated is necessarily gobbledygook — it’s 2019, guys, it’s not like something got caught in the en:punched tape reader!). This explanation is enlightning, as it is your report underlying you warning about not using those IDs, nor indeed class names, to reference to HTML elements in the code your gizmo is sending out to the browsers of millions of users world-wide. While your warning is helpful (and I can sicerely appreciate you even assisting users to try avert their sight from very gizmo your team have been creating), what kind of twisted coding principles are being used when an ID is not stable? That’s the whole idea of an ID — that it will be usable in a stable, predictable manner to reference to the same element, no matter how elements are added over and swapped around. If each ID just mimics a z-order or whatever volatile, not human-readable listing order, then the whole goal of having IDs is lost. -- Tuválkin ✉ ✇ 09:54, 30 April 2019 (UTC)
- @Tuvalkin: I’m not much of a front-end person myself, but as far as I understand, IDs being auto-generated and using classes to refer to objects is actually very much part of how things are done in 2019 (when using frameworks such as React, Vue.js or indeed OOUI). Of course, feel free to disagree with the ways web developement has evolved, but I don’t think this is somehow proof of WMF incompetence (if anything, quite the contrary really). Jean-Fred (talk) 18:47, 17 May 2019 (UTC)
- Mmullie (WMF), thanks for explaining that what’s supposed to be a human-readable label was “auto-generated” (as if auto-generated is necessarily gobbledygook — it’s 2019, guys, it’s not like something got caught in the en:punched tape reader!). This explanation is enlightning, as it is your report underlying you warning about not using those IDs, nor indeed class names, to reference to HTML elements in the code your gizmo is sending out to the browsers of millions of users world-wide. While your warning is helpful (and I can sicerely appreciate you even assisting users to try avert their sight from very gizmo your team have been creating), what kind of twisted coding principles are being used when an ID is not stable? That’s the whole idea of an ID — that it will be usable in a stable, predictable manner to reference to the same element, no matter how elements are added over and swapped around. If each ID just mimics a z-order or whatever volatile, not human-readable listing order, then the whole goal of having IDs is lost. -- Tuválkin ✉ ✇ 09:54, 30 April 2019 (UTC)
- Made a gadget for that use case, HideStructuredDataTab. Hope that helps. Jean-Fred (talk) 18:47, 17 May 2019 (UTC)
It's sad (or sadistic?) that we're still making it harder for the large majority of Wikimedia Commons users to see any information on the media by pushing down the descriptions with giant white boxes (which keep being falsely named "captions" even when empty). I understand the CSS fiddling but we should really not force people to use such tricks to survive. Nemo 20:15, 25 April 2019 (UTC)
Identical depicts statements
I think identical depicts statements may not be useful. On wikidata a warning would pop up.--Roy17 (talk) 12:14, 17 May 2019 (UTC)
- @Roy17: On an image, you could notionally have two different bycycles with different qualifiers (regions of a picture, different colors, having objects like saddlebags attached etc). Because they haven't deployed these other features yet, it seems like it doesnt make sense, whereas it will: also it doesnt harm the current functionalities to have redundancy (I.e. search).Sadads (talk) 15:00, 17 May 2019 (UTC)
Captions cannot be corrected
Somebody entered captions on one of my images which need to be corrected. However, when I change the text and try to publish it, I get the response Forbidden. How can I handle this? --Uoaei1 (talk) 11:53, 22 May 2019 (UTC)
- I think more details would be helpful here :)
- Which image is it? What in the page tells you “Forbidden”?
- Thanks, Jean-Fred (talk) 13:21, 22 May 2019 (UTC)
- @Jean-Frédéric: The image is File:Freiburg Münster rechtes Seitenschiff Märtyrerfenster 01.jpg. I want to change the English caption, so here is what I do: I click on Edit in the Captions frame, edit the text, and press Publish or Enter. The text Forbidden appears under the changed text box, and the change is not accepted. --Uoaei1 (talk) 14:02, 22 May 2019 (UTC)
- @Uoaei1: Thanks for the clarifications. I tried and have not been able to reproduce (although given that I’m a sysop, that does not say much :-/). Jean-Fred (talk) 14:22, 22 May 2019 (UTC)
- @Uoaei1 and Jean-Frédéric: I have less user rights than Uoaei1 as far as I can tell, and I was able to edit the English caption as well. (I removed the trailing period, since on Wikidata descriptions aren’t full sentences, though I’m not aware what the convention for Commons structured captions is. Feel free to revert.) --Lucas Werkmeister (talk) 16:31, 22 May 2019 (UTC)
- @Lucas Werkmeister and Jean-Frédéric: Seems to be a problem with the browser. With IE11 it does not work, but with Chrome it does. --Uoaei1 (talk) 18:55, 22 May 2019 (UTC)
- @Uoaei1: Thanks for the clarifications. I tried and have not been able to reproduce (although given that I’m a sysop, that does not say much :-/). Jean-Fred (talk) 14:22, 22 May 2019 (UTC)
- @Jean-Frédéric: The image is File:Freiburg Münster rechtes Seitenschiff Märtyrerfenster 01.jpg. I want to change the English caption, so here is what I do: I click on Edit in the Captions frame, edit the text, and press Publish or Enter. The text Forbidden appears under the changed text box, and the change is not accepted. --Uoaei1 (talk) 14:02, 22 May 2019 (UTC)
Adding qualifiers to Depicts
Testing for adding qualifiers to Commons:Depicts statements on the file page and in the UploadWizard is now available on Test-Commons: https://test-commons.wikimedia.org/wiki/Main_Page
Adding qualifiers allows users to further develop depicts statements. For example, depicts: house cat can be extended into depicts: house cat[color:black]. You can find qualifiers in the "Structured data" tab on the file page, or in the "Add data" tab in the UploadWizard.
Currently supported qualifiers are: shown with features, color, wears, applies to part, quantity, eye color, and shape.
Once you've tested qualifiers, please leave your feedback on this page with any questions, comments, or concerns you might have about the feature. (And thank you Lucas who already has, above!) When testing is complete, the qualifiers will be released to Commons both on the file page and in the UploadWizard. Quiddity (WMF) (talk) 22:16, 22 May 2019 (UTC)
Qualifiers on depicts
Hello, after tried the new qualifiers on depicts statement on TestCommons I must say that I'm impressed with this neat new feature and I'm looking forward for further development.--Vulphere 12:33, 23 May 2019 (UTC)
Feedback about qualifier
- It was a little bit strange the list of default qualifiers, is this just random examples?
- Why do not use qualifiers as at Wikidata, give some default items (better than this ones, and that changes do to the entry), but give us the possibility to choose a wilder variety.
- With this qualifiers I can't describe anything, I can't properly describe a person, for example the hair colour, the skin tone,... imagine a bird, a fish... a paint... would be better took the Wikidata way to this.
- It's quite difficult to understand some items without explanation (as we have at Wikidata), for example "shown with features", we already have this explanations, it's a matter of implement it.
- Why the plained-texts, not links?
- It should be links, and if they return a category here, from the wikidata item, also show this.
- Why "quantity" have this + and - ? Seems not necessary.
- This should have a "unit" as optional as in Wikidata...
- Individual "edit" button would be nice, image a media with a lot of entries: d:Q10301958, imagine that you want to change one thing...
- The so thin distance between the items could generate an accessibility issue.
- And stills weird a separate tab for the data and the no mirror possibility from a Wikidata item.
- Thank you for all the efforts, it's a good addition. -- Rodrigo Tetsuo Argenton m 07:37, 25 May 2019 (UTC)
Bain collection
- How can we link between the Library of Congress' Bain collection at Wiki Commons and the same image at Flickr Commons and maybe add that link to Wikidata?
We migrated the entire Bain Collection from the Library of Congress to Wiki Commons and those images also appear in Flickr Commons with crowd sourced biographical information on the people pictured. Can anyone see a way that the identifiers we store at Wikimedia Commons can match any identifier at Flickr Commons so we can migrate the Flickr link to Wikidata and to Wiki Commons automatically? Here is an example where I migrated one by hand: At Walter Simpson Dickey (Q7966031), the entry for the person in the image, I added the link to Flickr which has unique biographical information on the person. Can anyone see a way to automate the linkage? The Wikimedia Commons image uses an LCCN identifier (LCCN2014702600) File:Walter_S._Dickey_LCCN2014702600.tif and the Flickr Commons entry has an identifier: Walter_S._Dickey at Flickr (ggbain.22649). You can see how I added the link from Flickr to Wikidata as an entry for "described at URL".I also added the link to Commons. Is it possible to automate the process? Is there anyplace where "LCCN2014702600" links to "ggbain.22649"? Please note that Flickr is down today as they are migrating the entire database to new servers. --RAN (talk) 15:04, 22 May 2019 (UTC)
- While not sure about the structured data side of this, we should certainly have a template that both puts the image in Category:George Grantham Bain Collection and has a parameter for the Flickr ID, and which automatically generates the URL on Flickr. - Jmabel ! talk 16:51, 23 May 2019 (UTC)
- You would have to investigate MARC records or the LOC API to map LCCNs to specific LOC collection image numbers (it can be done). I do not understand why you would want to link Flickr photos, they are neither the source, nor the LOC original highest resolution image, it's better to get haphazard Flickr readers to use the LOC original catalogue entry. --Fæ (talk) 16:58, 23 May 2019 (UTC)
- Read a few of the entries at Flickr Commons, the Library of Congress has the name of the person on the glass plate, only Flickr Commons has crowd sourced data that identifies the person as someone in Wikipedia, and in some cases an exact date and the circumstances of the photo, based on news articles of the time. The current tranche is 1921. Flickr also has corrections where the name of the person pictured is misspelled or been misidentified. I have been adding the people not in Wikipedia into Wikidata and then creating a category for that person here. Flickr is down for a few days while they migrate the archive to new servers ... possibly deleting several million images. They have reneged on their promised 1TB of free storage. Yahoo sold the website to Verizon which sold it to SmugMug, and now they are looking to generate more revenue to pay for the purchase. here is an example of someone not in WIkipedia: Elkan Cohn Voorsanger. RAN (talk) 23:33, 23 May 2019 (UTC)
- Another point: The dates are off by 20 years here at Commons, Flickr correctly has the current tranche of photos as from 1921. Commons loaded them as the year "1900". See File:O. Saenger LCCN2014713020.jpg where I changed the date. https://www.flickr.com/photos/library_of_congress/33828381198 RAN (talk) 04:10, 27 May 2019 (UTC)
- Any progress on this issue? I still do not see a common identifier between Flickr Commons and the same image at Wikimedia Commons "LCCN2014702600" and "ggbain.22649. When I try an laod the image from Flickr to here it finds the correct image already loaded here. — Preceding unsigned comment added by Richard Arthur Norton (1958- ) (talk • contribs) 22:08, 2 June 2019 (UTC)
- Another point: The dates are off by 20 years here at Commons, Flickr correctly has the current tranche of photos as from 1921. Commons loaded them as the year "1900". See File:O. Saenger LCCN2014713020.jpg where I changed the date. https://www.flickr.com/photos/library_of_congress/33828381198 RAN (talk) 04:10, 27 May 2019 (UTC)
- Read a few of the entries at Flickr Commons, the Library of Congress has the name of the person on the glass plate, only Flickr Commons has crowd sourced data that identifies the person as someone in Wikipedia, and in some cases an exact date and the circumstances of the photo, based on news articles of the time. The current tranche is 1921. Flickr also has corrections where the name of the person pictured is misspelled or been misidentified. I have been adding the people not in Wikipedia into Wikidata and then creating a category for that person here. Flickr is down for a few days while they migrate the archive to new servers ... possibly deleting several million images. They have reneged on their promised 1TB of free storage. Yahoo sold the website to Verizon which sold it to SmugMug, and now they are looking to generate more revenue to pay for the purchase. here is an example of someone not in WIkipedia: Elkan Cohn Voorsanger. RAN (talk) 23:33, 23 May 2019 (UTC)
Avoiding repetitive data entry
Great job on the depicts screen in UploadWizard! Being that more functionality is being built into structured data on Commons, it's starting to get repetitive having to enter similar data twice. It would be very helpful to have the following functionalities in the wizard:
- A button to make the caption and description identical (minus wikimarkup). Most of my descriptions are a phrase or sentence anyway, and it would be helpful not to have to copy-paste all of them twice.
- Auto-suggesting categories from the depicts statements, and vice-versa. Bonus points if it can figure out categories that are overlaps of subjects and locations (which would be easier if/when the "located in the territorial administrative entity" property is enabled).
Also, the captions should really be under the structured data tab. Thanks! Antony-22 (talk) 13:59, 28 May 2019 (UTC)
Uploading multiple images
If you are uploading multiple images in one hit, it is not clear what is happening with the depicts. Is it going on all of them or just one of them. It seems as soon as you publish one of them, it doesn't let you go back to add the depicts the others, which is begging the question of what is happening with the other images, are they getting a depicts of not? The workflow is quite confusing, whereas it seems more straightforward with the caption (you either fill it in manually or do a "copy"). The depicts should be handled in the same way. Kerry Raymond (talk) 04:19, 29 May 2019 (UTC)
- That's an interesting point to consider from the user experience perspective, thank you for leaving it. Keegan (WMF) (talk) 19:44, 29 May 2019 (UTC)
I am adding captions and depicts but I how do I edit them?
Having added captions and depicts on my recent uploaded images, I now wish to check them and probably modify some. To my surprise, they were not present in the File meta-data. What has happened to it? Kerry Raymond (talk) 04:05, 29 May 2019 (UTC)
- Not sure what you mean exactly by “they were not present in the File meta-data”? Checking for example File:4WDs at Inskip Point, 2009.jpg, I can see the caption “4WDs at Inskip Point, 2009” just below the picture ; and by switching to the “Structured data” tab, I can see the depicts:Q6038192. Jean-Fred (talk) 09:04, 29 May 2019 (UTC)
- I do not see them when I go into either Edit (source) or Edit (visual). Information about a file needs to be stored there. Kerry Raymond (talk) 20:52, 29 May 2019 (UTC)
- I note it clearly says at Commons:File captions that they are stored on Commons not Wikidata. Kerry Raymond (talk) 20:59, 29 May 2019 (UTC)
- Editing these in Edit (source) is basically the "serialization/unserialization" proposal I've made several times and been ignored. But (for what it's worth) you should be able to edit them in the same place where you see them on the file page. Is that not working for you? - Jmabel ! talk 21:53, 29 May 2019 (UTC)
- OMG, you mean on the "view" photo screen, we have a means to *edit* certain information, which isn't available in the Edit screen. Did we just abandon all UI design principles? Viewing is one modality, editing is another. Also, if it's not in the File, how can we can tools like AWB to work with it? There are often times when you need to fix a batch of misidentified photos. Recently I got confused by a batch of photos of sugar mills and mistook Racecourse Mill for Pleystowe Mill. Right now, it would seem that using plain old Edit or tools like cat-a-lot or AWB, that a user could change information in the File, e.g. description, categories, but not update the caption and depicts to match. This seems to me to be a recipe for inconsistency, particularly so if the user who uploaded the photos didn't supply the caption/depicts in the first place and someone else subsequently added them based on the description originally provided. All this information needs to be editable in the same place. By all means, squirrel away a *copy* on Wikidata (or wherever captions/depicts are being hidden, nobody has answered yet where they are), but keep it in the File, so when it is edited, it gets updated. Kerry Raymond (talk) 13:54, 30 May 2019 (UTC)
- “nobody has answered yet where they are” → This is explained at Commons:File_captions#Where_are_captions_stored?:
Captions are stored on Wikimedia Commons, as part of Wikibase. They are not stored on Wikidata. While Wikibase is indeed powering Wikidata, it is also deployed here on Wikimedia Commons.
- OMG, you mean on the "view" photo screen, we have a means to *edit* certain information, which isn't available in the Edit screen. Did we just abandon all UI design principles? Viewing is one modality, editing is another. Also, if it's not in the File, how can we can tools like AWB to work with it? There are often times when you need to fix a batch of misidentified photos. Recently I got confused by a batch of photos of sugar mills and mistook Racecourse Mill for Pleystowe Mill. Right now, it would seem that using plain old Edit or tools like cat-a-lot or AWB, that a user could change information in the File, e.g. description, categories, but not update the caption and depicts to match. This seems to me to be a recipe for inconsistency, particularly so if the user who uploaded the photos didn't supply the caption/depicts in the first place and someone else subsequently added them based on the description originally provided. All this information needs to be editable in the same place. By all means, squirrel away a *copy* on Wikidata (or wherever captions/depicts are being hidden, nobody has answered yet where they are), but keep it in the File, so when it is edited, it gets updated. Kerry Raymond (talk) 13:54, 30 May 2019 (UTC)
- Editing these in Edit (source) is basically the "serialization/unserialization" proposal I've made several times and been ignored. But (for what it's worth) you should be able to edit them in the same place where you see them on the file page. Is that not working for you? - Jmabel ! talk 21:53, 29 May 2019 (UTC)
- I note it clearly says at Commons:File captions that they are stored on Commons not Wikidata. Kerry Raymond (talk) 20:59, 29 May 2019 (UTC)
- (As I believe I wrote that sentence, please let me know if it is unclear so I can improve it. Happy to add a “...but not as part of the wikitext” or smth to that effect.) Jean-Fred (talk) 20:04, 30 May 2019 (UTC)
- Went ahead and tried to be more explicit. Jean-Fred (talk) 17:37, 31 May 2019 (UTC)
- (As I believe I wrote that sentence, please let me know if it is unclear so I can improve it. Happy to add a “...but not as part of the wikitext” or smth to that effect.) Jean-Fred (talk) 20:04, 30 May 2019 (UTC)
Archiving mess-up
It appears we have two archive pages, created and fed by two different bots
- Commons talk:Structured data/Archive/2019 (ArchiverBot)
- Commons talk:Structured data/Archive 2019 (SpBot)
Does anybody have a good tool to merge the two? Jheald (talk) 17:21, 2 June 2019 (UTC)
No constraints on qualifiers?
https://test-commons.wikimedia.org/w/index.php?diff=1611 --Roy17 (talk) 22:29, 22 May 2019 (UTC)
- Vandal heaven. - Jmabel ! talk 00:05, 23 May 2019 (UTC)
- @Roy17: Over on Wikidata, there are no string restrictions on the properties you can use, nor on the values you can set.
- On the reason why this is so, I find this 2013 post by User:Denny, Restricting the World, very enlightening.
- There are, however, property constraints to flag things that do not make sense, such as eye color (P1340)=Michigan (Q1166) − I expect that we develop something like that for here as well, to surface issues.
- @Jmabel: I’m curious, why do you think this is particularly “vandal heaven”? After all, in the non-Wikibase parts of Wikimedia Commons, we also do not restrict editing − for example, we technically allow such categorisation (an edit which, incindentally, persisted for 2 years before I noticed it :-).
- Jean-Fred (talk) 08:56, 23 May 2019 (UTC)
- Vandalism is one consequence, but I am more concerned about accidental mistakes. For example, white is a colour, but is also commonly a surname and a type of humans. Square is a shape, but is also a kind of public space. If a user chooses an item of a wrong group, a constraint warning would be helpful.--Roy17 (talk) 10:55, 23 May 2019 (UTC)
- @Jean-Frédéric: Because I don't think at this time this content is being comparably well monitored. - Jmabel ! talk 16:49, 23 May 2019 (UTC)
- Any short summary of the Dennys Restricting the World? Juandev (talk) 14:15, 8 June 2019 (UTC)
- @Juandev: Don't restrict relationships, you can put Paris in a country named "goat cheese" if you want. — Jeff G. ツ please ping or talk to me 15:15, 8 June 2019 (UTC)
- Any short summary of the Dennys Restricting the World? Juandev (talk) 14:15, 8 June 2019 (UTC)
- @Jean-Frédéric: Because I don't think at this time this content is being comparably well monitored. - Jmabel ! talk 16:49, 23 May 2019 (UTC)
- Vandalism is one consequence, but I am more concerned about accidental mistakes. For example, white is a colour, but is also commonly a surname and a type of humans. Square is a shape, but is also a kind of public space. If a user chooses an item of a wrong group, a constraint warning would be helpful.--Roy17 (talk) 10:55, 23 May 2019 (UTC)
URL link to Structured data tab
Is there a way to link Structured data tab via URL. I.e. someone can follow a link and display file with Structured data (no need to click on Structured data tab)? Juandev (talk) 23:01, 8 June 2019 (UTC)
- @Juandev: It seems you can only link to
#ooui-php-8, e.g. File:Commons testwiki, rendering problem.png#ooui-php-8. But that doesn't open the tab and is also just a dummy, unstable ID and link then (see #Hide Structured Data tab?). --Marsupium (talk) 23:42, 8 June 2019 (UTC)
I see.07:14, 9 June 2019 (UTC)Juandev (talk)
Qualifiers testing

So here are some of my points from qualifiers testing:
- any way to explain, what the qualifiers means? Fairly I dont understand some of them (e.g. shown with features), what they mean and how to fill their values. You may say, you can have a look to Wikidata, but do we want all Wikimedia Commons users to study Wikidata? I think no, we should have it as clear as possible. + I think, that some of the translations to Czech are missleading (eg. quantity = počet instancí (en: number of instances).
- on the other side if I think, I undertand the qualifier, I dont know how to fill it with values - e.g. applies to part. What if I set =yes (Q6452715) ?
- the graphical design looks to me good and undersandable
- speakers of some languages might have a problem with values. E.g. dog can be black and cat can be black, but in Czech dog is "černý", but cat is "černá". So for Czech speakers filing qualifiers would not be so smooth as for English as they should thing about the infinitve word. What about some gramatical aliases for certain languages, whout it be possible? What I can see now, that in some languages, this is fixed by d title, so instead of title Green in pl there is title Green color, which makes it more understandable. So this may help to fix the problem I am writing above.
- for those, who are not deeper familliar with Wikidata, what are quantifiers? Do they represent Wikidata items? Will be there infinite number of qualifiers? How new qualifiers could be added?
- see the rendering problem I have encountered in FF
- This is not caused by rendering, but by the fact, that you can save even you have no value for the another quantifier. So you cannot save, when first quantifiers is not selected, but you can save, when others quantifiers are null. Is this a bug than? But I also see, this is happening before I reload the page. So if you reload the page, there are no empty "lines" as before. Juandev (talk) 14:10, 8 June 2019 (UTC)
- now its slightly confusing that you can add more statements, becuase if you add the firest, there is an option to start editing the qualifiers, so this may be confusing some people
- could we set quantity automaticaly to 1 if not set? Why we can set nengative quantity? For what this is usefull in file description?
Juandev (talk) 14:02, 8 June 2019 (UTC)
- @Juandev: Thank you for testing and leaving feedback. The team will look it over. Keegan (WMF) (talk) 17:44, 10 June 2019 (UTC)
Mirror from WMC leaves no block of SD
I have tried to upload a file to test wiki, than I got its mirror from Wikimedia Commons[] and I have realised, I cannot add any structured data. Juandev (talk) 13:15, 8 June 2019 (UTC)
- The test environment is configured to mirror content as the wikis do. It can be a problem if uploading a duplicate file (as you ran into), but it's necessary for making sure changes don't break the configuration. Keegan (WMF) (talk) 20:53, 11 June 2019 (UTC)
Increased number of edits on d:Property:P180
Maybe it's the GUI here, but we get more odd edits on that page on Wikidata. Mostly by people trying to describe an image on Commons. In the meantime, the page is semi-protect, but this still happens with autoconfirmed users. Jura1 (talk) 06:41, 12 June 2019 (UTC)
Qualifiers on depicts statements
I just noticed that qualifiers on depicts statements went live on Test Commons. Looks exciting, and I assume you’re interested in feedback :)
- Neither the qualifier property nor the value are linked: they are just shown as plain strings. This makes it impossible to validate that they’re correct: for example, the value for an “eye color” qualifier should be blue, the eye color, and not blue, the color. Also, the work-around Jean-Frédéric mentioned above doesn’t work due to this – as far as I can tell, it’s not possible at all to see the item ID of a qualifier value in the UI, neither in view mode nor in edit mode. (You can get it via the API, of course.)
- Speaking of which, why is “eye color” a possible qualifier? That should be a property of the value item, not of the particular “depicts” statement.
- The input for “quantity” has two sets of plus/minus buttons, one by OOUI to the left/right of the input and one, presumably by the browser, inside it. (I’m on Firefox 67 under GNOME 3.30, looking at https://test-commons.wikimedia.org/wiki/File:Non-existing.JPG.) --Lucas Werkmeister (talk) 11:39, 22 May 2019 (UTC)
-
- I agree with Lucas Werkmeister on these points. How possible qualifiers were chosen? Why are they hard coded? Ayack (talk) 09:45, 23 May 2019 (UTC)
-
- I agree with you and as with Ayack I'm wondering about the how possible qualifiers were chosen? What the rationale behind them?.--Vulphere 12:35, 23 May 2019 (UTC)
-
- Plaintext is a real problem, I didn't get this, is this a bug? -- Rodrigo Tetsuo Argenton m 06:50, 25 May 2019 (UTC)
- Lucas Werkmeister, imagine a paint, and you include as a depict: "person", eye colour could be a qualifier of that person, also hair colour, the problem is the way that they present that to us. -- Rodrigo Tetsuo Argenton m 07:40, 25 May 2019 (UTC)
- @Quiddity (WMF): Could you explain us how possible qualifiers were chosen? They don't match those listed by the community on Properties table. Thanks. Ayack (talk) 08:25, 3 June 2019 (UTC)
- @Keegan (WMF): Any answer please? Ayack (talk) 18:15, 12 June 2019 (UTC)
Where on Wikidata
I wonder, that WMC files are already present on Wikidata also, arent they? Will they be in special ns? Will they be publicaly available? When? Juandev (talk) 23:03, 8 June 2019 (UTC)
- I’m not sure I understand your question − what do you mean by “present on Wikidata”?
- As far as I know, no, Commons files are not present on Wikidata (except in the sense that every Commons file has a 'shadow presence' on all wikis, eg d:File:Example.jpg).
- Jean-Fred (talk) 11:54, 9 June 2019 (UTC)
It was somewhere said by development team, that every file will have its page on Wikidata. Juandev (talk) 06:05, 12 June 2019 (UTC)
- This is not something that I'm aware of from the development team. That's up to the communities to decide. Keegan (WMF) (talk) 17:27, 12 June 2019 (UTC)
- No, not every file will have a page on Wikidata. You're probably mixing up concept. Every file here on Commons will have a structured mediainfo item here on Commons.
- So for example the file File:Tonicella insignis.jpg has mediainfo M5150233 which you can see
- In some cases the depicted work is notable enough to (already) have an item of it's own. See for example File:Sandro Botticelli - Madonna and Child with St. John the Baptist - 2014.85 - Indianapolis Museum of Art.jpg. This file already links to Madonna and Child with St. John the Baptist (Q27897025) in the Wikitext. The file itself has mediainfo M65747301 in which you can also see the link with Wikidata.
- Does this clarify it for you? Multichill (talk) 17:49, 12 June 2019 (UTC)
- Thx, now I understand it well. Hope, we can have here than the oportunities of SPARQL as on Wikidata or something less techy. Juandev (talk) 08:05, 13 June 2019 (UTC)
Logic behind SD deployment
Hi, I don't understand the logic behind the deployment of Structured Data on Commons. I expect to start from the general going to the particular, but the first deployed item was Captions, which is very minor issue in the grand scheme. Then we have Depicts, and then Qualifiers, when we still don't know where and how the item for the files themselves will be stored. Before these items, I expect to have a general framework which need to include the important parts like Author, Licence, Date, Source, etc. Could you please explain when this will be available, and how and where they will be stored? I would like to see a general design with a graphic showing where and how each item is stored. Regards, Yann (talk) 05:16, 12 June 2019 (UTC)
- They said, they will go peice by piece not to confuse WMC community, but deffinitely to see hole framework know would be great. Juandev (talk) 06:10, 12 June 2019 (UTC)
- (edit conflict)
- Hi Yann,
- Have you seen Commons:Structured_data/Development and the roadmap at File:Roadmap for Structured Commons development - version 2017-10-31.pdf? Keegan or Sandra would be able to comment better where we are on it right now (I believe it has shifted a bit) but I understand it still holds.
- Your raise interesting questions, and while I don’t have special knowledge of the planning let me try to answer it. I think part of the issue is to focus on the user-facing features, which overlooks all the "under-the-hood" work. For example, captions were indeed the first specific element to be deployed, last January − but behind that limited feature, was the installation and enablement of a whole new extension, WikibaseMediaInfo (itself was the culmination of months for work on multi-content revisions).
- Similarly, depicts: is a fairly contained release − but with it goes significant work in developing the search infrastructure around statements in general.
- So, I don’t know if I’m being clear, but my understanding is that we are indeed starting from the very general − but every few steps in the general, we get a new small feature which is now made possible.
- Regarding “how the item for the files themselves will be stored”: my understanding is that all this information will live in MediaInfo, in the Wikibase instance of Commons − where depicts: (and captions) are already stored. As for design documents, would File:Structured Data on Commons - which information goes where - version 2017-10-31.png and File:MediaInfo Entity Page.png be what you are looking for?
- Hope this helps! (and if anyone notices mistakes in the above, please do correct me ^_^)
- Jean-Fred (talk) 07:12, 12 June 2019 (UTC)
- Hi Jean-Fred,
- I would like to see a complete schema, not a mock up.
- Among unresolved issues are,
- Who are the notable vs. non-notable editors? Who will decide that and how is it decided? (at least you should be able to produce criteria on which this would be decided)?
- Currently some depicted items have their own Wikidata entry. Will that be the general case? Who will decide that and how is it decided?
- I see that these fundamental questions yet not properly addressed, and the current deployment, as putting the cart before the
oxhorse. - As for the roadmap, it seems way behind schedule if I read correctly page 12. Regards, Yann (talk) 10:23, 12 June 2019 (UTC)
- Hi Yann. Jean-Fred has it mostly right, as far as the technical work and deployment goes. The software is being implemented in large part to make sure the technology works, without major disruption. Structured data items are stored on Commons in Wikibase, as Jean-Fred also mentions, with Captions being stored as wikitext within Wikibase. The remaining questions you raise are those of however the community decides to organize and implement a schema. There have been several discussions about this over the past couple of years with various (sometimes) competing viewpoints being expressed, but at this time a complete schema has not been created by the community. The primary reason for this, in my understanding from talking with various community members, is an overall desire to not put the cart before the horse - the development team should design and code an architecture for the community (the horse) to develop structured data (the cart), and when that architecture is available then the community will put together its schema.
- The software pieces for this are all coming together very quickly, as I updated the development page yesterday to reflect the next 4-6 weeks. "Other statements" will cover things like Author, Source, Date, and other relevant information that is generally found in the description template. As the final parts are released, I anticipate the community coming together to make the decisions for the questions you are asking. Keegan (WMF) (talk) 17:57, 12 June 2019 (UTC)
- @Jean-Fred and Keegan (WMF): SD is not a project by the community, although most people here support it. So your statement “the community should decide” is quite strange. So far, the community followed rather than led this project. I am quite sure that the community would have implemented it in a different way. The Author, Source, Date and License are the most important information for any file. Without any of these items, we don't know what is its copyright status, and we cannot keep a file here. The implement of these items affects the whole design. That's why their integration into SD should have been done first. "Depict" is related to the scope, and comes later. Regards, Yann (talk) 06:31, 13 June 2019 (UTC)
- SD is how the WMF developers coup with Wikimedia Commons's wishes to internacionalise categories and to fix other bariers in the project. Juandev (talk) 08:08, 13 June 2019 (UTC)
- While I welcome the idea, this is not how the project was presented to the community. Specially, it was expressly said that Captions won't replace Categories, which confused many people, including me. Regards, Yann (talk) 11:29, 13 June 2019 (UTC)
- I assume you mean either "Captions won't replace Descriptions" or "Depicts won't replace Categories"; captions clearly can't replace categories in any scenario.
- I certainly hope Depicts won't replace Categories. As far as I can see, Depicts is sort of a glorified Flickr tag. Over a year ago, I made a proposal as to how Depicts could supplement and assist the Categories system; the only person who engaged me raised purist hair-splitting epistemelogical concerns, so I walked away from it. If there is an interest in my fleshing out my proposal again, I'd be glad to. - Jmabel ! talk 16:00, 13 June 2019 (UTC)
- I don't think that Depicts is fundamentally different then Category. Both could be abused but imprecise or overbroad classification. Another issue is qualifier versus dedicated category, for example exterior/interior of building. --EugeneZelenko (talk) 19:17, 13 June 2019 (UTC)
- @Jmabel: Why do you see it as a glorified Flickr tag? As far as I know, Flickr tags are free-form (it’s not a constrained vocabulary), text-based (and not multilingual), and there’s no relationship between tags (no concept that eg a cat is also a mammal) − that’s just off the top of my head, but that’s already a very different animal than Wikidata-based depicts, which is not free-form, is multingual, and uses rich concepts (lots of properties are attached to whatever concept you use for depicts) and there’s a (admittedly work-in-progress) ontology defining relationships between items. Jean-Fred (talk) 22:10, 13 June 2019 (UTC)
- @Jean-Frédéric: Hence the "glorified". - Jmabel ! talk 01:19, 14 June 2019 (UTC)
- @Jmabel: Ah, sure :D. By that definition, I would then say that categories also a glorified Flickr tag − a somewhat even less glorified one ;-) Jean-Fred (talk) 08:30, 14 June 2019 (UTC)
- @Jean-Frédéric: Hence the "glorified". - Jmabel ! talk 01:19, 14 June 2019 (UTC)
- While I welcome the idea, this is not how the project was presented to the community. Specially, it was expressly said that Captions won't replace Categories, which confused many people, including me. Regards, Yann (talk) 11:29, 13 June 2019 (UTC)
- SD is how the WMF developers coup with Wikimedia Commons's wishes to internacionalise categories and to fix other bariers in the project. Juandev (talk) 08:08, 13 June 2019 (UTC)
- @Jean-Fred and Keegan (WMF): SD is not a project by the community, although most people here support it. So your statement “the community should decide” is quite strange. So far, the community followed rather than led this project. I am quite sure that the community would have implemented it in a different way. The Author, Source, Date and License are the most important information for any file. Without any of these items, we don't know what is its copyright status, and we cannot keep a file here. The implement of these items affects the whole design. That's why their integration into SD should have been done first. "Depict" is related to the scope, and comes later. Regards, Yann (talk) 06:31, 13 June 2019 (UTC)
- I'm a bit skeptical about the direction taken with depicts (P180). At Wikidata, one tries to avoid excessive use of qualifiers, but maybe Commons finds a way to avoid ending up with Flickr tag clouds. Jura1 (talk) 08:01, 12 June 2019 (UTC)
How to mass-populate depicts statements?
I've been hoping that the work over the last year to sync up Commons categories with Wikidata will have a big influence on how we now populate depicts statements - we can go through the category information to add the relevant wikidata items to the depicts statements. However, I think there are currently three big issues with this as we come up to the release of the feature here:
- Claims of copyright. Although everything on the Wikidata site is CC-0, including the category sitelinks, presumably someone's going to make the claim that categories added to images here aren't CC-0, which will hold things back (as they did the captions).
- Bot access to edit depicts statements. I haven't seen anything about this yet, presumably it will be possible using the same interface as is used on Wikidata, but when I was looking at this for the captions everything had to go through the API, which was painful (and I don't know how to do this for properties).
- Closing the loop - being able to then access the depicts statement in wikitext, so we can use it in templates such as {{Artwork}}, and auto-add the categories based on it.
There are also other issues (categories that don't have wikidata items, bot requests to go through, etc.), but I think the above three are the major ones. What does everyone think about this as things stand? Thanks. Mike Peel (talk) 19:48, 1 April 2019 (UTC)
- Correct, categories have been named and created under CC-BY-SA licensing.
- Mass populating depicts statements, then using them to manipulate image page content, is a ruddy nightmare scenario. We will automatically mass populate Commons with useless cruft like "photo in black and white" or "WWI photo" for photographs taken haphazardly in the WWI period that have nothing to do with the war. Volunteers will run around in circles and never make it meaningful. --Fæ (talk) 20:02, 1 April 2019 (UTC)
- @Fae: It wouldn't be the name of the category that you would be taking, just whether or not a particular image had been allocated to it. More difficult to argue that that is protected by copyright.
- @Mike Peel: A major problem is that the categories on images very often are not 'simple' categories with a matched Q-number, but are 'compound' categories, for which the Wikidata community has (so far) refused to allow wikidata items to be created. How to deal with this? Jheald (talk) 22:05, 1 April 2019 (UTC)
- Regarding (2), QuickStatements for Commons is in the works, I believe.
- Regarding (3): A problem again with auto-categorisation is when pictures should be put into direct categories corresponding to SDC/Wikidata statements, and when they should be placed in sub-categories corresponding to multiple SDC/Wikidata statements being present together. Difficult to automate this without a machine-interpretable statement of what a category represents. Jheald (talk) 22:10, 1 April 2019 (UTC)
- Not to mention: a given image may have legitimate categories that have little to do with what is depicted. E.g. it would be perfectly appropriate to have a picture of a house designed by person A and dwelt in by person B in the categories for both of those people, neither of whom is depicted. City A's exhibit at a fair in City B might be in the category for City A (as well as city B) even though it does not depict City A. - 01:41, 2 April 2019 (UTC) — Preceding unsigned comment added by Jmabel (talk • contribs)
- @Jheald: I was focusing on overall blockers, the absence of Wikidata entries for some items just reduces the number of depicts statements that could be added, until they have Wikidata items. We could also set up a template here to say "this category is a compound of QXX and QYY" if needed, but that means using qids manually, which isn't particularly nice. (2) I think QuickStatements would have the same issue as pybot with regards accessing Wikibase here to edit the information. (3) is a problem that can be dealt with in stages (like the infobox has gained auto-categorisation functions over the last year), but at the moment we can't do *anything* until we can access the structured data information in a template.
- @Jmabel: The way I'd handle that would be to create a category and linked wikidata item for the house, then do depicts=<house item>, and have the category for the house as a subcategory of the people. Similar with an exhibit. Thanks. Mike Peel (talk) 06:54, 2 April 2019 (UTC)
- Sure, but that is nothing a bot can do. - Jmabel ! talk 15:50, 2 April 2019 (UTC)
- Not to mention: a given image may have legitimate categories that have little to do with what is depicted. E.g. it would be perfectly appropriate to have a picture of a house designed by person A and dwelt in by person B in the categories for both of those people, neither of whom is depicted. City A's exhibit at a fair in City B might be in the category for City A (as well as city B) even though it does not depict City A. - 01:41, 2 April 2019 (UTC) — Preceding unsigned comment added by Jmabel (talk • contribs)
- @Keegan (WMF): Any comments? Thanks. Mike Peel (talk) 17:38, 16 April 2019 (UTC)
- @Mike Peel: Magnus Manske has ideas, I think. You're best talking to him about it. Keegan (WMF) (talk) 18:52, 16 April 2019 (UTC)
- @Keegan (WMF): I'm not sure how Magnus can help here, surely the onus is on the SDC team to provide some way to automate access to the data within MediaWiki/Lua and through some sort of machine-readable/writeable interface at least? Or will everything have to be done by hand/copy-paste? Thanks. Mike Peel (talk) 20:08, 16 April 2019 (UTC)
- Oh my apologies, I misunderstood what was being asked of me. There is/is going to be an API for this kind of access with documentation, absolutely, and as far as I know it will be structured in a way to be supportive of community (semi-)automation, depending on how the community wants to do things. As for specific implementation of migration, which is what I thought was being asked of me, that is where I know Magnus has some thoughts about how to get things moving once features are in place, as the community sees fit based on what's proposed. I will have much more developer-centric documentation and outreach going in the near future as things become available. Keegan (WMF) (talk) 20:19, 16 April 2019 (UTC)
- @Keegan (WMF): Thanks. I think it would be better to hold off on deploying depicts statements until after the API (and wikitext?) access has been sorted out and is live on the test wiki, so that the discussion about what the community wants to do with automated/semi-automated tools can happen first. Otherwise there's going to be a lot of wasted effort manually populating statements that could be automatically populated, or manual mis-population that has to be cleaned up later. Thanks. Mike Peel (talk) 20:27, 16 April 2019 (UTC)
- @Mike Peel: I don't agree with this. Of course it would be great to see this deployed on test-wiki, but I don't think it should delay manual experimentation here. Any manual effort will be thoughtful effort, and will likely help us resolve usage guidelines. Certainly I have no problem with "wasting" my manual efforts if they get reverted. Mass editing is more onerous to revert if we later change our minds about the model. Even if enabled on the live commons, I expect bot approvals to be cautious at first. --99of9 (talk) 00:29, 17 April 2019 (UTC)
- @99of9: if you really think "Any manual effort will be thoughtful effort", you should see what I'm right now cleaning up by way of English-language captions added by User:97.126.23.84. Probably well-intentioned, but not one of them accurate and on the mark. - Jmabel ! talk 00:36, 17 April 2019 (UTC)
- @Jmabel: How annoying. I hope they learn something from the experience! --99of9 (talk) 00:44, 17 April 2019 (UTC)
- That would almost make it worthwhile, but since it was a smartphone on an IP address that presumably did this all in one session, I'm guessing that, despite being admonished, they never got the message and will do equal damage from a different IP address. - Jmabel ! talk 00:51, 17 April 2019 (UTC)
- @Jmabel: How annoying. I hope they learn something from the experience! --99of9 (talk) 00:44, 17 April 2019 (UTC)
- @99of9: if you really think "Any manual effort will be thoughtful effort", you should see what I'm right now cleaning up by way of English-language captions added by User:97.126.23.84. Probably well-intentioned, but not one of them accurate and on the mark. - Jmabel ! talk 00:36, 17 April 2019 (UTC)
- @Mike Peel: I don't agree with this. Of course it would be great to see this deployed on test-wiki, but I don't think it should delay manual experimentation here. Any manual effort will be thoughtful effort, and will likely help us resolve usage guidelines. Certainly I have no problem with "wasting" my manual efforts if they get reverted. Mass editing is more onerous to revert if we later change our minds about the model. Even if enabled on the live commons, I expect bot approvals to be cautious at first. --99of9 (talk) 00:29, 17 April 2019 (UTC)
- @Keegan (WMF): Thanks. I think it would be better to hold off on deploying depicts statements until after the API (and wikitext?) access has been sorted out and is live on the test wiki, so that the discussion about what the community wants to do with automated/semi-automated tools can happen first. Otherwise there's going to be a lot of wasted effort manually populating statements that could be automatically populated, or manual mis-population that has to be cleaned up later. Thanks. Mike Peel (talk) 20:27, 16 April 2019 (UTC)
- Oh my apologies, I misunderstood what was being asked of me. There is/is going to be an API for this kind of access with documentation, absolutely, and as far as I know it will be structured in a way to be supportive of community (semi-)automation, depending on how the community wants to do things. As for specific implementation of migration, which is what I thought was being asked of me, that is where I know Magnus has some thoughts about how to get things moving once features are in place, as the community sees fit based on what's proposed. I will have much more developer-centric documentation and outreach going in the near future as things become available. Keegan (WMF) (talk) 20:19, 16 April 2019 (UTC)
- @Keegan (WMF): I'm not sure how Magnus can help here, surely the onus is on the SDC team to provide some way to automate access to the data within MediaWiki/Lua and through some sort of machine-readable/writeable interface at least? Or will everything have to be done by hand/copy-paste? Thanks. Mike Peel (talk) 20:08, 16 April 2019 (UTC)
- @Mike Peel: Magnus Manske has ideas, I think. You're best talking to him about it. Keegan (WMF) (talk) 18:52, 16 April 2019 (UTC)
- @Mike Peel: I would take it easy to start with and focus on quality and getting it right. Maybe some tools to do semi-automatic editing, but nothing too large.
- Lets focus at first on the featured pictures. We can go through all featured pictures and add the relevant depicts statements. Once we've done that, we can go to the good/valued image. This would give a relatively small pilot set of quite diverse structured data. Based on our experiences we start automating things.
- I hope my than we also have other types of statements so we can add things like when, where, by who and more technical metadata. Multichill (talk) 15:15, 17 April 2019 (UTC)
- Good idea. Yann (talk) 15:24, 17 April 2019 (UTC)
- That kind of manual testing can and should be done on the test wiki before the feature is turned on here, and it can be done alongside the testing of automated tools. I'd prefer to see a delay of the release until the automated access is available - but I've been asking that for the last 10 months with no answer... Thanks. Mike Peel (talk) 20:10, 17 April 2019 (UTC)
- Good idea. Yann (talk) 15:24, 17 April 2019 (UTC)
- Re Mike Peel: I think this is the great idea, because categories include a lot of kinda structured information to files. But I think it is too early. Lets wait for a few month that depicts settles done and other properties are introduced. Juandev (talk) 07:08, 24 April 2019 (UTC)
@Keegan (WMF): *twiddles thumbs*. There's not much that I can do to help here until these issues are sorted. Would it be helpful if I posted them on Phabricator? Thanks. Mike Peel (talk) 18:45, 10 May 2019 (UTC)
- It would be very very great if VFC (or a new tool) could allow us to put relevant statements to a group of selected files. Christian Ferrer (talk) 11:43, 14 June 2019 (UTC)
- For such visual editing, it would also be useful to have a tool that could be configured eg to highlight which files within a category or a page or a search or a list of files may already have a particular statement, or combination of statements. This is the other side of what is needed to be able to visually edit SDC statements, as well as useful in its own right. Jheald (talk) 12:36, 14 June 2019 (UTC)
- Yes, good point. Christian Ferrer (talk) 17:31, 14 June 2019 (UTC)
- To add a tag (wanted tag) to a selection of files, it would be great to have something in this kind :
- be able to see all tags (tag list) on a selection of files
- in a category (as with VFC)
- or uploaded by a specific user (as with VFC)
- be able to select from these files :
- all the files (in case that none file has already the wanted tag) + the possibility to unselect the files that don't need the wanted tag
- files that have the wanted tag among the tags from the tag list, and then to reverse the selection + the possibility to unselect the files that don't need the wanted tag
- manually some files (in case that none file has already the wanted tag, and in case that not all the files needs the wanted tag)
- to add the wanted tag of your choice to that selection
- be able to see all tags (tag list) on a selection of files
- Christian Ferrer (talk) 15:46, 15 June 2019 (UTC)
- To add a tag (wanted tag) to a selection of files, it would be great to have something in this kind :
- Yes, good point. Christian Ferrer (talk) 17:31, 14 June 2019 (UTC)
Qualifiers for depicts coming this week
The Structured Data on Commons team plans to release the first version of qualifiers for depicts statements this week. The team has been testing the feature with the community for a month, and are ready to turn it on for Commons on Thursday, 20 June, between 11:00-12:00 UTC. Adding qualifiers allows users to further develop depicts statements. For example, depicts: house cat can be extended into depicts: house cat[color:black]. You will be able to find qualifiers in the "Structured data" tab on the file page, or in the "Add data" tab in the UploadWizard. This version has a drop-down menu to select qualifiers; an update in the near future will replace the drop-down with an auto-suggest box.
I'll keep the community posted when qualifiers go live on Thursday, after the team makes sure everything is configured and working as expected. Keegan (WMF) (talk) 19:39, 17 June 2019 (UTC)
- @Keegan: Can you update on whether there has been any progress towards SPARQL querying of SDC information? With the addition of qualifiers, we really need it to keep track of what's going on across the data, and to identify patterns of erroneous or malevolent misuse. Jheald (talk) 20:39, 17 June 2019 (UTC)
- @Jheald: work on RDF and SPARQL is not being done by the SDC team, so I have little additional information beyond what's happening on Phabricator. T221917 - Create RDF dump of structured data on Commons is active as recently as last week, that's probably a good ticket to start exploring the work as it develops. Keegan (WMF) (talk) 21:26, 17 June 2019 (UTC)
Popups for the qualifiers
- Hello, I just made a few tests in Test-Commons,
- I see there is a predefined list of possible qualifiers. I think it may be useful to have a kind of help pop-up for each qualifiers with a short explanation on the function of the qualifiers, as well as an example for each. Or maybe a help page easily available.
- Has it been envisaged to put qualifiers for the qualifier given values, example I put:
- or is too complicated?
Regards, Christian Ferrer (talk) 21:18, 11 June 2019 (UTC)
- @Christian Ferrer: when other statements are released, the drop-down box will be replaced with an auto-suggest box from Wikidata. I believe this should contain the labels, which will help. Additionally, there are more designs in the works to be tested to provide some aspects of linking to Wikidata that will not be in the first release, but will be within the next few weeks after launch. Keegan (WMF) (talk) 17:33, 12 June 2019 (UTC)
- Is it just me, who does not see thumbnails on Testwiki? Juandev (talk) 06:08, 12 June 2019 (UTC)
- Thumbnails are not working. Keegan (WMF) (talk) 17:33, 12 June 2019 (UTC)
- I think will be good idea to have domain-specific lists of qualifiers. For example:
- age (adult, immature, larva, etc), sex, action (drinking, bathing, copulation, etc) for animals;
- part (flower, leaf, fruit, bark, etc), and state (living/dead) for plants;
- interior/exterior, spaces (for religious building) for building.
- EugeneZelenko (talk) 22:23, 12 June 2019 (UTC)
- @EugeneZelenko: some suggestions:
- interior/exterior -- use depicted part (P5961) = interior (Q2998430) / exterior (Q1385033)
- part (flower, leaf, fruit, bark, etc) -- use depicted part (P5961) as appropriate
- action -- use expression, gesture or body pose (P6022)
- age (in years) -- use age of subject at event (P3629)
- age (developmental stage) -- probably biological phase (P4774); this might also do for living/dead; alternatively, we might need a new property "phase of life";
- sex -- use sex or gender (P21)
- Hope this helps, Jheald (talk) 15:24, 20 June 2019 (UTC)
- I agree that identifying some common qualifiers and values for different particular sorts of objects would be a useful thing to start documenting, as suggestions for people. Jheald (talk) 15:30, 20 June 2019 (UTC)
- This query may be of use:
tinyurl.com/y6nu3q98. It identifies the most common qualifiers currently used on depicts (P180) statements on Wikidata, with the top 10 classes of items that each one is used on, and a sample item with a depicts statement on which the qualifier is used. Jheald (talk) 16:31, 20 June 2019 (UTC)
- This query may be of use:
- @EugeneZelenko: some suggestions:
digital representation of
How is this diff possible? I thought "depicts" was the only property supported at this time. Ayack (talk) 13:17, 14 June 2019 (UTC)
- Yeah, noticed that too :) User:Multichill is going through the API, so I guess there’s no restriction there − I imagine "depicts" is the only property supported in the front-end (actually, I’m positively pleased that the UI deals with this arguably unexpected situation in a very sane manner). Jean-Fred (talk) 13:29, 14 June 2019 (UTC)
- Ultimately I would prefer to see depicts (P180) not to be used when digital representation of (P6243) is present. But perhaps for the moment it makes sense to have both. Jheald (talk) 14:22, 14 June 2019 (UTC)
- Yes, correct, I use the API. I first checked if the interface wouldn't explode (that didn't happen).
- I deliberately choose to add both digital representation of (P6243) and depicts (P180) for these works. Let's take this not so random gallery:
- Ultimately I would prefer to see depicts (P180) not to be used when digital representation of (P6243) is present. But perhaps for the moment it makes sense to have both. Jheald (talk) 14:22, 14 June 2019 (UTC)



.jpg)


- Notice the sliding scale. I don't want to have people argue or edit war over to use depicts (P180) or digital representation of (P6243). So my reasoning:
- depicts (P180) is what you see in the image. In all cases I see the Mona Lisa painting
- digital representation of (P6243) is the structured data on Commons version of {{PD-art}}. The discussion to add {{PD-art}} or not didn't change, we can just model it as structured data now
- And when people are searching for a Mona Lisa image, shouldn't they get all of them? We should probably add a bit of search boost to the ones that also have digital representation of (P6243). For the inheritance of the depicts statements on linked paintings I opened phab:T223815. Multichill (talk) 15:48, 14 June 2019 (UTC)
- Notice the sliding scale. I don't want to have people argue or edit war over to use depicts (P180) or digital representation of (P6243). So my reasoning:
- @Multichill: You seem to be ahead of me here - I'm still waiting for my questions at #How to mass-populate depicts statements? to be answered. How are you accessing the data through the API - when I tried doing that for captions, it was very painful. And how did you get community approval for your bot task? (Again for captions, my proposal went down like a lead balloon.) Thanks. Mike Peel (talk) 19:20, 14 June 2019 (UTC)
- The API here is exactly the same as on Wikidata, the hard part is that the usual Pywikibot abstraction layers (site objects, page objects, etc.) are not in place yet so you have to bypass those for now and directly use the lower level functions to talk with the API. During the hackathon in Prague I wrote a couple of prototypes to do structured data editing.
- I wrote a bot to import captions from POTD templates (example edit). These are already written like captions and we have quite a big archive of these going back many years. Of course open source code. Some concerns were raised about copyright and I don't want to get dragged into that discussion right now, so I didn't follow through
- Statements like depicts (P180) on the other hand, don't raise copyright concerns. My approach is to add statements that don't introduce new errors. It might occasionally propagate a user error for example when someone misidentified something.
- With that in mind I first focussed on taxon items of species (sample query and sample edit). These images only get added to species becuase it's an image of the species. That seemed to work quite well. depicts species code. I picked this subject because it was easy to do. After that I switched to doamins I'm more active in.
- As you might know I'm adding links between painting items on Wikidata (almost 400.000 painting items these days) and images of artworks here on Commons Category:Artworks with Wikidata item contains 230.000 files). My first step here with structured data is to add statements on the files of paintings that are in use on Wikidata (sample query and example edit. This way the semi-structured data we've been collecting for a while is finally structured data, source.
- Back in the day I started Wiki Loves Monuments and the monuments database. We always asked people to identify what monument is in the file. For the Netherlands I also imported a large historic archive where people use(d) {{Possible Rijksmonument}} to identify the monument in the image. Currently we have 424,161 Rijksmonumenten with known IDs. I'm adding the depicts to the ones that have one {{Rijksmonument}} template (example edit). The code can probably be expanded to work on other countries, but I'm not sure if the data quality is high enough in every country. Potential is around 3 million files.
- Another good subset to work on is images of people. See this sample query, but if you look a bit close you'll notice weird things happening; In some rare cases we use a work (or a grave) to illustrate an item about a person. Perfectly valid on Wikidata, but we don't want to get that imported over here. So a bit more filtering like removing visual artists or using some computer vision to identify portraits needs to be able to fully automate an import here.
- We have over 350.000 files with depicts now and counting. In absolute numbers that is quite a nice increase (from 50.000), but in relative numbers it's just over 0,6% of all files. Multichill (talk) 15:14, 15 June 2019 (UTC)
- BTW, what I can see, that once the statement is there, you can edit it. Even on the beggining its gray and it looks like, you dont have rights for the block, finnally it worked. Juandev (talk) 15:31, 20 June 2019 (UTC)
Geographic location of depiction ?
Instead of adding a bunch of depicts (P180), I'd suggest creating a property with preferable a single value for this information.
Sample File:Valle_dell'Orfento.jpg has P180 values: Italy, Abbruzo. Unless a more precise value can be found, I'd just add "geographic location of depiction"=Abbruzo. This would likely be near GPS coordinates of the point of view.
Existing properties like "location", "country", etc. don't seem particularly suitable for this use on Commons.
If this has already been discussed somewhere, I'd be glad to read the discussion. Jura1 (talk) 13:34, 17 June 2019 (UTC)
- It is mentioned here Commons:Depicts#Items_expected_to_be_covered_by_other_statements I also proposed this on the talk page Commons_talk:Depicts#Add_no_location_policy. I think a broader discussion did not start because everyone wants to wait till the other statements are available. --GPSLeo (talk) 17:57, 17 June 2019 (UTC)
- I think we could propose/create it now and, unless the experiments with other properties break things, arrange for it to be activated. Jura1 (talk) 18:36, 17 June 2019 (UTC)
- I think we do not need new properties there are already location (P276) and located in the administrative territorial entity (P131) we just need to wait that these and all the other useful properties can be activated. --GPSLeo (talk) 19:05, 17 June 2019 (UTC)
- Based on my experience on Wikidata, I think using P276 ("location") and P131 ("located in subnational entity") might confuse things. Maybe narrative location (P840) or offers view on (P3173) could do, but both aren't particularly suitable for photographs.
For cases where this differs, one probably needs a property for "location of point of view" as well (with item values, similar to coordinates of the point of view (P1259) which requires coordinates). Jura1 (talk) 19:15, 17 June 2019 (UTC)- For now I would focus on what we have (depicts (P180)) and gently remind people that this is just the start and they should try to put everything in depicts. Multichill (talk) 14:53, 18 June 2019 (UTC)
- You mean, "people" except yourself? Jura1 (talk) 10:17, 20 June 2019 (UTC)
- I agree with guys, I would be patient and wait for the deployment of a specific statement. On the other hand you are slightly right. People may get lost in this slow deployment of statments and try to overpass their non existence. Juandev (talk) 15:35, 20 June 2019 (UTC)
- You mean, "people" except yourself? Jura1 (talk) 10:17, 20 June 2019 (UTC)
- For now I would focus on what we have (depicts (P180)) and gently remind people that this is just the start and they should try to put everything in depicts. Multichill (talk) 14:53, 18 June 2019 (UTC)
- Based on my experience on Wikidata, I think using P276 ("location") and P131 ("located in subnational entity") might confuse things. Maybe narrative location (P840) or offers view on (P3173) could do, but both aren't particularly suitable for photographs.
Half a million depicts statements
About 8 years ago I wrote User:Multichill/Next generation categories. The depicts statements are the first step here on Commons to implement that. To give the project a push in the right direction, I have been using a bot to import statements (see previous topic for the how part). We just passed a bit of a milestone, we currently have over half a million depicts (P180) statements. In absolute numbers this is a good start, in relative numbers this is about 1% of all (54M) files so we still have a long road ahead of us. I think bots are a good way to quickly increase coverage, but we shouldn't compromise on quality. Multichill (talk) 10:09, 18 June 2019 (UTC)
- Cool, but without you guys, we cannot go further - we cannot add so many information manualy, we would need some semi automated or fully automated way to mine them e.g. in categories. Juandev (talk) 15:37, 20 June 2019 (UTC)
Qualifiers for depicts is now available
Qualifiers in depicts statements is now available on file pages and in the UploadWizard. The option to add, edit, and remove qualifiers appears when editing structured data.
With this feature, depicts statements can be fully described. A statement that may have been previously limited, such as depicts: house cat, can now be stated as depicts: house cat [color:black]</black>.
There are a few known issues found in testing that are being worked on that were not significant enough to block release. Fixes should be in place soon.
- Attempting to add a qualifier and then cancelling leaves a "trace" behind
- On Firefox, quantity qualifier input boxes show a mini increment/decrement UI element
- Quantity qualifier value box is not visible on smartphones
The qualifiers chosen for this first release are qualifiers for depicts on Wikidata (as set by the property constraints) plus a couple of others being tested. Hard constraints prohibiting other qualifiers from being entered are not in place, as they are not in place on Wikidata. This first version of qualifiers does not show a warning if the qualifier is outside the constraints as it does on Wikidata, and a warning on Commons is something the team is willing to look into if the community would like.
Additionally, the dropdown menu suggestions when entering a qualifier are limited in the first “depicts only” release. In the near future, as we release support for all statements, qualifiers will use auto-suggest boxes and the list of returned suggestions will have much wider coverage and range.
Lastly, this first version of the feature does not display qualifier text as links to their associated Wikidata properties, but links will be present in a later release.
The development team looks forward to seeing the use of qualifiers in statements, and welcomes any comments or questions about the feature here on this talk page. Keegan (WMF) (talk) 14:07, 20 June 2019 (UTC)
- When qualifiers will be arbitrary? Current set is very limited and targeted mostly on photos of people. See my comment on #Popups for the qualifiers about qulifiers sets for other domains. --EugeneZelenko (talk) 14:17, 20 June 2019 (UTC)
- Perhaps worth noting that, as used on Wikidata at least, the "allowed qualifiers constraint" for properties has been seen as pretty advisory, and tends to have evolved without much regard for completeness. (It's often wildly incomplete, with regard to generic qualifiers that may be very standard, but no so often used). As a result, if a qualifier makes even a bit of sense for a property, it's generally been pretty non-controversial for an editor to just edit the list and add it.
- Given the significance of depicts (P180) for Commons, we should probably have a section on the Commons:Depicts page listing the qualifiers and how to use them / what they mean -- ie that applies to part, aspect, or form (P518) is to indicate a part of the image eg "top left", while depicted part (P5961) should be used to indicate the part of the depicted object, eg "head" or "interior", which shown with features (P1354), wears (P3828), expression, gesture or body pose (P6022), etc, can be used to further describe. Jheald (talk) 14:33, 20 June 2019 (UTC)
- @EugeneZelenko and Jheald: restraints for qualifiers will be removed in version two, with the drop-down being replaced by an auto-suggest that can be ignored. You can try out version two on Beta Commons, keeping in mind you're seeing the early version two there. Still some more work to be done before release. Keegan (WMF) (talk) 16:39, 20 June 2019 (UTC)
Qualifiers
Hey, I am still not understanding some qualifiers (e.g. shown with features, applies to part). Could you link me somewhere, where they are explained? I still thing, that the translation is missleading, where can I fix their translation? Lasty I thought the limited amount of qualifiers is just for testwiki. So when more qualifiers will arive? Juandev (talk) 15:27, 20 June 2019 (UTC)
- @Juandev: the documentation for qualifiers here on Commons needs expanding as the community decides on its rules here, but you can find more information about qualifiers in general at Help:Qualifiers on Wikidata. The Structured Data development team is planning to provide links for more information in the software with its next release, as well as the ability to add more qualifiers then. The software is almost ready for testing, so it should be out in two to four weeks. I'll keep this page updated with testing information.
- As for translations, I'll get back to you with the link. Keegan (WMF) (talk) 22:04, 20 June 2019 (UTC)
New items order
I would say it would be more confortable to add new items on the top, not on the bottom. Image the situation, you have many items for file, every time you want to edit its qualifiers, you should scrool down and than up to add a new item. This is unnecessary time consuming. Juandev (talk) 15:27, 20 June 2019 (UTC)
Depicts for background
If background (kind of technical term) is an important part of the file, can I set it, like I did in the case of this image? Juandev (talk) 15:27, 20 June 2019 (UTC)
Linking and describing to qualifiers
When linking to Wikidata items in the qualifiers, I would like to be able to click on and link to that concept just like we are doing right now with the object of depict. Moreover, as a user, I need the definitions of the qualifier properties -- which should also be linking to the property on wikidata, or when I hover, bring in the description field. Sadads (talk) 17:09, 20 June 2019 (UTC)
- @Sadads: linking should come within a few weeks when we release other statements and version two of qualifiers. Keegan (WMF) (talk) 20:01, 20 June 2019 (UTC)
- @Keegan (WMF): Okay -- just wanted to make sure that was on the radar: it didn't look like it was in V2 on Beta Commons. Sadads (talk) 21:10, 20 June 2019 (UTC)
- Right, it's not on beta yet, still in design I believe. Keegan (WMF) (talk) 21:42, 20 June 2019 (UTC)
- @Keegan (WMF): Okay -- just wanted to make sure that was on the radar: it didn't look like it was in V2 on Beta Commons. Sadads (talk) 21:10, 20 June 2019 (UTC)
Edit summary missing change to depicts
Could we add something to the edit summary that describes what happens? Like "Modified qualifier for [X STATEMENT]?" Sadads (talk) 18:16, 20 June 2019 (UTC)
- Like this? Yes, that would be helpful. Multichill (talk) 19:17, 20 June 2019 (UTC)
- This is something that the team would like to do, but there's some technical overhead challenges in pulling the pieces together to generate a summary that's more useful than what we have now. I've added the parent task to this thread, but you can also find the same feature request that Jean-Fred filed, and Ramsey's followup explanation there. Keegan (WMF) (talk) 20:51, 20 June 2019 (UTC)
- @Keegan (WMF): -- I am not asking for the labels for the items -- just the fact that you are editing qualifiers -- right now it looks like, in the edit summary, like any other change to a statement. Sadads (talk) 21:10, 20 June 2019 (UTC)
- Sure, my response is more immediate to the possible presentation shown by Multichill's bot. The team is aware that the current edit summary is less-than-desirable, I'll get back to the community here when I know more about what may or may not change there. Keegan (WMF) (talk) 22:05, 20 June 2019 (UTC)
- @Keegan (WMF): -- I am not asking for the labels for the items -- just the fact that you are editing qualifiers -- right now it looks like, in the edit summary, like any other change to a statement. Sadads (talk) 21:10, 20 June 2019 (UTC)
- This is something that the team would like to do, but there's some technical overhead challenges in pulling the pieces together to generate a summary that's more useful than what we have now. I've added the parent task to this thread, but you can also find the same feature request that Jean-Fred filed, and Ramsey's followup explanation there. Keegan (WMF) (talk) 20:51, 20 June 2019 (UTC)
Inconsistent mediainfo API output

Another thing hindering development on top of the API first noticed by Magnus: Inconsistent API output tracked in Phab:T149410. Lucas also pointed out Phab:T222159. If I would be developing this, I would do everything exactly the same as Wikibase on Wikidata and only do things differently when I have a damn good reason. Why isn't that practice applied here or what is the damn good reason for these changes? @Keegan (WMF): can you ask around? I'm afraid we'll uncover more inconsistencies.. Multichill (talk) 09:20, 21 June 2019 (UTC)
- @Multichill: from what I can tell, claims have always been called statements in MediaInfo since WMDE initially wrote the extension, I'm certainly not aware of any recent changes by the SDC team that would relate to that. Perhaps WMDE had a reason? I'm not sure. Anyway, consistency is good, the team is going to have a look at the ticket. Keegan (WMF) (talk) 15:35, 21 June 2019 (UTC)
- RIsler (WMF) is checking to make sure about the background and affirm any other inconsistencies or changes. Keegan (WMF) (talk) 15:40, 21 June 2019 (UTC)
- Picture on the right might be useful for the relation between claim and statement. Multichill (talk) 15:45, 21 June 2019 (UTC)
- RIsler (WMF) is checking to make sure about the background and affirm any other inconsistencies or changes. Keegan (WMF) (talk) 15:40, 21 June 2019 (UTC)
LUA access?
@Keegan (WMF): when can we access structured data with LUA? Or is that already possible and I missed it? Multichill (talk) 09:33, 17 June 2019 (UTC)
- @Multichill: my understanding from the last discussion held here, and confirmed by RIsler (WMF), is that there are no current plans from the SDC team to work on Lua support; I do not know what WMDE's plans might be in this regard. When SDC is feature complete, the team is aiming to provide identical functionality to what you'd achieve with Lua through either SDC code itself, or support for javascript tooling to do the work. You're welcome to pitch your particular use case for Lua here, the team will keep it in mind when planning out future work. Keegan (WMF) (talk) 17:48, 17 June 2019 (UTC)
- Hm, without Lua access a good part of SDC seems to be in vain. Without it, currently unstructured data from the wikitext slot can't be replaced by the structured data. Then we manage the data twice in parallel? With Lua access current license tags and much of stuff currently in templates like {{Information}} can be moved to SDC and still be displayed in a nice way. Javascript client side code doesn't seem like a good option for that. Best, --Marsupium (talk) 19:11, 17 June 2019 (UTC)
- Thank you for sharing that. Building support for use cases is the best way to get Lua moved up in priority lists. I have no idea how successful the request(s) will be, but writing them down is a start. Keegan (WMF) (talk)
- Hm, without Lua access a good part of SDC seems to be in vain. Without it, currently unstructured data from the wikitext slot can't be replaced by the structured data. Then we manage the data twice in parallel? With Lua access current license tags and much of stuff currently in templates like {{Information}} can be moved to SDC and still be displayed in a nice way. Javascript client side code doesn't seem like a good option for that. Best, --Marsupium (talk) 19:11, 17 June 2019 (UTC)
- @Keegan: Exactly what Marsupium says. Part of the point of SDC is to be able to migrate data from templates to SDC, with the information still visible as before in the templates on the file page, but drawn from data stored in the SDC rather than wikitext. Without Lua, how is it proposed to be possible to achieve this?
- Simple parser functions are not going to be sufficient. There is an idea, I think, to provide some mechanism for editable fields in templates, functionality currenly provided on many Wikipedia templates via Lua, to be via some new system of hooks (can you confirm this?). But the experience from Wikipedia is that sometimes it is necessary for fields in templates to present information combined from multiple wikidata properties in quite complicated ways. On Wikipedias that has required Lua. Without Lua, what is the envisioned routemap to achieve this?
- It's been hard enough migrating templates to Lua, which was specifically chosen for the job. The idea of templates now going to need to be some bespoke Frankenstein combination of wikitext and Lua and javascript is just too much of a nightmare to imagine. As well as likely going to be an uncached performance nightmare, too. And likely a real brute for scraper-based tools to decipher, as well. Jheald (talk) 20:28, 17 June 2019 (UTC)
- To add to what I wrote above, it's useful for SDC data to be accessible through similar mechanisms that Wikidata is currently accessible, so that methods coded in existing modules can be worked from and can be adapted to serve the new data. Also, because the mechanisms will need to draw on a mix of SDC and wikidata. A concrete example of the sort of facilities currently being offered through Lua modules is the ability to distinguish when a value in a template is being filled directly from Wikidata; when it is being filled from a local value that matches Wikidata; when from a local value because there is no data on Wikidata; and when from a local value that is overriding Wikidata -- with the page categorised accordingly (sometimes further split between checked differences and unchecked differences). The categorisation, which is then available from SQL, as well as for straightforward browsing, has proved very valuable for tracking and supporting the migration of information to Wikidata. This is just one of the ways Lua has been used in templates in conjunction with data. Pinging @Jarekt and RexxS: who may wish to highlight some further particularly valuable ones. Jheald (talk) 11:17, 18 June 2019 (UTC)
- Without LUA the data is inaccessible and we can't migrate away from the semi-structured data. LUA has been key in the migration of redundant data in templates like {{Creator}} & {{Institution}}. Without any LUA support planned, importing data is useless and I might as well stop.
- Not sure how difficult this is form a technical perspective. Basically all the LUA is already there, it just needs to understand how to fetch data from mediainfo (M<something>). The Wikibase guru's at Wikimedia Germany can probably make an educated guess how much effort is needed for this. Multichill (talk) 15:06, 18 June 2019 (UTC)
- Thanks for the additional comments, @Multichill and Jheald: . I'm going to ping @Jarekt: here as well since he started the last conversation around Lua. The engineering teams are going to investigate, I'll get back to you with the results. I do not have a timeframe at the moment. As Multichill mentions it'll likely take some coordination with WMDE, so it might take a bit of time. Keegan (WMF) (talk) 15:55, 18 June 2019 (UTC)
- A month ago, I created phabricator:T223792 requesting access to structured data with LUA. I was assuming that since Lua already has capability of interacting with Wikibase software used by Wikidata and SDC, than it should be a simple task to reconfigure it to allow access to SDC. --Jarekt (talk) 12:50, 19 June 2019 (UTC)
- Thanks for the additional comments, @Multichill and Jheald: . I'm going to ping @Jarekt: here as well since he started the last conversation around Lua. The engineering teams are going to investigate, I'll get back to you with the results. I do not have a timeframe at the moment. As Multichill mentions it'll likely take some coordination with WMDE, so it might take a bit of time. Keegan (WMF) (talk) 15:55, 18 June 2019 (UTC)
- To add to what I wrote above, it's useful for SDC data to be accessible through similar mechanisms that Wikidata is currently accessible, so that methods coded in existing modules can be worked from and can be adapted to serve the new data. Also, because the mechanisms will need to draw on a mix of SDC and wikidata. A concrete example of the sort of facilities currently being offered through Lua modules is the ability to distinguish when a value in a template is being filled directly from Wikidata; when it is being filled from a local value that matches Wikidata; when from a local value because there is no data on Wikidata; and when from a local value that is overriding Wikidata -- with the page categorised accordingly (sometimes further split between checked differences and unchecked differences). The categorisation, which is then available from SQL, as well as for straightforward browsing, has proved very valuable for tracking and supporting the migration of information to Wikidata. This is just one of the ways Lua has been used in templates in conjunction with data. Pinging @Jarekt and RexxS: who may wish to highlight some further particularly valuable ones. Jheald (talk) 11:17, 18 June 2019 (UTC)
- I completely agree with Multichill and others that this is essential. Not having it is already seriously holding back the integration of P180 etc. in templates, and it's only going to get worse as time goes by. As Lua support is also pending for Lexemes, perhaps there could be common work here with @Lea Lacroix (WMDE) and Lydia Pintscher (WMDE): ? (see discussion at phab:T212843.) Thanks. Mike Peel (talk) 18:50, 18 June 2019 (UTC)
- As a long-term goal, I want to be able to see Wikipedia use dynamic list articles – that is, list articles which are generated on-the-fly (with short term caching, of course), so that a reader can ask for a list of the current leaders of EU countries, for example, and see an article that is up-to-date, with relevant images and associated information which has been created by pulling in data from WD and SDC seamlessly. Even for more static collections (let's say, major bridges in Hungary built in the 19th century), the appeal of being able to have the best images currently available is enough for me to enthuse about having the technology to interface via Scribunto with SDC. If you need more user-cases, I'm happy to come up with more ideas. And once the API is exposed to Scribunto, I'm happy to write custom Scribunto modules to allow template editors on Wikipedias to make use of that. We need to be imaginative in looking forward: make the technology available and we'll find lots of ways to use it. --RexxS (talk) 22:23, 18 June 2019 (UTC)
- Yes, like this fr:Liste des peintures de paysages par Paul Cézanne? Regards, Yann (talk) 05:57, 19 June 2019 (UTC)
- As a long-term goal, I want to be able to see Wikipedia use dynamic list articles – that is, list articles which are generated on-the-fly (with short term caching, of course), so that a reader can ask for a list of the current leaders of EU countries, for example, and see an article that is up-to-date, with relevant images and associated information which has been created by pulling in data from WD and SDC seamlessly. Even for more static collections (let's say, major bridges in Hungary built in the 19th century), the appeal of being able to have the best images currently available is enough for me to enthuse about having the technology to interface via Scribunto with SDC. If you need more user-cases, I'm happy to come up with more ideas. And once the API is exposed to Scribunto, I'm happy to write custom Scribunto modules to allow template editors on Wikipedias to make use of that. We need to be imaginative in looking forward: make the technology available and we'll find lots of ways to use it. --RexxS (talk) 22:23, 18 June 2019 (UTC)
I imagine that in the future we will start using SDC for storing information currently stored in {{Information}} templates. Majority of files on Commons are photographs taken and uploaded by Commons users, if we could use SDC to store information on author (author (P50)) might not work, see phabricator:T127929), date (inception (P571)), and source than for majority of images on Commons we could migrate most of the content of {{Information}} templates to SDC. However ideally the interface would not change for users of Commons so we could rewrite {{Information}} template in LUA (see draft at Module:Information). Rewritten {{Information}} template would take either local values, provided as arguments of the template or properties from SDC. That would be analogous to the way currently {{Artwork}} or {{Book}} templates merge local arguments with the info pulled from Wikidata. Ideally, if we do it right, the look of the template would not change much as we switch from one form of data storage to the other. Also in the future we might use projects like m:Wikidata Bridge to edit SDC properties from the {{Information}} template. If we want to take this route we would need at the minimum to be able to access SDC from LUA. --Jarekt (talk) 13:29, 19 June 2019 (UTC)
Update
I'm copying over an update I put in the tracked Phabricator task:
Sorry about the delay in the update, but I'm currently meeting with the SDC team in person and we're discussing this task in real-time.
The SDC development team is going to have to look into what it takes to get this done - or if not this, some other technical solution that would allow the dynamic updating of templates from structured data. The team currently is unable to do this on their own, so it will require some external partnership to make this happen and WMDE does not have the resources to assist with this task.
So, this is going to take some time to complete. I have no idea how long for a timeframe, the team will have to talk to other teams and figure out how to make this happen. But they do know absolutely how important this is to the community's plans for the project, and the work is definitely something to do once resourcing gets worked out. Keegan (WMF) (talk) 19:06, 26 June 2019 (UTC)
Temporary 9 month issue
@Keegan (WMF): In September 2018 it was noted that we would be temporarily unable to read old revisions as source text [20]. I recently ran into this problem when trying to undo old revisions that were made in error, without disturbing newer revisions [21]. Has anything been done in the past 9 months to restore readability? When will this be solved? Sincerely, Taketa (talk) 10:33, 2 July 2019 (UTC)
- @RIsler (WMF): You said "The ultimate point is that there *will* be a way to view the Wikitext of a past revision, we just haven't settled on the best way to do that yet." Have you settled on the best way to do this yet? Sincerely, Taketa (talk) 10:36, 2 July 2019 (UTC)
- I'll see where we are here, but at the end of the post that "The team may try to look into other ways of serving the entirety of old wikitext page revisions, but it will not be possible in the near future," with RIsler commenting later in the thread that the software team responsible for writing Multi-Content Revisions may look at something in the future, but that the change we put in place would stay through at least v1 of Structured Data. We are still releasing v1 of Structured Data. The word "temporary" is not found in my initial post for good reason - this isn't temporary.
- You can still access the old revision wikitext, but it requires two extra clicks instead of being shown in the diff view. Click on the old revision , click "edit source" and there you have access to copy the old revision. Keegan (WMF) (talk) 15:47, 2 July 2019 (UTC)
- I understand the software is permanent, but as I understood it the problem would be temporary, since you were looking for a way to view the old versions. In this specific case the problem was that both myself and two Commons admins (who I checked with on IRC to see if I was missing something) could not view the full old version text. Currently on the same page everything works fine. I cannot replicate the error anymore, so my point seems moot. It is the first time this happens for me. I will come back to it if it happens again. All the best, Taketa (talk) 12:24, 3 July 2019 (UTC)
- Okay, sounds good. Thank you. Keegan (WMF) (talk) 15:38, 3 July 2019 (UTC)
- I understand the software is permanent, but as I understood it the problem would be temporary, since you were looking for a way to view the old versions. In this specific case the problem was that both myself and two Commons admins (who I checked with on IRC to see if I was missing something) could not view the full old version text. Currently on the same page everything works fine. I cannot replicate the error anymore, so my point seems moot. It is the first time this happens for me. I will come back to it if it happens again. All the best, Taketa (talk) 12:24, 3 July 2019 (UTC)
Link Wikidata items directly
Instead of linking <https://www.wikidata.org/wiki/Special:EntityPage/Q5> could you link <https://www.wikidata.org/wiki/Q5> directly? Jura1 (talk) 15:19, 8 July 2019 (UTC)
- Might I ask what the advantage of this would be, or what the difference is? I genuinely do not know, and I'm curious. As far as actually doing it, I think the team is still working on when and how exactly to link to Wikidata, so the designs are still in draft and it might be possible if there's a compelling reason. Keegan (WMF) (talk) 19:48, 8 July 2019 (UTC)
- When creating items there, adding statements here and going back there, I was wondering why I should be needing to load a redirect merely because I got back there from Commons? Oddly, even if I had created an item myself, it appears as an unvisted link in my browser? Did you notice that too? --Jura1 (talk) 19:52, 8 July 2019 (UTC)
- Okay, good point. I wasn't sure if the special page was providing some sort of specific function for the redirect (like Special:MyLanguage does). Thanks, I'll inquire. Keegan (WMF) (talk) 20:32, 8 July 2019 (UTC)
Invisible
Is there a way to make it visible? Looking at categories or even file description pages, there is no way to know if a file has one or several depicts-statements or not. Jura1 (talk) 14:29, 6 July 2019 (UTC)
- +1 I don't remember when and where but I already suggested that the words "Structured data" in the file page be in blue when there is at least one depict statement. Another idea could be a little number 3, near the words, that says the number of depict statements. Christian Ferrer (talk) 15:20, 6 July 2019 (UTC)
- (See also previous related discussion at Commons talk:Structured data/Archive 2019#A distinctive appearance for the files that have depict statement(s) (or other structured datas...) Jean-Fred (talk) 16:45, 6 July 2019 (UTC))
- Following the previous discussion, it seems that no steps have been taken to implement this in one or the other way.
- For file description pages, could this be done by css?
- For categories, I started using query server. Jura1 (talk) 16:48, 9 July 2019 (UTC)
- As I'm understanding, the question is whether there can be a way to identify from the file page if the structured data tab has any data in it. Is this correct? Keegan (WMF) (talk) 15:47, 10 July 2019 (UTC)
- For categories, that would be sufficient. Maybe with a gadget as for uses and descriptions?
- For file description pages, the data should also be visible: I don't see the point of opening the description page, clicking on the tab to see what's there, possibly clicking again to re-read the description as it disappeared, then clicking once more to add something.
- Obviously, the whole thing might become less an issue if one uses some tool to search for images and add statements. Jura1 (talk) 16:19, 10 July 2019 (UTC)
- As I'm understanding, the question is whether there can be a way to identify from the file page if the structured data tab has any data in it. Is this correct? Keegan (WMF) (talk) 15:47, 10 July 2019 (UTC)
Property proposals
Made a new page for the Structured data for Commons related property proposals, see d:Wikidata:Property proposal/Commons. Makes it easier to put it on your watchlist and keep an eye on what is being proposed. Multichill (talk) 16:53, 19 July 2019 (UTC)
Multiple depicts
What do you do when there are multiple Wikidata elements with the same name? e.g. Landsborough railway station. Sometimes you get some additional text that disambiguates them (as happened with Landsborough), but sometimes you don't. Kerry Raymond (talk) 04:11, 29 May 2019 (UTC)
- @Kerry Raymond: I think the most sensible approach is probably to open a new tab and visit Wikidata in that, using its search facility to find the right item, then paste the 'Q' number into the editing box on Commons. While you're on Wikidata, you could also add a suitable description to the item so that the next person has a better chance of finding it. --bjh21 (talk) 12:37, 29 May 2019 (UTC)
- @Kerry Raymond: When doing the equivalent operation on Wikidata, you can middle-click to open a new tab with the items − this is not possible here, and filed as phab:T224604.
- Your best workaround is probably 'choosing' a value, as it does not save the claim right away. That way, you get a hyperlink to the Q-item, so you can investigate which item you have just selected before saving it. Jean-Fred (talk) 16:12, 29 May 2019 (UTC)
- And for people who don't want to use Wikidata? This is why the information needs to be in the File, so it can be changed by the usual edit processes including AWB. Kerry Raymond (talk) 20:57, 29 May 2019 (UTC)
- @Kerry Raymond: If you don't want to use Wikidata, you will find it hard to populate depicts (P180). Every time you use the "search" box under depicts (P180), you're searching Wikidata, so to avoid it you need to get your 'Q' numbers from somewhere else, and even then they'll be looked up in Wikidata when you enter them. --bjh21 (talk) 10:12, 30 May 2019 (UTC)
- You misunderstand me. "Open a new tab and visit Wikidata, using ... Qnumber ...." is not an instruction you can give to an average Commons user who knows nothing about Wikidata. If you seriously want people uploading photos to engage with "depicts" (and I think people can understand what "depicts" means in a general way without having any knowledge of p180), then the Upload Wizard needs provide a way to do it that doesn't need them to know about Qnumbers, Pnumber nor require them to access Wikidata. I train new users. Uploading photos is a massively hard topic to teach to new people, so expecting them to also know about Wikidata to do it is NOT the way to attract new contributors. Remember depicts is in the standard "Upload Wizard". If we are serious about it being a "Wizard", then it do something clever. For example, make guesses from the Commons categories as suggestions, or ask them for a Wikipedia article it relates to (and then map whatever they choose to Wikidata under the hood). Use other systems of identification to make it easier for them to indicate what is being depicted, with Wikidata being just one choice not the only choice. Kerry Raymond (talk) 13:40, 30 May 2019 (UTC)
- I understand your concerns and agree to them up to a certain degree ; but I’m not sure I follow « ask them for a Wikipedia article it relates to (and then map whatever they choose to Wikidata under the hood). » − in some way, since Wikidata is more than the unions of all Wikipedias, then this is exactly what is happening.
- Also not sure I follow that new users would be able to add categories, but not to add depicts − I can certainly agree that experienced Commons users are more familiar with categories than Wikidata (that’s kind of still my case ^_^); but I would imagine a new user to instinctively fare better with depicts and its multilingual and fuzzy search than with the monolingual, somewhat arbitrary named Commons categories.
- Jean-Fred (talk) 15:07, 6 June 2019 (UTC)
- You misunderstand me. "Open a new tab and visit Wikidata, using ... Qnumber ...." is not an instruction you can give to an average Commons user who knows nothing about Wikidata. If you seriously want people uploading photos to engage with "depicts" (and I think people can understand what "depicts" means in a general way without having any knowledge of p180), then the Upload Wizard needs provide a way to do it that doesn't need them to know about Qnumbers, Pnumber nor require them to access Wikidata. I train new users. Uploading photos is a massively hard topic to teach to new people, so expecting them to also know about Wikidata to do it is NOT the way to attract new contributors. Remember depicts is in the standard "Upload Wizard". If we are serious about it being a "Wizard", then it do something clever. For example, make guesses from the Commons categories as suggestions, or ask them for a Wikipedia article it relates to (and then map whatever they choose to Wikidata under the hood). Use other systems of identification to make it easier for them to indicate what is being depicted, with Wikidata being just one choice not the only choice. Kerry Raymond (talk) 13:40, 30 May 2019 (UTC)
- @Kerry Raymond: If you don't want to use Wikidata, you will find it hard to populate depicts (P180). Every time you use the "search" box under depicts (P180), you're searching Wikidata, so to avoid it you need to get your 'Q' numbers from somewhere else, and even then they'll be looked up in Wikidata when you enter them. --bjh21 (talk) 10:12, 30 May 2019 (UTC)
- We should really display a thumbnail of the P18 image of each item besides each search result. Syced (talk) 15:09, 25 July 2019 (UTC)
Searching media by depiction: Fastest way to get a first page of results to display?
Dear all,
In my app, I want to allow users to search media by depiction. When the user types "Java", the app shows various matching items such as the Java island, the Java coffee, the Java programming language (this part is implemented already).
Once I have a QID, what is the fastest way to get a first page of results to display?
I guess I could use SPARQL, but my experience with SPARQL is that it times out when there are too many items, which is not acceptable (after all, 90% of the users will be searching for pictures of cats, which make a sizable proportion of Commons).
Is there a different API, or a special way to write my SPARQL request, to achieve fast page-by-page fetching?
Thanks a lot! Syced (talk) 15:15, 25 July 2019 (UTC)
- @Syced: the fastest way would probably be searching
haswbstatement:P180=xxxxusing the API (example). This isn't exactly my area of expertise, so if you have any more questions let me know and I'll do my best to find out the answers. Keegan (WMF) (talk) 16:44, 25 July 2019 (UTC)- Thanks a lot, it seems to work great! I could not find a Wikidata item that has thousands of depictions already, but https://commons.wikimedia.org/w/api.php?action=query&list=search&srsearch=haswbstatement:P180=Q34651&srnamespace=6 with 25 depictions has its first page of 10 files coming very fast :-) Syced (talk) 01:19, 26 July 2019 (UTC)
Testing support for all statements
Testing is now available for all statements in structured data. Currently, Commons only supports depicts statements. Upcoming support for other types of statements allows concepts related to the file to be more fully mapped out. For example, File:Ahotel.jpg on test-commons can support statements such as depicts:hotel, location:Sant Cugat del Vallès, license:Creative Commons Attribution 4.0 International, all with corresponding links to Wikidata.
Visit Test-Commons to try adding, editing, and removing additional statements to files. This initial design is very simple, more work will be done on it. After you've tested it out, let us know what you think. The team would like to hear about bugs, confusing elements, or anything else that might come to mind relating to statements when trying things out.
Here are the known issues we are currently working on fixing:
- Considering adding a horizontal divider between statement panels on UploadWizard
- Fallback language superscripts problem
- Qualifier bug
- Considering ways to unify the statement editing experience on Upload Wizard and the file page. If you have any suggestions, please let us know.
If you're interested in what kinds of properties from Wikidata you might want to use to form statements, have a look over the SDC Properties table. There are likely properties that still need created. If you're interested in the community process for creating properties on Wikidata, visit the property proposal page for Commons to get started. Keegan (WMF) (talk) 22:09, 23 July 2019 (UTC)
- Hello Keegan (WMF), I tried to add coordinate location but the property is not available in the search field. Are you sure "all statements" are now available? It seems that only items are available. Thanks. Ayack (talk) 08:49, 24 July 2019 (UTC)
- @Ayack: geocoordinates are not yet supported, we aren't to different data types like that yet. Properties with a text data type should all be working. So yes, not "all" are available, but almost all :) Keegan (WMF) (talk) 16:09, 24 July 2019 (UTC)
- Following the question on my talk page: it went fine so far. It seems to me that string and quantity datatype properties only work as qualifier, not as direct properties. I don't know if this is intended or not. Jura1 (talk) 17:39, 26 July 2019 (UTC)
- @Ayack: geocoordinates are not yet supported, we aren't to different data types like that yet. Properties with a text data type should all be working. So yes, not "all" are available, but almost all :) Keegan (WMF) (talk) 16:09, 24 July 2019 (UTC)
Two remarks about the UI:
- IMO search field inside statement should only be visible when clicking on Edit. It takes up too much place on the screen.
- When clicking on Add statement, focus should be put on the Search field. Currently you have to click again in the field before being able to type.
Apart for that, it's great (but I haven't tested import yet). Ayack (talk) 08:51, 25 July 2019 (UTC)
Remarks from a short test:
- Generally works well
- Missing a cancel button:
- Click on "+ Add statement"
- Add a statement
- Try to cancel ...
- How to add the photographer (copyright owner) of the image? Creating an item for every user and/or photographer seems impossible to me. Free flow text?
- My tests of today: [22] and [23]. I am open for suggestions to improve my depict statemens. Everyone is invited to do it.
- Tools for copy&paste of statements between files are needed.
Raymond 18:04, 26 July 2019 (UTC)
Live on Commons
Thanks to all who tested and those who left feedback here. Other statement support is now live on Commons. There is still support for other datatypes to come, I'll keep the community posted as those are developed.
IRC office hour on Thursday, 18 July
The development team is going to hold an IRC office hour on Thursday, 18 July, from 17:00-18:00 UTC. Bring whatever topic you'd like to discuss; current items include the testing of "other statements" (more on that coming this week), properties that Commons may still need created on Wikidata, how the Foundation may provide Lua support, among others. I'll post reminders as we get closer to the date. Keegan (WMF) (talk) 17:17, 8 July 2019 (UTC)
- There's been delays in getting some bugs fixed and designs worked out, so testing for other statements will not be available this week. We're still holding the IRC office hour next week, I'll send out rounds of notices about it on Monday. Keegan (WMF) (talk) 17:08, 12 July 2019 (UTC)
Reminder: this week
The IRC office hours are taking place this week, Thursday, 18 July. I'll post another reminder before the event. Keegan (WMF) (talk) 22:49, 15 July 2019 (UTC)
- Tomorrow is the day (relatively speaking to time zones). I'll post a last reminder about an hour or so before we start. Keegan (WMF) (talk) 20:40, 17 July 2019 (UTC)
- The office hour is taking place in about two hours. Keegan (WMF) (talk) 14:59, 18 July 2019 (UTC)
- Thanks to those who attended and lurked, the log is on meta. Keegan (WMF) (talk) 15:52, 22 July 2019 (UTC)
- The office hour is taking place in about two hours. Keegan (WMF) (talk) 14:59, 18 July 2019 (UTC)
- @Keegan (WMF): Thanks for posting this. I tried to contribute, but was unable to talk -- even after I thought I'd logged into a registered account. It's a long time since I've used IRC much, so it would be useful if the help page had rather more detailed information about what needs to be done to actually be able to participate. Also, it might be worth wondering whether the chat really needs to be restricted to registered accounts. Is there such a problem with spam and/or misleading IDs otherwise, or could this restriction be relaxed during office hours?
- Things I would have wished to say/ask:
- Re: Disambiguation. Would the obvious solution here (at least as it seems to me) not be to have a tool-tip that shows the Wikidata description when hovering over the item-label + Q-number? Clarification/disambiguation is what the WD description fields are *for*.
- "roadblocks for Lua support". Are the design requirements for this resolved now, now that it has been clarified that lookup by caption is unlikely to be useful (but lookup by filename might be) ? Does Lua access create any potential performanace impacts? -- eg if a Lua-driven template is changed, that might trigger simultaneous data requests for media-item data from a large number of file pages where the template is used, all at once. Is the back-end good to handle this; and/or are there thoughts on how it might be possible to reduce the number of data refresh requests in such a scenario?
- Any updates on SPARQL access to SDC? Any current timescales for when this might become available ?
- "Remaining grant time now only six months" -- obviously there is going to be a huge amount still to do in six months time. What long-term plans is the team making after that date? How likely is funding (WMF / external?) How much ongoing funding is anticipated to be needed? Are there any target milestones to achieve, that may unlock further funding?
- Search -- will there be easy ways to combine searches for category information and structured information -- eg show files in category X with/without property Y ? Or with property Y having a particular range or set of values? Is work going on to block out where search should be going? Will it be possible to show eg a grid of search results, rather than just a column? (so as e.g. to be able to show more hits in one screen) Will it be possible to re-order search results, eg by the value of some property?
- Capacity -- once eg QuickStatements for SDC comes on line, will the systems have capacity to support the numbers of bots trying to take information from Commons file pages and write it into properties? How much headroom is there?
- Thanks, Jheald (talk) 15:59, 27 July 2019 (UTC)
- @Jheald: I'm sorry to hear that you're muted during the time! I'm pretty rusty around IRC myself, perhaps someone more knowledgeable can help out on Talk:IRC office hours?
- To your points...
- I think the team was/is looking at using GuidedTours to provide functionality similar to what you describe, to at least provide users initial explanations for the links.
- Lua support is making progress after getting past the initial blockers, the engineer working on it put up a proof-of-concept patch to show they don't need a table. Hopefully it will be sorted out to production quality soon. T223792 is where one can get regular updates for this.
- SPARQL support is making progress, RDF dumps are being sorted out. The Wikidata Query Service and RDF/SPARQL support is maintained by a single person who does not work on the structured data team. The parent ticket for this work is T141602, you can subscribe to the child tickets for updates as the work moves forward.
- All I (and we know) right now is that the structured data team will continue work for at least six months after the grant period ends, which puts us to 1 July 2020. The next Annual Plan will inform work after that, but obviously it hasn't been written yet as we're just starting this year's plan :)
- I'll have to get back to you on where we are with advanced search.
- I have not heard any concerns around capacity here from the structured data team. I have no information on other teams/infrastructures right now.
- Thanks for taking the time to write this out, I'll try to followup on some points in August. Keegan (WMF) (talk) 20:09, 29 July 2019 (UTC)
MediaWiki space page for organizing the contents of the structured data tab
There's a new page up: MediaWiki:Wikibase-SortedProperties
This page controls the order in which items are displayed within the structured data tab. Without constraints, the order will be chronological from oldest to newest in which entries are added (with the exception of depicts, which will always be on top is usually first by suggestion, but it is uncontroled). By example, here's Wikidata's MediaWiki:Wikibase-SortedProperties page. Commons would need to put together something similar to force the display how the community would like it. Being a MediaWiki space page of course only administrators can edit it, so the talk page might help in sorting out how Commons would like to do this.
Similar information to what I've written is over at the mediawiki.org documentation page. Do let me know if you have any questions, and I'll do my best to answer them. Keegan (WMF) (talk) 16:39, 25 July 2019 (UTC)
- disruptive off-topic reply removed
- @Keegan (WMF): do you have some mock ups of the current design? I was always under the impression that we would get a special interface focused on file metadata curation. The current interface looks like a slightly modified/stripped down version of the Wikidata editing interface. Is this going to be it? Curating metadata and looking at metadata are two different processes and generally require a different design. Is this the curating interface, the viewing interface or both?
- By the way, MediaWiki:Wikibase-SortedProperties can only be edited by interface administrators, not by "normal" administrators. Multichill (talk) 16:33, 26 July 2019 (UTC)
- This is about the tenth time that I've forgotten we split out interface rights from sysop, I've always avoided editing the MediaWiki: space like the plague :)
- As for the interface, this is it for now with the constraints of time and focus the team has had to juggle as the grant period wraps up. The team would probably like to look at making changes in the future after this period of development is completed, and they'd love to hear your ideas on how to make this interface better, or how to design a practical curating interface. I'll followup with you on that soon if you'd like to talk with the team's designer. Keegan (WMF) (talk) 17:49, 26 July 2019 (UTC)
- From the error message I get it seems for me that Wikibase-SortedProperties can be edited by normal admins—interface editors’ exclusive right is only true for CSS/JavaScript pages and the like, not for usual MediaWiki messages, admins still have
editinterfaceright. —Tacsipacsi (talk) 20:04, 26 July 2019 (UTC)- Never a dull moment with MediaWiki. Keegan (WMF) (talk) 20:21, 26 July 2019 (UTC)
- From the error message I get it seems for me that Wikibase-SortedProperties can be edited by normal admins—interface editors’ exclusive right is only true for CSS/JavaScript pages and the like, not for usual MediaWiki messages, admins still have
@Keegan (WMF): Why isn't the page on Commons? Jheald (talk) 12:43, 27 July 2019 (UTC)- I see now that it is on Commons. Confusing prefix, though -- worth a rethink? Jheald (talk) 16:29, 27 July 2019 (UTC)
- The MediaWiki namespace is where the MediaWiki software keeps system messages and interface organization. I don't see that changing any time soon. Keegan (WMF) (talk) 17:06, 29 July 2019 (UTC)
- I see now that it is on Commons. Confusing prefix, though -- worth a rethink? Jheald (talk) 16:29, 27 July 2019 (UTC)
Search by depiction now being implemented in Commons Android app

Dear all,
I am delighted to let you know that Vanshika has started implementing search by depiction, please see the screenshot of how it currently looks.
- When you type "rabbit" in the search box, it shows you several items that match, for instance the Rabbit Zodiac sign or the tool for inserting samples inside a nuclear reactor.
- When you tap the item you want, it will display depictions of it.
- You can tap each file to get more information, for instance its captions and other depictions.
The feature should be released in September, but if you want it sooner don't hesitate to subscribe to the beta.
Cheers! 🐰 Syced (talk) 05:24, 30 July 2019 (UTC)
Other statements feedback
I havent got time to test on testcommons, so I have tested live and this came:
- on Wikidata once you set instance of value the engine provides you with recommended statements in drop down menus, this help everybody, who are not familiar with d. Here we start with depicts statement allready listed, which is good, and much better will be to provide the list of other most probably properties
- Is this discussed here: #MediaWiki space page for organizing the contents of the structured data tab? Juandev (talk) 04:32, 1 August 2019 (UTC)
- as an example, how do I structuraly explain that the image was taken in the Spring time or in March?
if I am in structured data tab and I wont to add date, there is no way to see file descrition on on click. Moreover, this could be filled automatically from the exif if expected- Now I see, I can move within tabs without loosing data
- big obstacle will be missing items, I would rething about providing the way to create them just within Commons, but on the other side people with know knowledge of wikidata may flood them with wrong items.
- is there a way to categorise/list files with and without structured data and or with certain properties of structured data? I guess it might be usefull for maintanance in the future
- if I add a new property, there is no icon of bin to remove it (before saving it) and suprisingly after saving each triplet, these unwanted triples stays. So I assume its a bug.Juandev (talk) 04:27, 1 August 2019 (UTC)
- Regarding dates: If your picture has EXIF then I am pretty sure you will have nothing to do :-) Regarding missing items: If there is no item, then enter what would have been its subclass, for instance if there is no item for "wooden suspended bridge" then use "suspended bridge". Regarding categorizing based on properties: That sounds redundant, and hopefully it can be solved by making a collection of useful SPARQL queries, with their results suitably cached. Regarding the other feedback: I don't know :-) Cheers! Syced (talk) 05:03, 1 August 2019 (UTC)
- Regarding deletion: I see the bin icons to delete each item at https://commons.wikimedia.org/wiki/File:Pr%C3%A1ce_s_navlh%C4%8Den%C3%BDm_sval%C3%A1kem_(002).JPG . Maybe you did not see them because you were looking at a history page? Syced (talk) 05:08, 1 August 2019 (UTC)
Depiction search: Please show thumbnails

In the Upload Wizard, I am asked to choose depictions.
- Problem: It is hard to guess which is the one I meant, especially when my locale (not English) has very few Wikidata labels and even less descriptions. Imagine the screenshot at the right without the descriptions and thumbnails.
- Solution: Display thumbnails based on each item's P18.
Why is this important? Because people are already misclassifying pictures using the Upload Wizard. I searched for depictions of https://www.wikidata.org/wiki/Q1683601 in the Commons Android app, and observed that two thirds of the images are misclassified.
All items that are often selected as depictions already have a P18, fortunately.
Thanks! Syced (talk) 05:37, 2 August 2019 (UTC)
- Thanks for the feature request. I'll get a Phabricator ticket filed for it soon. Keegan (WMF) (talk) 20:58, 5 August 2019 (UTC)
How to include subclasses in search (when I search for depictions of bands, also show rock bands)?
- When I search for "rock band", I get several pictures of Roxette and Bon Jovi
- When I search for "band", I don't get any picture of Roxette or Bon Jovi (even after scrolling through all pages)
Question: Is there a way to search for ALL bands? Not just the few random bands that happen to not yet have a subclass that fits.
While us Commons veterans (who have been molded to think in categories) might bear with the inconvenience, this is a problem that Structure can and should solve :-)
Thanks a lot! Syced (talk) 04:50, 1 August 2019 (UTC)
- I'll see about where we are with search. Keegan (WMF) (talk) 19:51, 6 August 2019 (UTC)
Usage not visible ?
https://commons.wikimedia.org/wiki/Special:EntityUsage/Q13395753 doesn't show https://commons.wikimedia.org/wiki/File:Leptothorax_kutteri.jpg Jura1 (talk) 21:14, 23 April 2019 (UTC)
- @Jura1: it's going to take awhile initially for search to catch up to the new database. There's a task to re-index search, which is going to speed things up, but it may take day or two to resolve. Keegan (WMF) (talk) 22:33, 23 April 2019 (UTC)
- The above is unrelated to cirrussearch. It's important that it works as otherwise people at Wikidata wont know that an item is in use here. Admins may end up deleting an item that appears unused. --Jura1 (talk) 01:37, 24 April 2019 (UTC)
- Ah, apologies for misunderstanding. I'll see where we are with special pages. Keegan (WMF) (talk) 16:38, 24 April 2019 (UTC)
- It might be more general than that. If usage isn't tracked, you wont get updates from Wikidata when labels are edited. Jura1 (talk) 11:19, 28 April 2019 (UTC)
- @Keegan (WMF): Any progress on this? This is a big issue, if eg an item on Wikidata gets split into two narrower items: one needs to be able to find out which Commons pages refer to the old item, so one can edit them to make sure they will be referring to the right one of the two new items. Jheald (talk) 11:42, 6 June 2019 (UTC)
- @Jheald: apologies for the delay, I've been away from work most of the past month. RIsler (WMF) is going to make a ticket to investigate. I'll add the tracking template here when I have a number available. Keegan (WMF) (talk) 19:42, 10 June 2019 (UTC)
- @Keegan (WMF): Any progress on this? This is a big issue, if eg an item on Wikidata gets split into two narrower items: one needs to be able to find out which Commons pages refer to the old item, so one can edit them to make sure they will be referring to the right one of the two new items. Jheald (talk) 11:42, 6 June 2019 (UTC)
- It might be more general than that. If usage isn't tracked, you wont get updates from Wikidata when labels are edited. Jura1 (talk) 11:19, 28 April 2019 (UTC)
- Ah, apologies for misunderstanding. I'll see where we are with special pages. Keegan (WMF) (talk) 16:38, 24 April 2019 (UTC)
- What's the outcome of this? At Wikidata, we are currently tracking the number of uses per property on property talk pages. I thought about adding counts from Commons there as well, but it seems that there is no way to "count" them. Isn't there? Search could possibly be used for properties, but qualifiers can't be counted independently. Is this correct? Jura1 (talk) 11:09, 7 August 2019 (UTC)
- @Keegan (WMF) and RIsler (WMF): how is it advancing? Is there a way to count uses of properties at Commons (we would like to include the stats on Wikidata, as we do for uses there). Search seems to be an option except for uses as qualifiers. Is there another one? Jura1 (talk) 17:45, 9 August 2019 (UTC)
New to structured data
Hello, I'm a big fan of the structured data concept on Commons, and was wondering if it would be nice to import all image (P18) → media legend (P2096) (from Wikidata) to the captions? I don't know exactly what format that is intended for use. Like should I remove wiki markups and WP-links from the import? - Premeditated (talk) 11:21, 10 August 2019 (UTC)
- Eventually I found Commons:File captions. - Premeditated (talk) 12:12, 10 August 2019 (UTC)
unable to add Wikidata items in "Upload Wizard"

I was unable yesterday to add more than one Wikidata item using the "Upload Wizard". I took a screen shot and uploaded it to Wikimedia Commons; see the accompanying image.
Secondarily, I seemed to have been forced to add one Wikidata item to upload the accompanying image. Until I did, I could not "proceed". Even then it was difficult for me to enter it. I tried several things that failed before finding the right combination of keystrokes that accepted the entry and enabled the "Proceed" button. I think this Wikidata item should be optional, and a user should be allowed to enter multiple Wikidata items if they are so inclined. If you disagree, I humbly beseech thee to provide better documentation to make it easier for a naive user, especially one who has never used Wikidata before, to understand what you want. Thanks, DavidMCEddy (talk) 09:01, 13 August 2019 (UTC)
- @DavidMCEddy: I'm sorry to hear about your difficult experience. Looking at the screenshot, it appears you were uploading from Wikipedia. If this is the case, could you tell me more about how you attempted to upload your file, what link or links you might have used? Special:UploadWizard is not enabled there, so it may be a similar-but-not-compatible tool that was being used that caused the error. Keegan (WMF) (talk) 16:59, 13 August 2019 (UTC)
Property for handling freedom of panorama cases

For cases of {{PD-art}} we have digital representation of (P6243). Here we have two works: A photo and the 2D work of art. The 2D work of art is in the public domain so we consider the the photo also to be in the public domain. Freedom of panorama is similar to this, but the other way around. A photo of a in copyright object (in this example Atomium (Q180901). Normally the photo wouldn't be allowed, but because we have freedom of panorama, we can use it. We can probably use a new property to model this. Maybe name it "copyright exemption" and use freedom of panorama (Q918113) as the object? As a qualifier we can use applies to jurisdiction (P1001) (Belgium (Q31) in this case) and applies to part, aspect, or form (P518) to indicate to what it applies (Atomium (Q180901)). The same property could probably be used for De minimis cases. What do you think? I would like to discus it here before I propose the actual property. Multichill (talk) 09:17, 21 July 2019 (UTC)
- This seems OK for me. Yann (talk) 13:03, 21 July 2019 (UTC)
- Seems like a good model. Is there any way we can avoid someone having to go through several non-obvious steps in the UI to do this for an existing file or their own upload? - Jmabel ! talk 18:40, 21 July 2019 (UTC)
For the reference, the proposal got accepted and turned into copyright exemption (P7152). –Simon04 (talk) 13:36, 14 August 2019 (UTC)
More of a "search data" or "search database"?
Honestly, I was confused when "structured data" was named for the current database. I honestly thought that it would summarize metadata. However, now that I see the release, the database is more of a "search data" or "search database". Besides adding items based on an image, how else does the database work? George Ho (talk) 17:02, 21 August 2019 (UTC)
- Well I thing this was a good step. We allready have a blog of text on each filepage called Metadata and it refers to the data from EXIF. So there is no confusion than. I guess in the future also EXIF data will be automaticaly (or with the help of the bot or tool) loaded to structured data. But definitely naming it is about the discussion. Juandev (talk) 20:19, 21 August 2019 (UTC)
Get the Wikibase identifier of files resulting from a Wikimedia Commons search
I want to fetch the Wikibase identifier (an integer with a M prefix) of all files resulting from a Wikimedia Commons search.
Example: Searching for aburasoba azabujuban, the query should return (potentially among other results) M80618155, because it is the Wikibase identifier of Tantanmen.jpeg whose caption contains these two keywords.
Problem: The API call in the documentation does not return the Wikibase identifier, instead it only returns the title/URL/etc of each file. — Preceding unsigned comment added by Aroravanshika (talk • contribs) 14:58, 25 August 2019 (UTC)
Question: How can I modify this API call to retrieve the Wikibase identifiers? If possible without making another request for each result.
https://commons.wikimedia.org/w/api.php?action=query&format=json&formatversion=2&generator=search&gsrwhat=text&gsrnamespace=6&prop=imageinfo&iiprop=url%7Cextmetadata&iiurlwidth=640&iiextmetadatafilter=DateTime%7CCategories%7CGPSLatitude%7CGPSLongitude%7CImageDescription%7CDateTimeOriginal%7CArtist%7CLicenseShortName%7CLicenseUrl&gsrsearch=aburasoba%20Azabujuban&gsrlimit=10 — Preceding unsigned comment added by Aroravanshika (talk • contribs) 14:59, 25 August 2019 (UTC)
- Your query returns the page id, prepend M to that and you have it. Multichill (talk) 15:45, 25 August 2019 (UTC)
- Thanks Multichill! I had not realized that myself either :-) Syced (talk) 00:29, 26 August 2019 (UTC)
Find most-depicted Wikidata items that have no image
How to generate a list of such Wikidata items?
- Item is used as a "depicts" value by a lot of Wikimedia Commons files
- Item does NOT have a P18 (image) property
It is tricky because it involves two Wikibase servers: Wikidata, and the Structured Data on Commons (SDoC)'s Wikibase server. I am open to any solution, SPARQL or not, hosted or not, open source or not. My final goal is to help people select good P18s from these depictions. WDFIST does not have such a feature.
Thanks! Syced (talk) 07:33, 26 August 2019 (UTC)
- I think this is not possible yet. There are some things need to be implemented first. --GPSLeo (talk) 15:03, 26 August 2019 (UTC)
- While you're waiting for this to be possible, you might be interested in looking at en:User:Mike Peel/NHLE no image with commonscat (similar Wikidata-generated lists on other topics are possible), or Category:Uses of Wikidata Infobox with no image. :-) Thanks. Mike Peel (talk) 18:04, 26 August 2019 (UTC)
- "this is not possible yet" <- I am open to any solution, even manual solutions such as first making a list of most-depicted items, then checking their P18 manually :-) Does a list of most-depicted items exist? That sounds possible even now, I would say? Syced (talk) 03:10, 27 August 2019 (UTC)
How to help desk for structured data
Maybe we should add new table to our Village pump (or link to similar on Wikidata) on how to do something with structured data. Questions of "how to" were already written during testing period, so I expect they will be quite often.Juandev (talk) 04:35, 1 August 2019 (UTC)
- Good idea! Structured data questions will probably increase a lot, and not many people are able to answer them. How about making this discussion page a "Structured data village pump", just like there is already a "Graphics village pump" which is linked to from the main village pump? Syced (talk) 04:54, 1 August 2019 (UTC)
- I'm happy to support any new community places for conversations, or help documentation, that people would like to put together as Commons figures out how it would like to use this software. Keegan (WMF) (talk) 15:12, 1 August 2019 (UTC)
- If the WMF team is not against, why not. Juandev (talk) 17:23, 7 August 2019 (UTC)
- So how to called such help desk? Juandev (talk) 17:46, 28 August 2019 (UTC)
Weird error
Hey,
can you reproduce this error. I am in FF:
- go to File:Tehov (okres Benešov) (04).jpg
- click on Structured data
- click on edit
- edit count for house, type 4
- save
When I did it for the first time, it come out with 10 and for the second time with 1. Juandev (talk) 09:45, 28 August 2019 (UTC)
- I just tried on Firefox 68.0.2 on Linux. I entered 4, published, and it worked fine for me. Syced (talk) 10:08, 28 August 2019 (UTC)
OK. Thx. Juandev (talk) 17:45, 28 August 2019 (UTC)
Help with Structured Data
Hello! I have some question of best practice for usage of Structured Data in some different cases.
- How should I state the copyright license (P275) in the image File:Macaca nigra self-portrait large.jpg? It's public domain, because as the work of a non-human animal.
- How does I depicts (P180) that this image, File:Ferrari-Monaco-4071021.jpg, is the Rear View of the car? I have mentioned it in the captions, but I also want to describe it in the Structured Data. - Premeditated (talk) 05:52, 2 September 2019 (UTC)
- @Premeditated: depicts (P180) = Ferrari 488 (Q18943721), with qualifier depicted part (P5961) = automotive engine (Q4056355). There also ought to be a Wikidata Q-item for "rear", that should also be a value for the P5961 qualifier, but it doesn't look as if anyone has created one yet (nor similarly for "front"), though stern (Q273062) (of a ship) exists. It would be good to create items on Wikidata for "front" and "rear", in the sense of the front and rear of an object.
- It might also be good to have a property to specify "relative position of viewpoint", that could take values like backwards (Q16938807). Jheald (talk) 14:25, 2 September 2019 (UTC)
- @Jheald: the German description of stern (Q273062) also includes cars and airplanes as vehicles to which the term could apply. But perhaps that should be split into a separate item? In German, „Heck“ can apply to all kinds of vehicles as far as I’m aware, but that might not be the case for “stern” in English. --Lucas Werkmeister (talk) 14:31, 2 September 2019 (UTC)
How to
I have a few questions how to:
- if the image is from a specific village, can I use located in the administrative territorial entity (P131) to indicate its location?
- If I have an image with sky covered by clouds, I would like to set depicts - sky and do we have a quantifier "with features" or it is not a good approach?
- how to add the information, that the image contain countryside in summer or in July?
Thx! Juandev (talk) 14:04, 4 September 2019 (UTC)
Structured data help desk
So I have found a separated page to help people with structured data and don't spam here. Add it to your watchlist please and let's help each other to develop SD. Juandev (talk) 15:28, 4 September 2019 (UTC)
Numbers for legend

In the above version of the image, the people are numbered to make it easier to identify them.
There is a proposal for a new property "identified in image by" to store this as structured data. Alternatives suggested there are inscription (P1684), issue (P433), quantity (P1114). Maybe you already found a better solution for this. Please comment in the property proposal discussion. Jura1 (talk) 13:43, 13 August 2019 (UTC)

The proposal at "identified in image by" could probably work for the above as well. It's still open btw. Jura1 (talk) 06:42, 10 September 2019 (UTC)
New user script: Add to Commons / Descriptive Claims (AC/DC)
![AC/DC [publish changes button]; Files to edit: [six filenames]; Statements to add: depicts Caroline Zhang with expression, gesture or body pose Biellmann spin; [add statement button]](/wiki/File:Add_to_Commons_Descriptive_Claims_-_Caroline_Zhang.png)
Hi everyone! I wrote a user script to add a collection of statements to a set of files – you enter or paste the list of files at the top, then select the statements to add using the regular statement interface for MediaInfo entities (same as in the Structured data tab). Existing statements will not be duplicated, and you can also use this to add extra qualifiers to them. See the documentation page for more information, including installation instructions, and please let me know how it works for you! (Though I’m offline from tomorrow until Sunday, unfortunately – I didn’t schedule this very well.) --Lucas Werkmeister (talk) 08:04, 8 August 2019 (UTC)
- Thanks you, I just tried with all the files in this category, this work well though the fact of having to select each image one by one is a bit tedious. Christian Ferrer (talk) 11:01, 9 August 2019 (UTC)
- Thank you! It looks nice! Strakhov (talk) 14:42, 9 August 2019 (UTC)
- This is really awesome! I think one of the challenges for me is @Lucas Werkmeister (WMDE): , is similar to the one that Christian Ferrer describes: getting file names in a list is cumbersome (except if you are, say, printing the list from Petscan). I think the visual selection strategy that Cat-a-lot and Visual File Change use is a must for making this highly utilitarian in a lot of setting. Sadads (talk) 15:43, 9 August 2019 (UTC)
- If we could select the files (among others the files (or some of the files) from a specific category) a bit as we can do it with VFC, it will be perfect. Christian Ferrer (talk) 18:19, 9 August 2019 (UTC)
- This is really awesome! I think one of the challenges for me is @Lucas Werkmeister (WMDE): , is similar to the one that Christian Ferrer describes: getting file names in a list is cumbersome (except if you are, say, printing the list from Petscan). I think the visual selection strategy that Cat-a-lot and Visual File Change use is a must for making this highly utilitarian in a lot of setting. Sadads (talk) 15:43, 9 August 2019 (UTC)
- I left a comment about visual file selection on User talk:Lucas Werkmeister/ACDC#Feedback, let’s continue that part of the discussion there. --Lucas Werkmeister (talk) 14:53, 11 August 2019 (UTC)
- Thank you! It looks nice! Strakhov (talk) 14:42, 9 August 2019 (UTC)
- Update: this is now a gadget! See Help:Gadget-ACDC. (If you added the user script to your common.js, that will still work for the time being, though I’d still recommend removing that and enabling the gadget in your preferences instead.) --Lucas Werkmeister (talk) 22:52, 12 September 2019 (UTC)
- Great work Lucas, much appreciated. - Premeditated (talk) 05:57, 13 September 2019 (UTC)
Let's do some modeling!
To be able to (mass) add structured data to Commons, we have to agree on how to model the data. To kick-start this process, Sandra and I organized some sessions during Wikimania 2019 to discus this modeling in person. We looked at the current templates to see what kind of information is stored. Based on that we identified different modeling challenges like how to model dates, sources and authors. We put the notes on the talk pages so we can pick up the discussion and solve these modeling puzzles. Please help us figure this out.
Pinging @Spinster, VIGNERON, Satdeep Gill, Jheald, Hannolans, Vysotsky, Kaldari, Susannaanas, Puik, and Lucas Werkmeister: , some participants in the sessions at Wikimania. But of course we welcome and invite everyone to chime in. Multichill (talk) 19:40, 12 September 2019 (UTC)
Detail of painting

There is some discussion at the property proposal for detail of painting on what to use for these.
Such close-up views tend to end up in Category:Artworks_without_Wikidata_item, but shouldn't have a separate item on Wikidata. --Jura1 (talk) 07:32, 10 September 2019 (UTC)
The painting should have one image that has as much as possible of the painting, and a category should be made with the various parts, including the versions of the painting that show the frame. Just add the painting item to all detail images. Jane023 (talk) 13:57, 13 September 2019 (UTC)
All properties
When all properties will be available? Juandev (talk) 14:50, 12 September 2019 (UTC)
- @Juandev: there's no one release date for the rest of the datatypes, they are being worked on one-by-one. Current work is to support geo-coordinates in qualifiers as the first release to make sure they work properly, after that will be geo-coordinates in top-level statements. Following geo-coordinates, in no particular order:
- T231979 Add UI support for time Wikibase datatype for top-level statements
- T231981 Add support for top-level statements with quantity values, and units for quantity data type
- T231994 Add support for url data type (top-level statements and qualifiers)
- T231995 Add support for 'external identifier' data type (top-level and qualifiers)
- These are the ones scheduled for work for now. You can keep track of progress on the Phabricator tasks, if you'd like to subscribe. Keegan (WMF) (talk) 21:28, 12 September 2019 (UTC)
- Thx! I thought its much easier and you just switch them on in wikibase! Juandev (talk) 15:00, 13 September 2019 (UTC)
Obverse and reverse images


c:Category:Media files produced by UNESCO: 2019-09 includes many images with reverse sides. These are generally useful only in conjunction with the front side.
To include this with structured data, a short property proposal at d:Wikidata:Property proposal/front and backside. Please help complete it. Jura1 (talk) 10:50, 13 September 2019 (UTC)
This issue also exists on Wikidata for paintings and manuscript pages. See e.g. d:Q27814872, where I just split the item into two paintings. Jane023 (talk) 14:03, 13 September 2019 (UTC)
- Sometimes part of the series (P179) or pendant of (P1639) works for that, but requires a separate item. I'm not sure if creating one for File:Culture, Medina at Fes Campaign - UNESCO - PHOTO0000002039 0000.tiff would be helpful. Jura1 (talk) 15:48, 13 September 2019 (UTC)
- Yes but those properties are for when you already have separate items. On Wikidata you need one item for the thing itself and then the two surfaces can be described as if they were separate objects. I suggest following similar logic for Commons. I am not suggesting a need for Wikidata items for these photos - I assume (without digging deeply into it) that they are not notable enough for Wikidata. Jane023 (talk) 16:08, 13 September 2019 (UTC)
Computer-aided tagging tool
The development team is starting work on one of the last planned features for SDC v1.0, a lightweight tool to suggest depicts tags for images. I've published a project page for it, please have a look. I plan to share this page with everyone on Commons much more broadly in the coming days (starting with the Village Pump tomorrow), but wanted to put first notice up here. The tool has been carefully designed to try to not increase any workload on Commons volunteers; for starters, it will be opt-in for auto-confirmed users only and will not generate any sort of backlog here on Commons. Additionally, the tool is highly privacy-minded for the contributors and publicly-minded for the third party being used, in this case Google. The implementation and usage notes contain more information about these and other potential concerns as a starting place. It's really important that the tool is implemented properly from the start, so feedback is welcome. Questions, comments, concerns are welcome on the talk page and I will get answers as quickly as possible as things come up. The first desktop designs will be ready in a few weeks, the team would like to hear from you first. Keegan (WMF) (talk) 20:59, 16 September 2019 (UTC)
- As Keegan mentioned above, the dev/design team is looking forward to feedback from community on this new tool and we'll be monitoring the conversation and answering questions. Thanks! RIsler (WMF) (talk) 22:06, 16 September 2019 (UTC)
Point in time not allowed?
Depicts cant take it as a qualifier. Nor is it possible to be a statement. Why? The date/year when a photo was taken could be quite important info.--Roy17 (talk) 23:01, 18 September 2019 (UTC)
- Hello! Support for time/date data types is currently in development. Our team has to recreate Wikidata UI functionality so that it works on Commons. We'll make an announcement when it's ready. RIsler (WMF) (talk) 23:19, 18 September 2019 (UTC)
- Time zones would be good too, but I suppose that will need to be a separate task. --ghouston (talk) 03:46, 22 September 2019 (UTC)
digital representation of (P6243)
On Wikidata digital representation of (P6243) is up for deletion. It's used quite a lot so feels a bit like trying to sabotage this project. Multichill (talk) 09:02, 21 September 2019 (UTC)
- Please go read the discussion, there's a lot of confusion about this property, and you seem to think that it should be used it in a different way than what the property proposal described, which other people are disagreeing with. Thanks. Mike Peel (talk) 12:49, 21 September 2019 (UTC)
- @Multichill: d:Properties_for_deletion leads nowhere, at least for me. - Jmabel ! talk 16:52, 21 September 2019 (UTC)
- @Jmabel: Try [24]. Thanks. Mike Peel (talk) 16:56, 21 September 2019 (UTC)
- @Multichill: d:Properties_for_deletion leads nowhere, at least for me. - Jmabel ! talk 16:52, 21 September 2019 (UTC)
General Wikibase problem
It was told me, that Commons' Wikibase could not hold its own properties and items. I can see this to be a problem in the future. Today, there is one dispute over Wikimedia Commons only property on Wikidata, but Wikimedia Commons community, will need more properties. Will this be warmly welcomed by the members of another project? I am not sure. How efficient will be this initiative if we cannot have properties and values we need to have?
Imagine also the situation when third parties using Wikibase. Cool, the may think. We have new software, we have lots of shared properties and values we can use, but after a certain time, they will conclude, they need more properties. How they will push Wikidata community to accept third-party properties? Juandev (talk) 21:06, 21 September 2019 (UTC)
- It seems to me that it's mainly a discussion among fairly active Commons contributors and Wikidata contributors like me holding back. .. It's a discussion one could have held here too ..
- What seems sub-optimal is that the property was created only shortly after the proposal was changed substantially. A bit odd for something that couldn't be used for months afterwards.
- When I went through c:Commons:Structured data/Properties table, I bridged a few gaps, but I got the impression that Wikidata already made available most properties you might need. As usage on files is likely somewhat different from Wikidata itself, contributors here will need to work out how in some detail.
- The main remaining gaps seem to be the datatype for Commons users (or some other solution) and some mapping for exif, both need some software development. The first might be higher priority than the later (which can wait till a query server is available). Jura1 (talk) 22:33, 21 September 2019 (UTC)
- I don't think there's much chance of getting that design decision changed, unless it turns out that structured data on Commons is completely unworkable otherwise. I think we are still at the stage of finding workarounds. --ghouston (talk) 03:44, 22 September 2019 (UTC)
Datatype for Commons photographers
Moved to Commons talk:Structured data/Modeling/Author#Datatype for Commons photographers. Multichill (talk) 08:49, 14 September 2019 (UTC)
- Not sure if that is the right place. It's more of a Wikibase feature proposal than a question about data modeling. One still would need to create one or several actual properties. Jura1 (talk) 10:41, 14 September 2019 (UTC)
- @Keegan (WMF) and RIsler (WMF): what's your view on the datatype/status on alternatives? Jura1 (talk) 16:06, 22 September 2019 (UTC)
New blog post on ways to work with Structured Data on Commons
Hi folks! I just wanted to mention that I wrote a blog post on some ways in which you can work with Structured Data on Commons today, and what more is coming soon: Working with Structured Data on Commons: A Status Report. I hope some of you find this information useful! (Also, Keegan has been writing a series of blog posts about SDoC, see the corresponding tag for a list – go check those out too!) --Lucas Werkmeister (talk) 08:32, 27 August 2019 (UTC)
- Lucas: Great post, thanks! In the "coming soon" section, how about adding this revolutionary feature which will help all Commons users classify images better? Cheers! Syced (talk) 09:18, 28 August 2019 (UTC)
- @Syced: I don’t think I can edit the post after publication (and if I could, I’m not sure if I would – this post is, by nature, a snapshot, and I hesitate to give the impression that it’s kept up to date with new developments), but if you leave a comment about that feature on the Discuss section, it’ll show up below the Wordpress version too :) --Lucas Werkmeister (talk) 20:51, 28 August 2019 (UTC)
- It is a great post, isn't it? As a non-technical person, I learned from it as well :) Thanks for writing it up and sharing on Wikimedia Space, Lucas, and mentioning my "SDC for the layperson" series that I'm working on. I appreciate you and your work. Keegan (WMF) (talk) 20:40, 28 August 2019 (UTC)
- @Lucas Werkmeister: the last part of the SDC series I wrote is being published this week. I'll be sending out the links for reading at the end of the week, as we discussed on Meta. Keegan (WMF) (talk) 20:19, 9 September 2019 (UTC)
- @Lucas Werkmeister: fyi, I sent out links to the blogs to the Structured Data on Commons newsletter list. Keegan (WMF) (talk) 21:35, 23 September 2019 (UTC)
- @Keegan (WMF): great, thanks! --Lucas Werkmeister (talk) 21:50, 23 September 2019 (UTC)
- @Lucas Werkmeister: fyi, I sent out links to the blogs to the Structured Data on Commons newsletter list. Keegan (WMF) (talk) 21:35, 23 September 2019 (UTC)
- @Lucas Werkmeister: the last part of the SDC series I wrote is being published this week. I'll be sending out the links for reading at the end of the week, as we discussed on Meta. Keegan (WMF) (talk) 20:19, 9 September 2019 (UTC)
Input on painting
Hello, I have tried to describe the image File:Mona Lisa, by Leonardo da Vinci, from C2RMF retouched.jpg with Structured Data. But I have not followed any striced modeling for photographs of paintings, other than the properties table. Therefore, some questions arise:
- I have used depicts (P180) → Mona Lisa (Q12418), but maybe depicts (P180) → person depicted in Mona Lisa (Q11879536) is better?
- How to best depicts (P180) objects in for example the background? I have used applies to part, aspect, or form (P518) & expression, gesture or body pose (P6022). Are there any better ideas?
- How do we differentiate all of the versions?
- How do we differentiate date of image taken and finished painting?
- (Where do i put genre (P136) → portrait (Q134307)?)
Thank you in advance for input - Premeditated (talk) 15:24, 22 September 2019 (UTC)
- Well I think you are in front of time. There should be something called "depicts of depicts" which should apply to artworks and it didn't arrive yet. Moreover, I think, here would be better to agree on the same data modeling. Moreover, we don't have all the properties available yet on WMC so it's hard to experiment with the system. Juandev (talk) 20:41, 2 October 2019 (UTC)
- You just need depicts (P180)=Mona Lisa (Q12418) - pretty much everything else is just duplicating information from the Wikidata item, which isn't useful/creates a maintenance nightmare. As Juandev says, that information can't be retrieved just yet, but hopefully will be soon, either through SDC directly or through Lua access to the Depicts statements. Thanks. Mike Peel (talk) 07:04, 3 October 2019 (UTC)
Unwanted duplication in UploadWizzard
I have added Structured Data a couple of times in UW (I normally use Vicuna) and it seems to me, if you fill structured data for the first file, it adds the same SD to other files in the batch. But this is deffinitely not wanted function. Juandev (talk) 20:04, 28 September 2019 (UTC)
- Thanks for leaving the feedback. Keegan (WMF) (talk) 20:08, 2 October 2019 (UTC)
Computer-aided tagging design consultation
I've published a design consultation for the computer-aided tagging tool. Please look over the page and participate on the talk page. I'll be posting about this elsewhere on-wiki and on mailing lists over the next day. The tool will hopefully be ready by the end of this month (October 2019), so timely feedback is important. Keegan (WMF) (talk) 20:55, 8 October 2019 (UTC)
Search for depicts qualifier
Is there a way to use search to find just a qualifier, e.g. wears (P3828) or a specific value of P3828?
Below a few that seem to work/don't work. Please add more samples/correct syntax.
- OK: depicts (P180)=woman (Q467) and qualifier wears (P3828)=any value
 Not OK: depicts (P180)=any value and qualifier wears (P3828)=dress (Q200539)
Not OK: depicts (P180)=any value and qualifier wears (P3828)=dress (Q200539)
- OK: depicts (P180)=house cat (Q146) and qualifier quantity (P1114)=any value
- Not OK: qualifier quantity (P1114)=any value
- OK: depicts (P180)=any value
I'm trying to include more queries in property talk pages at Wikidata.
Currently there are search links to find statements if a Commons sample is present on the property, e.g. <search Commons for files with property> on d:Property talk:P180, as there is d:Property:P180#P6685. Jura1 (talk) 09:13, 12 October 2019 (UTC)
- An approach for depicts (P180) and qualifier wears (P3828) could be Special:Search/haswbstatement:P180 +"wears:". Obviously, it can include other results. Jura1 (talk) 10:10, 12 October 2019 (UTC)
- I think wildcards are only allowed on the end of the search string. Someone might be able to change that. Multichill (talk) 15:42, 13 October 2019 (UTC)
- Something like depicts (P180)=any value and qualifier wears (P3828)=dress (Q200539) would probably be useful. Eventually the more general problem of tracking uses of properties at Commons needs to be solved as well.
- BTW In the meantime, I added "wears"-type of searches to Wikidata property talk pages. Jura1 (talk) 09:21, 14 October 2019 (UTC)
- I think wildcards are only allowed on the end of the search string. Someone might be able to change that. Multichill (talk) 15:42, 13 October 2019 (UTC)
- We currently don't have functionality to address the searches that don't work above. We did identify the need to do so last year (see this ticket) but it was technically a bit challenging at the time. We'll look into seeing if we can enable it now, although searches like this may be better suited for the still-in-progress Commons Query Service. RIsler (WMF) (talk) 23:27, 15 October 2019 (UTC)
Java libraries
Hey,
we are working on a new desktop upload tool and there is a comment from the developer that there are no java libraries for structured data. As far as I completely dont know what is it about, my questions are as follows. Is it possible to add depicts and other statements to those libraries? Would it by usefull? Other comments regarding this? Regards Juandev (talk) 17:43, 17 October 2019 (UTC)
- @Juandev: We just released a new version of Wikidata Toolkit with MediaInfo retrieval and edit support. Here are two examples, one for retrieval and one for edit. Feel free to ping me if you need some help. Tpt (talk)
Sorting the statements
I updated MediaWiki:Wikibase-SortedProperties to do a bit of sorting of the statements in structured data. Just a start. If you have properties that should be addded, please either respond here or on the talk page so we can grow that. Multichill (talk) 12:49, 26 October 2019 (UTC)
- Maybe Commons quality assessment (P6731) and owned by (P127) would be useful. - Premeditated (talk) 15:54, 26 October 2019 (UTC)
Lua access


Thank you, SDC team, and well done - it works! Template:MonumentID/SDC is a test for an update of monument identifiers here to use the SDC depicts (P180) values. User:Mike Peel/LuaSDC shows the results of some other tests ({{Wikidata Infobox}} works - sort of! - try {{Wikidata Infobox/sandbox|qid={{#invoke:Wikidata Infobox/sandbox|getMID}}}}} on a file page for the best results at the moment), and you can try {{User:Mike Peel/SDC Test}} on file pages if you want (but don't save them, as that's not a good look on file pages!) Thanks. Mike Peel (talk) 17:42, 25 October 2019 (UTC)
- Yeah, this is something that also could be useful for Wikipedia and for other wiki's also. Made a quick module to test it out, using both captions and an item. And best of all, it all showes in your language. - Premeditated (talk) 07:18, 28 October 2019 (UTC)
- This is super exciting. And @Premeditated: I followed your edit history to learn more and discovered supports SDC: so cool! Now how do we get that more thoroughly integrated into file pages :) Sadads (talk) 14:32, 28 October 2019 (UTC)
- The initial template has morphed into {{Structured Data}}, with a demo at File:Jodrell Bank Mark II 5.jpg. I'm continuing to iterate on it, feedback would be appreciated! Thanks. Mike Peel (talk) 20:46, 29 October 2019 (UTC)
Development roadmap
The development and release roadmap has not been updated since June. What is the team actually working on and when are the next feature releases planned? Thanks. --GPSLeo (talk) 11:26, 4 November 2019 (UTC)
- @GPSLeo: good question. The team has mainly been working in three areas:
- Extend Wikibase Lua support to structured data on Commons (T223792) - mostly complete a few more things are left to plug in (see also Commons talk:Structured data/Lua)
- Support for all properties in structured data, such as geo-coordinates, URLs, quantities. Being released in pieces as they are completed.
- The computer-aided tagging project - which just went through a community design review, and is being prototyped for showcasing to Commons, development, and release.
- The development team is having an in-person meeting later this month that I'll be attending, I believe we'll firm up the roadmap for the future and update many things after those discussions. Keegan (WMF) (talk) 21:35, 5 November 2019 (UTC)
- Also some reading materials at Wikimedia Space and in the latest office hour. - Premeditated (talk) 08:43, 6 November 2019 (UTC)
Commons search seems to have stopped indexing statements since 30 October 2019
I noticed this and filed a bug for it. Multichill (talk) 11:31, 10 November 2019 (UTC)
Constraint violations
It seems that constraint violations are not yet being flagged on SDC.
This is something we need, and urgently, if SDC is to roll out in an orderly way.
For example source of file (P7482) has just been approved -- but on the proviso that so far, only the value original creation by uploader (Q66458942) is initially approved, to give the community time to think how we want to model more complex cases.
It is essential that when people start seeing source of file (P7482) = original creation by uploader (Q66458942) statements appearing, they don't (quite naturally) see this as a green light to start adding source of file (P7482) = <any old thing they've just thought of>, but instead get some warning that only a list of approved values is appropriate.
So constraint-violation flags are something we urgently need the interface to start showing. Jheald (talk) 11:07, 27 October 2019 (UTC)
- In the meantime you can keep an eye on this search. Multichill (talk) 20:54, 27 October 2019 (UTC)
- Thanks, Multichill.
- @Keegan (WMF), SandraF (WMF), and Abittaker (WMF): Is there any chance it would be possible for one of you to talk to someone from the SDC UI team and light a fire under this? I am a bit perturbed to look at eg the UI column second from the right on the SDC statements board [25], and apparently see no mention of this. There are tickets like phab:T232365 which seem to be related to bespoke input validation for a few special-case input situations (eg latitudes more than 90 degrees north, or less than 90 degrees south), to stop that at time-of-entry, but seemingly nothing about the general established constraint warning mechanism, which is a lot more universal and therefore important. Would it be possible for you to get an idea of how big an ask it would be to get constraint-warning flags to start appearing in the UI, per ticket phab:T230314, and if it would be possible to achieve this relatively soon? Thanks, Jheald (talk) 12:11, 28 October 2019 (UTC)
- @Jheald: like most all things SDC, the work required is complicated. On a practical level, first the team has to finish support for all statement types, then they'd have to re-do the UI to support constraints, as the current Wikidata design doesn't match the design for Commons. From what I understand, there's an even larger technical block in the (current) lack of API support for constraints on Commons.
- So, it's something the team is aware of and is something that they can and would like to do, however the work would be an investigation in six to eight months time to scope the ask, and that's if it's something the team will be able to work on that far in the future as the scope or focus might have shifted enough to de-prioritize this. Tl;dr: maybe look at it next summer? I'll get something like this into the ticket as well. Keegan (WMF) (talk) 20:14, 31 October 2019 (UTC)
- @Keegan (WMF): As far as I’m aware, for API support the extension only needs to be enabled on this wiki; I tried it out locally and it seems to support MediaInfo entities out of the box. (Of course it’s possible that in a federated setup there will be complications that I didn’t encounter locally.) --Lucas Werkmeister (WMDE) (talk) 12:41, 12 November 2019 (UTC)
- Thanks, Lucas. Yes, in theory, like most of what we're doing, this should plug 'n play, but I anticipate there are complications with federation. The team will get to it eventually. Keegan (WMF) (talk) 20:57, 12 November 2019 (UTC)
- @Keegan (WMF): As far as I’m aware, for API support the extension only needs to be enabled on this wiki; I tried it out locally and it seems to support MediaInfo entities out of the box. (Of course it’s possible that in a federated setup there will be complications that I didn’t encounter locally.) --Lucas Werkmeister (WMDE) (talk) 12:41, 12 November 2019 (UTC)
EXIF and metadata and structured data
Are there already ideas to copy the information from the EXIF/metadata to the wikibase item? Will that be done server side or should that be done by community created Bots. The second way with regular Bots would create many hundred million edits and would take some month to do this for every file. --GPSLeo (talk) 23:33, 11 November 2019 (UTC)
- Supposedly there's going to be a feature where Exif data can be queried by statements that extract data directly from the existing file info. --ghouston (talk) 23:38, 11 November 2019 (UTC)
- Relating to the general topic: Many popular camera lenses are fully manual and provide no information to the camera (example of picture taken with such lens). Aperture and focal length would have to be provided manually for such lenses, somehow. Same goes for film photography. --Njardarlogar (talk) 19:41, 12 November 2019 (UTC)
- That could also be a topi users are querying for: Images taken with manual focus and full manual aperture and exposure. I think that would be easy to find in the data. Of course assuming that EXIF did not got modified on propose or accidentally. --GPSLeo (talk) 22:04, 12 November 2019 (UTC)
- I think this is going to be discussed in Model discussions. --Juandev (talk) 10:31, 13 November 2019 (UTC)
- That could also be a topi users are querying for: Images taken with manual focus and full manual aperture and exposure. I think that would be easy to find in the data. Of course assuming that EXIF did not got modified on propose or accidentally. --GPSLeo (talk) 22:04, 12 November 2019 (UTC)
- Relating to the general topic: Many popular camera lenses are fully manual and provide no information to the camera (example of picture taken with such lens). Aperture and focal length would have to be provided manually for such lenses, somehow. Same goes for film photography. --Njardarlogar (talk) 19:41, 12 November 2019 (UTC)
Depicts search - coming soon

The developers are finishing up the ability to search depicts statements in the search bar without any advanced tools or using haswbstatement. This change will go live within a few weeks. It is available for registered users only, is opt-in by default, but can be turned off at any time in a user's search preferences once the feature is here. I'll provide an update when I know more about when this will be available. I'm also posting this message on the Village Pump. Keegan (WMF) (talk) 19:10, 12 November 2019 (UTC)
- @Keegan (WMF): Is it opt-in or can one opt out from it? These two are just the opposite of each other… —Tacsipacsi (talk) 10:24, 13 November 2019 (UTC)
- It is on by default, so I should have written "opted-in by default" and users can switch it off. Thanks for pointing that out. Keegan (WMF) (talk) 16:04, 13 November 2019 (UTC)
Scandinavian Runic-text Database ID (P1261) - how to use???
E.g. in File:Sundby_U_81_rättvänd.jpeg how do I add U 81 to the Rundata property? @ديفيد عادل وهبة خليل 2: Macuser (talk) 11:00, 4 November 2019 (UTC)
- @Macuser: I don't think you should. Rather, you should have depicts (P180) runestone U 81 (Q18334426), and then the Scandinavian Runic-text Database ID (P1261) property is already attached to runestone U 81 (Q18334426). Attaching Scandinavian Runic-text Database ID (P1261) to the file would be to assert that the photograph is runestone U 81, which isn't correct. --bjh21 (talk) 14:19, 11 November 2019 (UTC)
- @Bjh21: , thank you for you answer. However, it does not achieve the point: it says, that File:Sundby_U_81_rättvänd.jpeg depicts runestone U 81. If I continue like that, File:Runinskrift U90, teckning av Johan Hadorph och Johan Leitz, 1682.jpg depicts Q10710106, File:Upplands_runinskrift_419.jpg depicts Upplands runinskrifter 419 and File:U 97, Collectaneum Monumentale Runicum.jpg depicts NOTHING, because there is nowhere a page or data element for U 97. The idea behind property is to add a systematic classification, isn't it? As if I want to create an article, I can easily find illustration, so it should be possible to use for U 97 too. Macuser (talk) 15:45, 14 November 2019 (UTC)
- @Macuser: I think in this case the answer is that you should add an item for U 97 to Wikidata. U 97 fulfils the requirements of d:Wikidata:Notability in that it is a clearly identifiable ... material entity, and it can be described using serious and publicly available references, even if no project yet has an article about it. --bjh21 (talk) 16:52, 14 November 2019 (UTC)
- @Bjh21: , but there are thousand or more such unexisting records in wikidata, e.g. red links here sv:Lista_över_Upplands_runinskrifter. And this is aside from that qualifiers like runestone U 81 (Q18334426) give (and have) completely random values, ranging from no-name Uppland Runic Inscription 90 (Q10710106) to arbitrary set runestone U 81. It would be much better to restore functionality of the Scandinavian Runic-text Database ID (P1261), where a text field with the signum can be entered explicitly (even the filters are present in the Scandinavian Runic-text Database ID (P1261) discussion!).Macuser (talk) 18:18, 14 November 2019 (UTC)
- @Macuser: I think that would be a misuse of the property. Scandinavian Runic-text Database ID (P1261) is clearly designed to link a runestone to its identifier, not to link a picture to an identifier. Its single-value, unique-value, and type constraints would all be broken by using it on pictures. There's no problem with adding a thousand items to Wikidata: you could ask on d:Wikidata:Bot requests if creating them on demand is a problem. --bjh21 (talk) 18:49, 14 November 2019 (UTC)
- @Bjh21: , but there are thousand or more such unexisting records in wikidata, e.g. red links here sv:Lista_över_Upplands_runinskrifter. And this is aside from that qualifiers like runestone U 81 (Q18334426) give (and have) completely random values, ranging from no-name Uppland Runic Inscription 90 (Q10710106) to arbitrary set runestone U 81. It would be much better to restore functionality of the Scandinavian Runic-text Database ID (P1261), where a text field with the signum can be entered explicitly (even the filters are present in the Scandinavian Runic-text Database ID (P1261) discussion!).Macuser (talk) 18:18, 14 November 2019 (UTC)
- @Macuser: I think in this case the answer is that you should add an item for U 97 to Wikidata. U 97 fulfils the requirements of d:Wikidata:Notability in that it is a clearly identifiable ... material entity, and it can be described using serious and publicly available references, even if no project yet has an article about it. --bjh21 (talk) 16:52, 14 November 2019 (UTC)
- @Bjh21: , thank you for you answer. However, it does not achieve the point: it says, that File:Sundby_U_81_rättvänd.jpeg depicts runestone U 81. If I continue like that, File:Runinskrift U90, teckning av Johan Hadorph och Johan Leitz, 1682.jpg depicts Q10710106, File:Upplands_runinskrift_419.jpg depicts Upplands runinskrifter 419 and File:U 97, Collectaneum Monumentale Runicum.jpg depicts NOTHING, because there is nowhere a page or data element for U 97. The idea behind property is to add a systematic classification, isn't it? As if I want to create an article, I can easily find illustration, so it should be possible to use for U 97 too. Macuser (talk) 15:45, 14 November 2019 (UTC)
"Depicts" vs. "has quality"
Would someone with more expertise than I on structured data please look in on Commons:Village pump#"Has quality"? - Jmabel ! talk 16:17, 11 November 2019 (UTC)
- E.g. is there a structured data ontology one pager tutorial sheet? I'm going to look this up so if I find it I will post here. Shameran81 (talk) 18:13, 11 November 2019 (UTC)
- Modeling is still under discussion, see Commons:Structured data/Modeling for more information and to participate. If a community member wants to create a simple guide to help others in the community, that'd be welcome for certain. Keegan (WMF) (talk) 19:13, 14 November 2019 (UTC)
- E.g. is there a structured data ontology one pager tutorial sheet? I'm going to look this up so if I find it I will post here. Shameran81 (talk) 18:13, 11 November 2019 (UTC)
Issue displaying Structured Data on Wikimedia Commons
Out of laziness I'm copying from https://commons.m.wikimedia.org/w/index.php?title=Commons:Village_pump/Technical&oldid=374807186#I_can't_see_any_structured_data
"For about a week or two (2) weeks I have not been able to see any Structured Data on Wikimedia Commons (SDC) content, please see these screenshots:
-
 This is a screenshot on how it influences my "Desktop" view.
This is a screenshot on how it influences my "Desktop" view. -
 This is a screenshot on how it influences my "Desktop" view.
This is a screenshot on how it influences my "Desktop" view. -
 This is a screenshot on how it influences my "Mobile" view.
This is a screenshot on how it influences my "Mobile" view. -
 This is a screenshot on how it influences my "Mobile" view.
This is a screenshot on how it influences my "Mobile" view.
_01.png)
_02.png)
_03.png)
_04.png)
_jpg_-_Wikimedia_Commons.png){kind=link}
{kind=link}
_-_S%C3%A8te_02.jpg&action=history){kind=link}
_02.jpg&diff=334301000&oldid=334297632&diffmode=source){kind=link}
_02.jpg&diff=334301019&oldid=334301000&diffmode=source){kind=link}
_02.jpg?action=info){kind=link}
{kind=link}
![[1]](https://commons.wikimedia.org/w/index.php?title=File:Hylotelephium_telephium_subsp._telephium_Rozchodnikowiec_purpurowy_2018-08-12_01.jpg&diff=334640979&oldid=334637633){kind=link}
_-_IRON_2_Cash,_Rev._Tong_%26_1._(S863)_-_Scott_Semans.jpg){kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
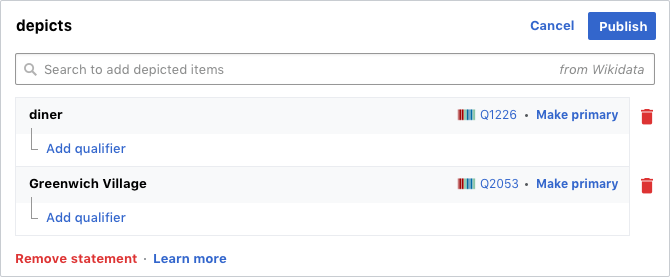{kind=link}
![[14]](https://test-commons.wikimedia.org/wiki/File:Mobile-wikipedia-page-issues.PNG){kind=link}
![[15]](https://test-commons.wikimedia.org/wiki/File:Godward_Idleness_1900-dupe!.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[16]](https://commons.wikimedia.org/w/index.php?title=File:Charles_Du_Fresne,_Seigneur_Du_Cange_-_Imagines_philologorum.jpg&diff=next&oldid=347998182){kind=link}
![[17]](https://commons.wikimedia.org/w/index.php?title=File:Captive_Portal.png&diff=prev&oldid=343666146){kind=link}
![[18]](https://commons.wikimedia.org/w/index.php?title=File:Solar-Testfeld_Widderstall.jpg&diff=prev&oldid=348184089){kind=link}
![[19]](https://commons.wikimedia.org/w/index.php?title=File:Flag_of_Switzerland_(Pantone).svg&diff=prev&oldid=347632797){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
![[22]](https://test-commons.wikimedia.org/wiki/File:Verleihung_Konrad-Adenauer-Preis_der_Stadt_K%C3%B6ln_2015_an_Vitali_Klitschko-7686a.jpg){kind=link}
![[23]](https://test-commons.wikimedia.org/wiki/File:Broadcom_BCM92070MD_-_BCM20702-2427a.jpg){kind=link}
.JPG&oldid=360170768){kind=link}
.JPG){kind=link}
{kind=link}
{kind=link}
{kind=link}
_01.jpg&diff=361198378&oldid=353952695&diffmode=source){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
As y'all can see I can't see either file captions or depicts. This issue has been affecting me for quite some time, but I can still add Structured Data using the MediaWiki Upload Wizard but after the file is uploaded I can't. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 05:20, 28 October 2019 (UTC)
- Addendum, for context I use Microsoft Edge as my browser and my device is a Microsoft Lumia 950 XL phablet with Microsoft's Windows 10 Mobile operating system. I haven't checked this issue on my Google's Android device yet. I have deleted cookies several times and this also seems to affect me in incognito mode. --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 05:24, 28 October 2019 (UTC)
- I can reproduce this on a Microsoft Phone Microsoft recently has discontinued support for but not on Edge Desktop. -- Rillke(q?) 00:43, 3 November 2019 (UTC)"
I have attempted to reproduce this on a few other devices, it does appear on my Microsoft Lumia 530 and Nokia Lumia 720 Dual SIM, but not on my Elephone P8 Mini, which runs Google's Android operating system or on my wife's Samsung Galaxy Tab. Can someone please attempt to reproduce it using Microsoft Edge or Microsoft Internet Explorer on the desktop? --Donald Trung 『徵國單』 (No Fake News 💬) (WikiProject Numismatics 💴) (Articles 📚) 19:45, 11 November 2019 (UTC)
- I'm checking to see if there's anything known about this. Keegan (WMF) (talk) 17:07, 14 November 2019 (UTC)
New tool and user script to show relevant areas of “depicts” statements

depicts (P180) statements can have relative position within image (P2677) qualifiers to indicate where in a file the object is depicted. To visualize and edit those qualifiers, I built the Wikidata Image Positions tool a while ago, and for Wikidata’s seventh birthday, I added support for Structured Data on Commons to it. (This has been live for some weeks and you may have seen it elsewhere, I just never got around to announcing it here.) I also wrote a user script that shows the same area indicators directly on Commons: see § User script for installation instructions, and this image for an example where you can see it in action.
{kind=link}
This is in some ways pretty similar to ImageAnnotator, and I imagine this user script is not the end of the road: perhaps it will gain editing capabilities (for the moment, you still need to go to the tool for that), or ImageAnnotator will gain Structured Data on Commons support and absorb the user script’s functionality. But for now, here it is, and I hope you find it useful. --Lucas Werkmeister (talk) 19:17, 17 November 2019 (UTC)
- ImageAnnotator is unfortunately CC-BY-SA-3.0 and GFDL licensed. But maybe it's passible to harvest the coordinates, if the names matches the Structured Data? - Premeditated (talk) 07:03, 18 November 2019 (UTC)
SPARQL to get items that have no P18 despite being used in "depicts" statements
I wrote the following SPARQL query:
SELECT ?wikidataItem ?commonsItem
WHERE
{
?commonsItem wdt:P180 ?wikidataItem.
MINUS { ?wikidataItem wdt:P18 ?image }
}
Per the MINUS condition, I thought it would give me only wikidata items that have no image.
Surprise: The first item it gives me is http://www.wikidata.org/entity/Q65587 which has a P18 image.
What am I missing? Thanks! Syced (talk) 13:04, 11 November 2019 (UTC)
- BTW, will there will be SPARQL for commons?--Juandev (talk) 10:36, 13 November 2019 (UTC)
- It is already available, see my "Run it" link. Syced (talk) 10:34, 22 November 2019 (UTC)
Original images inheriting structured data from a crop of it
It would be good if any Wikidata items added to the structured data for cropped images on Commons as "depicts" were automatically inherited by the original uncropped image (although probably not qualifiers, eg "prominent"). Does, can or should this happen? Quilt Phase (talk) 06:45, 18 November 2019 (UTC)
- If it's a crop, wouldn't it depict only part of it? Jura1 (talk) 23:16, 21 November 2019 (UTC)
- @Jura1: you may want to reread what Quilt Phase wrote. They are saying that if the crop depicts something, then the original must also depict that, although possibly inter alia and less prominently. - Jmabel ! talk 01:41, 22 November 2019 (UTC)
- Good point: yes, it's "by" not "from". It's possible to query both at once if the crop uses extracted from (P7009). Jura1 (talk) 10:17, 22 November 2019 (UTC)
- @Jura1: you may want to reread what Quilt Phase wrote. They are saying that if the crop depicts something, then the original must also depict that, although possibly inter alia and less prominently. - Jmabel ! talk 01:41, 22 November 2019 (UTC)
Revamp of general information pages
Hello everyone! As quite a few functionalities of SDC are now deployed, I was thinking it may be good to revamp our information portal a bit, and put documentation on using SDC at the forefront. I have started with a complete rewrite of the SDC 'home page' - see this draft in my user space. Does this make sense? What suggestions do you have? By all means, feel free to edit that page directly, and all comments are welcome. Cheers, SandraF (WMF) (talk) 15:29, 15 November 2019 (UTC)
- I received some internal feedback on the updated page, but no on wiki feedback. I consider that a good sign ;-) and will move the new text now. However, please everyone, feel free to update the page as much as you want - it belongs to all of us. Cheers! SandraF (WMF) (talk) 09:26, 21 November 2019 (UTC)
- Looks good. Now we really should start put content on Commons:Statements. --GPSLeo (talk) 10:26, 21 November 2019 (UTC)
- Agreed... I think it would also be good to link to Commons:Structured data/Modeling from there, because I notice that so many people ask me questions like 'I have this specific file; now what structured data should I add to it?' ;-) Let us know if Keegan and I can help with anything there. SandraF (WMF) (talk) 13:29, 21 November 2019 (UTC)
- @SandraF (WMF): Maybe also add the tool Wikidata Image Positions? - Premeditated (talk) 08:05, 24 November 2019 (UTC)
- Looks good. Now we really should start put content on Commons:Statements. --GPSLeo (talk) 10:26, 21 November 2019 (UTC)
Podcast on structured data
During the Wiki Techstorm I interviewed User:Spinster and it turned out to be a short introduction to Structured Data on Commons. You can listen to the podcast here: . Ainali (talk) 20:57, 30 November 2019 (UTC)
Blog posts about GLAM and Structured data
Hello all! In the upcoming weeks, there will be a new small series of blog posts on Wikimedia Space, about the GLAM pilot projects (oops, that page needs a good update). Two posts have already been published:
- Introducing ISA - a cool tool for adding structured data on Commons - about the ISA Tool, written by Isla Haddow-Flood
- How we helped a small art museum to increase the impact of its collections, with Wikimedia projects and structured data - about adding structured data to files from a small art collection.
I expect four more posts in the coming weeks before the Christmas holidays. Will keep you in the loop. Comments and questions very welcome. Greetings, SandraF (WMF) (talk) 11:02, 5 December 2019 (UTC)
- Blogs abound, there will also be posts about Computer-aided tagging and Lua support. Keegan (WMF) (talk) 18:29, 5 December 2019 (UTC)
Interface to Structured data
I personally am very used to Wikidata way of presenting structured data. Any chance for alternative skin that mimics wikidata or extra tab with wikidata-like display of ALL properties currently stored in Structured data? I also think it would be nice if we could display the M-ID or entity ID of each structured data page. Those options should be optional and not activated by default, but it would make my life much easier. --Jarekt (talk) 14:43, 18 November 2019 (UTC)
- +1 Jheald (talk) 17:28, 21 November 2019 (UTC)
- +1 I don't understand why the interface is re-implemented at all. Is there any reference to read why this decision has been made? Thanks, --Marsupium (talk) 16:35, 22 November 2019 (UTC)
- To let y'all know, I've alerted RIsler (WMF) about this to get at least brief background on the design direction decisions that were made until we get something longer published. There should be something for you soon. Keegan (WMF) (talk) 19:02, 27 November 2019 (UTC)
- Keegan (WMF), would it help if I create a task at phabricator? --Jarekt (talk) 15:34, 28 November 2019 (UTC)
- Tasks are always good. In theory, anyone can build a new interface for people who prefer Wikidata (or any other styling) for SDC using the API, even if the team can't get to it. Keegan (WMF) (talk) 16:24, 2 December 2019 (UTC)
- Done I created phabricator:T240093. --Jarekt (talk) 05:21, 8 December 2019 (UTC)
- Tasks are always good. In theory, anyone can build a new interface for people who prefer Wikidata (or any other styling) for SDC using the API, even if the team can't get to it. Keegan (WMF) (talk) 16:24, 2 December 2019 (UTC)
- Keegan (WMF), would it help if I create a task at phabricator? --Jarekt (talk) 15:34, 28 November 2019 (UTC)
- To let y'all know, I've alerted RIsler (WMF) about this to get at least brief background on the design direction decisions that were made until we get something longer published. There should be something for you soon. Keegan (WMF) (talk) 19:02, 27 November 2019 (UTC)
Suggestions for https://sdcquery.wmflabs.org/#DESCRIBE%20sdc%3AM40538870
Good to see this is finally taking off!
Just a few suggestions:
- I'd drop "schema:caption" as "rdfs:label" includes the same information
- It's unclear what the two triples
schema:dateModifiedandwikibase:timestampare for. I suppose one would be sufficient. - There are also two triples with
schema:versionandrdf:type. Similarly one of each should do. - sdc:M40538870 currently links to http://commons.wikimedia.org/entity/M40538870 . This currently leads nowhere
- there is no link to the file itself included. Ideally this would be in both a readable format (as here after File:) and also in the same format as on Wikidata query server (which isn't easily decodable)
Supposedly some of this is already somewhere in the pipeline. Jura1 (talk) 13:11, 12 November 2019 (UTC)
- Thanks for the feedback. Yes, there are some things that still need worked out. I'll keep the community posted as this rolls out of beta at some point. Keegan (WMF) (talk) 20:46, 13 November 2019 (UTC)
- Is there place were we can read up on it? Otherwise a short comment on the five points would help: What is a bug, what's a planned feature, what isn't planned? Jura1 (talk) 00:00, 14 November 2019 (UTC)
- I'm not sure, I'm trying to find out. The query project is not being developed by the Structured Data team, so I have little internal insight into your questions at the moment. I'll get back to you with more when I know more. Keegan (WMF) (talk) 17:06, 14 November 2019 (UTC)
- @Keegan (WMF): #5 seems to be most important. Jura1 (talk) 11:14, 11 December 2019 (UTC)
- I'm not sure, I'm trying to find out. The query project is not being developed by the Structured Data team, so I have little internal insight into your questions at the moment. I'll get back to you with more when I know more. Keegan (WMF) (talk) 17:06, 14 November 2019 (UTC)
- Is there place were we can read up on it? Otherwise a short comment on the five points would help: What is a bug, what's a planned feature, what isn't planned? Jura1 (talk) 00:00, 14 November 2019 (UTC)
- Clicking 3 times now gets one to the image. A workaround for #4. Jura1 (talk) 05:19, 14 December 2019 (UTC)
Special:SuggestedTags
Special:SuggestedTags, the page for accessing the computer-aided tagging tool, is now live for all auto-confirmed, logged-in users. Please leave feedback on the talk page. Keegan (WMF) (talk) 22:23, 11 December 2019 (UTC)
- Some lose feedback on the tagging: It does sometimes show duplicate of values like "fish" two times. A "+" icon would been appreciated to add even more than what the "computer" is seeing. Maybe also some suggestions from the name of the file could be implemented? Example on the image File:Spider on fence decoration.jpg it suggest: costume accessory, art of sculpture, flower, art, and plant. - Premeditated (talk) 14:54, 14 December 2019 (UTC)
{kind=link}
Problems with QuickStatements2 when interacting with SDC
QuickStatements (QS) provided by User:Magnus Manske is my tool of choose when doing batch additions to Wikidata. QS allows addition of statements to SDC, however I am running into multiple errors and limitations:
- can't remove statements
- I tried to execute few thousand statements like
-M396270 P7482 Q66458942after I discovered that statements, like source of file (P7482)=original creation by uploader (Q66458942), I added to files using {{Own}}, was not correct since the listed author is not the same as the uploader. See error report.
- I tried to execute few thousand statements like
- can't add statements with qualifiers (some or all)
- I tried to add statements equivalent to {{PD-Art}} using QS command
M84067505 P6216 Q19652 P459 Q79719208 P1001 Q80258411 P6243 Q3630741 P518 Q843958. Unfortunately the base statement is added but the qualifiers are not (Error "“Base statement not found”"). See error report.
- I tried to add statements equivalent to {{PD-Art}} using QS command
- can't communicate with QS through URL
- Much of metadata transfer from Commons to Wikidata is done through URLs, see d:Help:QuickStatements#Running_QuickStatements_through_URL. Similar interface is not available for SDC.